What AI gets wrong about your site, and why it’s not your fault: meet llms.txt
AI tools are everywhere — from chatbots that answer customer questions to language models that summarize everything from documentation to legal text. But if you’ve ever asked a model like ChatGPT to explain your site, your product, or your API, the results might not feel quite right. In fact, sometimes they’re way off. And no, that’s not your fault.
The disconnect between websites and LLMs
Large language models (LLMs) like ChatGPT, Claude, or Gemini are trained to understand a wide range of content. But when they try to interpret your website at runtime, that is, when someone is actively asking them a question, they run into a few core problems:
- HTML is noisy. Navigation bars, cookie banners, modal popups, and analytics scripts clutter the page.
- Context windows are limited. Most websites are too large for an LLM to process all at once.
- Important details are spread across multiple pages or hidden in tables, code blocks, or comments.
- Markdown docs may exist, but the model often can’t locate them, or even know they exist.
So, when you ask an AI tool to “explain what this company does” or “summarize this library API”, it often gets stuck. It either skips key context or grabs the wrong signals from cluttered markup.
It’s not bad intent; it’s a design limitation.
Why it’s not your SEO’s fault, either
You’ve probably invested time and effort into search engine optimization. Maybe your robots.txt and sitemap.xml are in place. You’ve got meta tags, structured data, and clean internal links. Good, but LLMs don’t always work like Google.
Traditional SEO helps your site get found. However, it doesn’t guarantee that AI tools will understand what a human user would. That’s where a new proposal comes in.
Meet llms.txt: A simple way to help AI understand your site
A growing number of developers and AI researchers are adopting a lightweight, human-readable standard called llms.txt.
What is llms.txt?
llms.txt is a plain Markdown file placed at the root of your site that provides language models with a summary of your project and direct links to clean, LLM-readable versions of important pages. It’s designed for inference-time use, helping AI tools quickly understand a site’s structure, purpose, and content without relying on cluttered HTML or metadata intended for search engines.
What it does:
- Gives a short summary of your site or project
- Links to clean, LLM-ready Markdown versions of key pages
- Helps AI tools find exactly what matters, without parsing messy HTML
Is it widely supported? Not yet
Right now, no major LLM provider officially supports llms.txt. Tools like GPTBot (OpenAI), Claude (Anthropic), and Google’s AI crawlers don’t reference or follow it as part of their crawling behavior. Some companies like Anthropic publish llms.txt files themselves, but there’s no evidence that any crawler is actively using them in retrieval or training.
Still, it’s a low-effort, no-risk addition that helps prepare your site for a future where structured LLM access becomes more standardized. And LLM-facing tools, or even your own AI agents, can make use of it today.
Example use cases:
- A dev library links to .md-formatted API docs and usage examples.
- A university site highlights course descriptions and academic policies.
- A personal blog offers a simplified timeline of key projects or topics.
You control the content and the structure. LLMs benefit from curated, LLM-aware context. And users asking questions about your site get better answers.
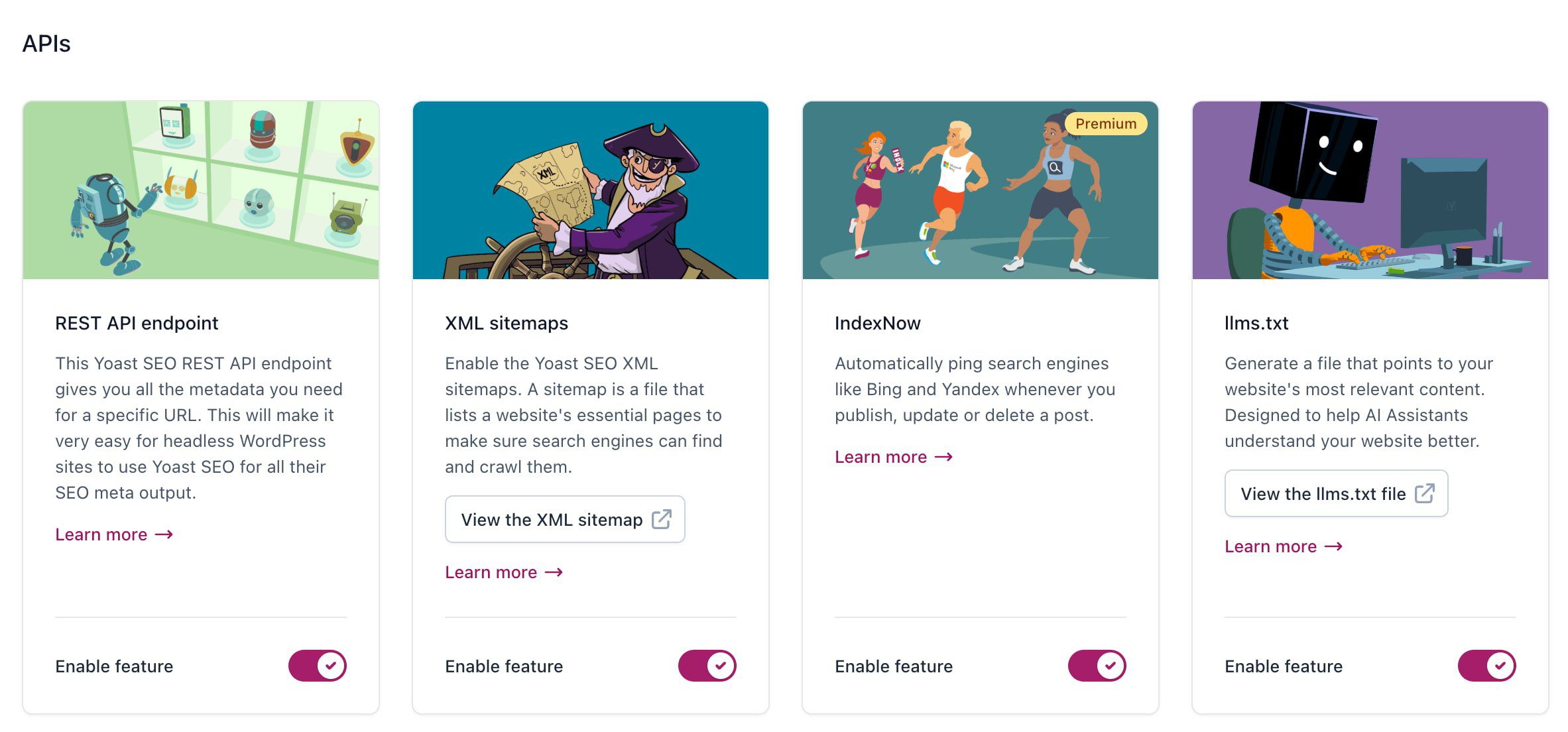
Using our Yoast SEO plugin?
If you’re already using our Yoast SEO (free or Premium) plugin, generating a llms.txt file is easy. Just enable the feature in your settings, and the plugin will automatically create and serve a complete llms.txt file for your site. You can view it anytime at yourdomain.com/llms.txt.
Get Yoast SEO Premium
Unlock powerful SEO insights with our Premium plugin, including advanced content features, AI optimization tools, and real-time data built for the next generation of search.
An LLM-friendly web isn’t the same as a Google-friendly web
This doesn’t replace SEO. Think of llms.txt as a companion to robots.txt. It tells AI bots: “Here’s the good stuff. Skip the noise.”
Sitemaps help crawlers find everything. llms.txt tells LLMs what to focus on.
It’s especially useful for:
- Developers and open-source maintainers
- Product marketers looking to reduce support load
- Teams that want chatbots to pull answers from docs, not guess
You don’t need a new CMS or tech stack
All this requires is creating two things:
- A basic llms.txt file in Markdown
- Ideally, you’d also have Markdown versions (.html.md) of key pages included alongside the originals, with the same URL plus .md added.
No new tools, plugins, or frameworks needed, although some ecosystems are already adding support.
Here’s an example of a file automatically built by Yoast SEO, as it has an llms.txt generator built in:
Generated by Yoast SEO v25.3, this is an llms.txt file, meant for consumption by LLMs. This is the [sitemap](https://everydayimtravelling.com/sitemap_index.xml) of this website.
# everydayimtravelling.com: Stories from our travels
## Posts
- [Test video](https://everydayimtravelling.com/test-video/)
- [A Journey Through Portugal’s Wine Country: A Suggested Wine Tour Route](https://everydayimtravelling.com/a-wine-tour-through-portugal/)
- [Travel essentials for backpackers FAQ](https://everydayimtravelling.com/travel-essentials-for-backpackers-faq/)
## Pages
- [Checkout](https://everydayimtravelling.com/checkout/)
- [Contact us](https://everydayimtravelling.com/contact-us/)
- [How we started this blog](https://everydayimtravelling.com/pagina-harry-potter/)
- [My account](https://everydayimtravelling.com/my-account/)
- [Cart](https://everydayimtravelling.com/cart/)
## Categories
- [Europe](https://everydayimtravelling.com/category/europe/)
- [Asia](https://everydayimtravelling.com/category/asia/)
- [South America](https://everydayimtravelling.com/category/south-america/)
- [Food](https://everydayimtravelling.com/category/food/)
- [Western Europe](https://everydayimtravelling.com/category/europe/west-europe/)
## Tags
- [Budget](https://everydayimtravelling.com/tag/budget/) Helping AI help you
So, if AI is misinterpreting your website, producing erroneous summaries, or skipping critical content, there’s a reason, and it’s fixable.
It’s not always your copy. Not your design or your metadata. It’s just that these language tools need a little guidance. In the future, llms.txt could be the way to give it to them, and you do so on your terms.
Do you need help creating an llms.txt file or converting your existing content to Markdown for LLMs? Yoast SEO can automatically generate an llms.txt file for you.