From large language models (LLMs) to reasoning agents, today’s AI tools bring unprecedented computational demands. Trillion-parameter models, workloads running on-device, and swarms of agents collaborating to complete tasks all require a new paradigm of computing to become truly seamless and ubiquitous.
First, technical progress in hardware and silicon design is critical to pushing the boundaries of compute. Second, advances in machine learning (ML) allow AI systems to achieve increased efficiency with smaller computational demands. Finally, the integration, orchestration, and adoption of AI into applications, devices, and systems is crucial to delivering tangible impact and value.
Silicon’s mid-life crisis
AI has evolved from classical ML to deep learning to generative AI. The most recent chapter, which took AI mainstream, hinges on two phases—training and inference—that are data and energy-intensive in terms of computation, data movement, and cooling. At the same time, Moore’s Law, which determines that the number of transistors on a chip doubles every two years, is reaching a physical and economic plateau.
For the last 40 years, silicon chips and digital technology have nudged each other forward—every step ahead in processing capability frees the imagination of innovators to envision new products, which require yet more power to run. That is happening at light speed in the AI age.
As models become more readily available, deployment at scale puts the spotlight on inference and the application of trained models for everyday use cases. This transition requires the appropriate hardware to handle inference tasks efficiently. Central processing units (CPUs) have managed general computing tasks for decades, but the broad adoption of ML introduced computational demands that stretched the capabilities of traditional CPUs. This has led to the adoption of graphics processing units (GPUs) and other accelerator chips for training complex neural networks, due to their parallel execution capabilities and high memory bandwidth that allow large-scale mathematical operations to be processed efficiently.
But CPUs are already the most widely deployed and can be companions to processors like GPUs and tensor processing units (TPUs). AI developers are also hesitant to adapt software to fit specialized or bespoke hardware, and they favor the consistency and ubiquity of CPUs. Chip designers are unlocking performance gains through optimized software tooling, adding novel processing features and data types specifically to serve ML workloads, integrating specialized units and accelerators, and advancing silicon chip innovations, including custom silicon. AI itself is a helpful aid for chip design, creating a positive feedback loop in which AI helps optimize the chips that it needs to run. These enhancements and strong software support mean modern CPUs are a good choice to handle a range of inference tasks.
Beyond silicon-based processors, disruptive technologies are emerging to address growing AI compute and data demands. The unicorn start-up Lightmatter, for instance, introduced photonic computing solutions that use light for data transmission to generate significant improvements in speed and energy efficiency. Quantum computing represents another promising area in AI hardware. While still years or even decades away, the integration of quantum computing with AI could further transform fields like drug discovery and genomics.
Understanding models and paradigms
The developments in ML theories and network architectures have significantly enhanced the efficiency and capabilities of AI models. Today, the industry is moving from monolithic models to agent-based systems characterized by smaller, specialized models that work together to complete tasks more efficiently at the edge—on devices like smartphones or modern vehicles. This allows them to extract increased performance gains, like faster model response times, from the same or even less compute.
Researchers have developed techniques, including few-shot learning, to train AI models using smaller datasets and fewer training iterations. AI systems can learn new tasks from a limited number of examples to reduce dependency on large datasets and lower energy demands. Optimization techniques like quantization, which lower the memory requirements by selectively reducing precision, are helping reduce model sizes without sacrificing performance.
New system architectures, like retrieval-augmented generation (RAG), have streamlined data access during both training and inference to reduce computational costs and overhead. The DeepSeek R1, an open source LLM, is a compelling example of how more output can be extracted using the same hardware. By applying reinforcement learning techniques in novel ways, R1 has achieved advanced reasoning capabilities while using far fewer computational resources in some contexts.
The integration of heterogeneous computing architectures, which combine various processing units like CPUs, GPUs, and specialized accelerators, has further optimized AI model performance. This approach allows for the efficient distribution of workloads across different hardware components to optimize computational throughput and energy efficiency based on the use case.
Orchestrating AI
As AI becomes an ambient capability humming in the background of many tasks and workflows, agents are taking charge and making decisions in real-world scenarios. These range from customer support to edge use cases, where multiple agents coordinate and handle localized tasks across devices.
With AI increasingly used in daily life, the role of user experiences becomes critical for mass adoption. Features like predictive text in touch keyboards, and adaptive gearboxes in vehicles, offer glimpses of AI as a vital enabler to improve technology interactions for users.
Edge processing is also accelerating the diffusion of AI into everyday applications, bringing computational capabilities closer to the source of data generation. Smart cameras, autonomous vehicles, and wearable technology now process information locally to reduce latency and improve efficiency. Advances in CPU design and energy-efficient chips have made it feasible to perform complex AI tasks on devices with limited power resources. This shift toward heterogeneous compute enhances the development of ambient intelligence, where interconnected devices create responsive environments that adapt to user needs.
Seamless AI naturally requires common standards, frameworks, and platforms to bring the industry together. Contemporary AI brings new risks. For instance, by adding more complex software and personalized experiences to consumer devices, it expands the attack surface for hackers, requiring stronger security at both the software and silicon levels, including cryptographic safeguards and transforming the trust model of compute environments.
More than 70% of respondents to a 2024 DarkTrace survey reported that AI-powered cyber threats significantly impact their organizations, while 60% say their organizations are not adequately prepared to defend against AI-powered attacks.
Collaboration is essential to forging common frameworks. Universities contribute foundational research, companies apply findings to develop practical solutions, and governments establish policies for ethical and responsible deployment. Organizations like Anthropic are setting industry standards by introducing frameworks, such as the Model Context Protocol, to unify the way developers connect AI systems with data. Arm is another leader in driving standards-based and open source initiatives, including ecosystem development to accelerate and harmonize the chiplet market, where chips are stacked together through common frameworks and standards. Arm also helps optimize open source AI frameworks and models for inference on the Arm compute platform, without needing customized tuning.
How far AI goes to becoming a general-purpose technology, like electricity or semiconductors, is being shaped by technical decisions taken today. Hardware-agnostic platforms, standards-based approaches, and continued incremental improvements to critical workhorses like CPUs, all help deliver the promise of AI as a seamless and silent capability for individuals and businesses alike. Open source contributions are also helpful in allowing a broader range of stakeholders to participate in AI advances. By sharing tools and knowledge, the community can cultivate innovation and help ensure that the benefits of AI are accessible to everyone, everywhere.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff.
This content was researched, designed, and written entirely by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
Sally Wilson is a lawyer turned craft entrepreneur. She’s also an involved mother who shares her business and passions with two kids. She says being a great mom doesn’t mean sacrificing who you are.
Sally launched Caterpillar Cross Stitch a decade ago from her home in England. Fast forward to 2025, and her company has 12 employees, selling cross-stitch supplies, courses, and events to customers worldwide.
In our recent conversation, she addressed early struggles, leadership lessons, global selling, and yes, raising kids. Our entire audio is embedded below. The transcript is condensed and edited for clarity.
Eric Bandholz: Tell us what you do.
Sally Wilson: I own an ecommerce company called Caterpillar Cross Stitch. We sell cross-stitch and crochet kits, subscriptions, and run events and classes — everything stitch-related — from our base near Birmingham, England.
I launched the business nearly 10 years ago after leaving a law career I hated. I took an ecommerce course and followed the advice: find a niche, a community, and a product people love.
I bootstrapped the business from the start, using savings and reinvesting carefully. I’d always wanted to work for myself, originally thinking I’d open a law firm, but I knew I needed something outside of law.
We now have a team of 12, including my husband, who joined the business three years ago. He was an engineer, but juggling two careers and raising kids was tough. On our 10th anniversary trip, I suggested we work together toward the same goal, and he joined soon after.
Working together wasn’t easy at first. There was conflict, especially since we discussed the business at all hours. But we set boundaries and now work in separate offices. I handle marketing and design, he runs operations. We’ve found a strong balance and deep respect for each other’s roles, which makes the business — and our marriage — work.
Bandholz: How have you adapted your leadership style with a larger team?
Wilson: I’ve learned that not everyone thinks or works like me. Early on, I assumed everyone approached things the same way, but I’ve come to appreciate that people are gifted differently. This awareness has made me more mindful and patient. Now, I focus on balancing my style with what works best for the team.
In the early days, I was more rigid, expecting people to fit my workflow. Coming from a law background, where I worked alone in a closed office, this was normal. But business, especially creative work, requires more interaction. Now, I’m much more intentional about how I communicate to bring out the best in others.
I try to make our employees feel safe sharing how they best receive communication. I’ve done a lot of reading, including recently exploring the distinction between feedback and criticism. Feedback, when delivered well, is a gift — it helps relationships and growth. But criticism, even if it sounds the same, can feel harsh and unhelpful if it lacks intention. It’s all about how it’s delivered.
I’m emotional and reactive by nature. Sometimes my husband and I go to bed angry — and that’s okay. Time offers perspective, and I’ve learned to own how my words or tone contribute to how something lands.
Bandholz: What’s your vision for the business?
Wilson: I want Caterpillar to be the brand women think of for crafting, especially in the U.S., Canada, Australia, New Zealand, and parts of Europe. Australia, in particular, is an exciting opportunity. The data shows a passionate, underserved community there that we haven’t fully tapped into yet. I’d love to give it more focus.
More broadly, I’m driven by the idea that you only get one life — so why not see what’s possible? That’s not about always winning or having the right answers. It’s about being resilient and reframing failure as learning. You either win or you grow. I’ve let go of fears and leaned into trusting myself: Even if I don’t know something now, I believe I can figure it out.
It comes down to grit, consistency, and a refusal to quit. That mindset has carried me this far, and it’s what I’ll continue to bring as we scale globally.
But my health and my children come first. For years, I sacrificed sleep, working until 2 a.m., and it took a toll. Now I’m more intentional. If I’m not well, the business suffers too.
As a mom, especially a female entrepreneur, there’s a lot of pressure to step back, work part-time, or choose a less demanding path.
But showing up fully for both my business and my kids is the example I want to set. I pick them up from school every day, attend nearly all their events, and I’m always available. They see how hard I work, how driven I am, and how lit up I get when things go well. I think that’s powerful for my daughter and son to see that passion.
Being a great mom doesn’t mean sacrificing who you are. I want them to grow up with open minds, strong values, and a real understanding of what it means to chase their purpose.
Redirects are essential to every website’s maintenance, and managing redirects becomes really challenging when SEO pros deal with websites containing millions of pages.
Examples of situations where you may need to implement redirects at scale:
An ecommerce site has a large number of products that are no longer sold.
Outdated pages of news publications are no longer relevant or lack historical value.
Listing directories that contain outdated listings.
Job boards where postings expire.
Why Is Redirecting At Scale Essential?
It can help improve user experience, consolidate rankings, and save crawl budget.
You might consider noindexing, but this does not stop Googlebot from crawling. It wastes crawl budget as the number of pages grows.
From a user experience perspective, landing on an outdated link is frustrating. For example, if a user lands on an outdated job listing, it’s better to send them to the closest match for an active job listing.
At Search Engine Journal, we get many 404 links from AI chatbots because of hallucinations as they invent URLs that never existed.
We use Google Analytics 4 and Google Search Console (and sometimes server logs) reports to extract those 404 pages and redirect them to the closest matching content based on article slug.
When chatbots cite us via 404 pages, and people keep coming through broken links, it is not a good user experience.
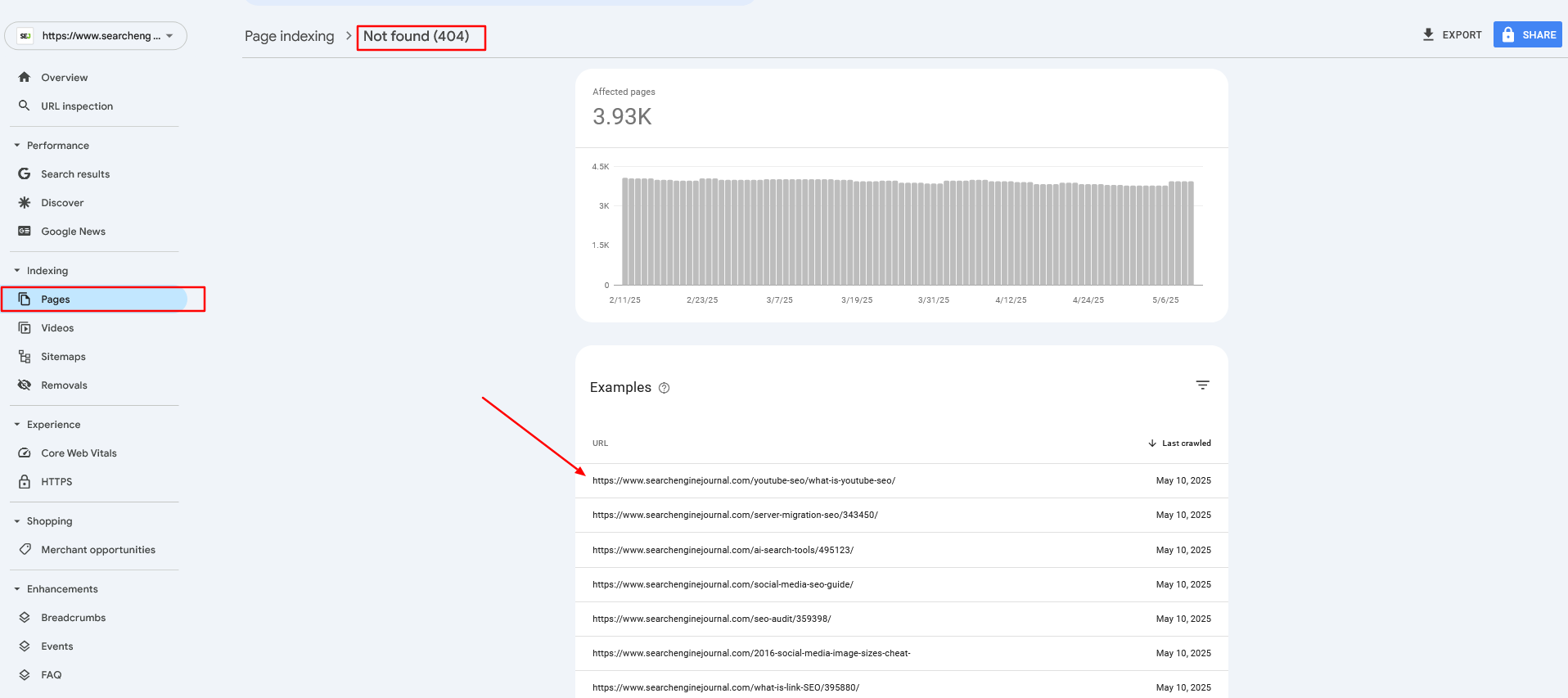
404 urls report in GSC, May 2025
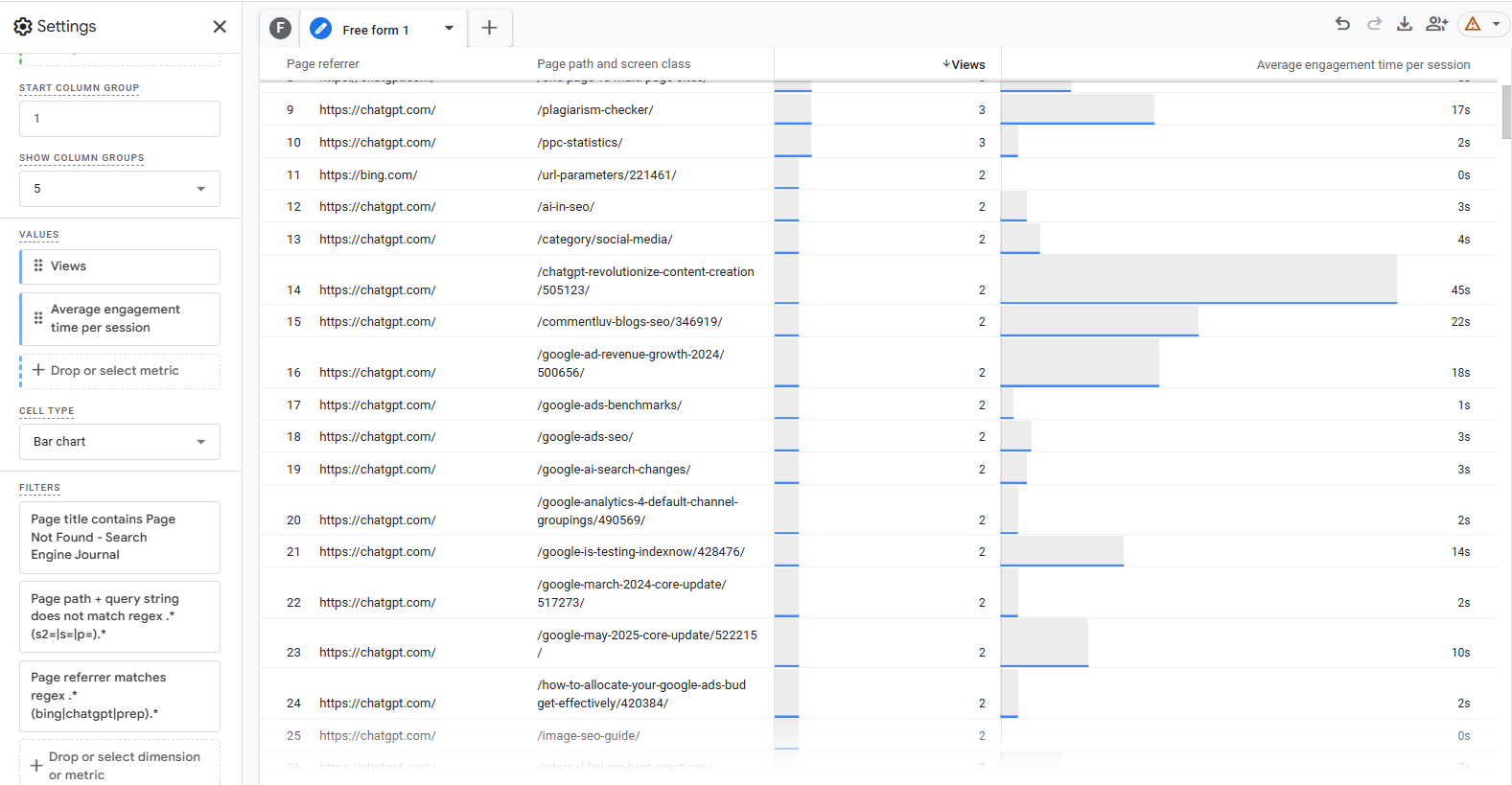
404 visits from AI chatbots, May 2025
Prepare Redirect Candidates
First of all, read this post to learn how to create a Pinecone vector database. (Please note that in this case, we used “primary_category” as a metadata key vs. “category.”)
To make this work, we assume that all your article vectors are already stored in the “article-index-vertex” database.
Prepare your redirect URLs in CSV format like in this sample file. That could be existing articles you’ve decided to prune or 404s from your search console reports or GA4.
Sample file with URLs to be redirected (Screenshot from Google Sheet, May 2025)
Optional “primary_category” information is metadata that exists with your articles’ Pinecone records when you created them and can be used to filter articles from the same category, enhancing accuracy further.
In case the title is missing, for example, in 404 URLs, the script will extract slug words from the URL and use them as input.
Generate Redirects Using Google Vertex AI
Download your Google API service credentials and rename them as “config.json,” upload the script below and a sample file to the same directory in Jupyter Lab, and run it.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import GoogleAPIError
from pinecone import Pinecone, PineconeException
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter).
# This is useful for interactive environments to show progress without cluttering the output.
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-vertex" # The name of the Pinecone index where article vectors are stored.
GOOGLE_CRED_PATH = "config.json" # Path to your Google Cloud service account credentials JSON file.
EMBEDDING_MODEL_ID = "text-embedding-005" # Identifier for the Vertex AI text embedding model to use.
TASK_TYPE = "RETRIEVAL_QUERY" # The task type for the embedding model. Try with RETRIEVAL_DOCUMENT vs RETRIEVAL_QUERY to see the difference.
# This influences how the embedding vector is generated for optimal retrieval.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List[int] = [] # Optional: List of years to filter Pinecone results by 'publish_year' metadata.
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (Vertex AI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE GOOGLE VERTEX AI ───────────────────────────────────────────────
# Set the GOOGLE_APPLICATION_CREDENTIALS environment variable to point to the
# service account key file. This allows the Google Cloud client libraries to
# authenticate automatically.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = GOOGLE_CRED_PATH
try:
# Load credentials from the specified JSON file.
credentials, project_id = load_credentials_from_file(GOOGLE_CRED_PATH)
# Initialize the Vertex AI client with the project ID and credentials.
# The location "us-central1" is specified for the AI Platform services.
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
logging.info("Vertex AI initialized.")
except Exception as e:
# Log an error if Vertex AI initialization fails and re-raise the exception
# to stop script execution, as it's a critical dependency.
logging.error(f"Failed to initialize Vertex AI: {e}")
raise
# Initialize the embedding model once globally.
# This is a crucial optimization for "Resource Management for Embedding Model".
# Loading the model takes time and resources; doing it once avoids repeated loading
# for every URL processed, significantly improving performance.
try:
GLOBAL_EMBEDDING_MODEL = TextEmbeddingModel.from_pretrained(EMBEDDING_MODEL_ID)
logging.info(f"Text Embedding Model '{EMBEDDING_MODEL_ID}' loaded.")
except Exception as e:
# Log an error if the embedding model fails to load and re-raise.
# The script cannot proceed without the embedding model.
logging.error(f"Failed to load Text Embedding Model: {e}")
raise
# ─── INITIALIZE PINECONE ──────────────────────────────────────────────────────
# Initialize the Pinecone client and connect to the specified index.
try:
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
1. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
2. Handling URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)[0].split('#', 1)[0]
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Determine if the original URL path ended with a trailing slash.
has_slash = urlparse(temp).path.endswith('/')
# Remove any trailing slash temporarily for consistent processing.
temp = temp.rstrip('/')
# Re-add the trailing slash if it was originally present.
return temp + ('/' if has_slash else '')
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = [seg for seg in path.split('/') if seg] # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for GoogleAPIError. This makes the embedding generation
# more resilient to transient issues like network problems or Vertex AI rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(GoogleAPIError), # Only retry if a GoogleAPIError occurs.
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional[List[float]]:
"""
Generates a vector embedding for the given text using the globally initialized
Vertex AI Text Embedding Model. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional[List[float]]: A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
# Use the globally initialized model to get embeddings.
# This is the "Resource Management for Embedding Model" optimization.
inp = TextEmbeddingInput(text, task_type=TASK_TYPE)
vectors = GLOBAL_EMBEDDING_MODEL.get_embeddings([inp], output_dimensionality=768)
return vectors[0].values # Return the embedding vector (list of floats).
except GoogleAPIError as e:
# Log a warning if a GoogleAPIError occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"Vertex AI error during embedding generation (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
except Exception as e:
# Catch any other unexpected exceptions during embedding generation.
logging.error(f"Unexpected error generating embedding: {e}")
return None # Return None for non-retryable or final failed attempts.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev["URL"].iloc[-1]
# Find the index of this last URL in the original input DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == last].tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs[0] + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List[Dict[str, Any]] = [] # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
category = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
slug = slug_from_url(raw_url)
if not slug:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context for embedding.")
continue
text = slug.replace('-', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except GoogleAPIError as e:
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding generated.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict[str, Any] = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = [c.strip() for c in category.split(",") if c.strip()]
if cats:
filt["primary_category"] = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt["publish_year"] = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt["id"] = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", []):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# 1. It exists (cid is not None).
# 2. It's not the original URL itself (to prevent self-redirects).
# 3. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode = 'a' if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
# clear_output(wait=True) # Uncomment if running in Jupyter and want to clear output
clear_output(wait=True)
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode = 'a' if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
You will see a test run with only five records, and you will see a new file called “redirect_map.csv,” which contains redirect suggestions.
Once you ensure the code runs smoothly, you can set the TEST_MODE boolean to true False and run the script for all your URLs.
Test run with only five records (Image from author, May 2025)
If the code stops and you resume, it picks up where it left off. It also checks each redirect it finds against the CSV file.
This check prevents selecting a database URL on the pruned list. Selecting such a URL could cause an infinite redirect loop.
Redirect candidates using Google Vertex AI’s task type RETRIEVAL_QUERY (Image from author, May 2025)
We can now take this redirect map and import it into our redirect manager in the content management system (CMS), and that’s it!
You can see how it managed to match the outdated 2013 news article “YouTube Retiring Video Responses on September 12” to the newer, highly relevant 2022 news article “YouTube Adopts Feature From TikTok – Reply To Comments With A Video.”
Also for “/what-is-eat/,” it found a match with “/google-eat/what-is-it/,” which is a 100% perfect match.
This is not just due to the power of Google Vertex LLM quality, but also the result of choosing the right parameters.
When I use “RETRIEVAL_DOCUMENT” as the task type when generating query vector embeddings for the YouTube news article shown above, it matches “YouTube Expands Community Posts to More Creators,” which is still relevant but not as good a match as the other one.
For “/what-is-eat/,” it matches the article “/reimagining-eeat-to-drive-higher-sales-and-search-visibility/545790/,” which is not as good as “/google-eat/what-is-it/.”
If you wanted to find redirect matches from your fresh articles pool, you can query Pinecone with one additional metadata filter, “publish_year,” if you have that metadata field in your Pinecone records, which I highly recommend creating.
In the code, it is a PUBLISH_YEAR_FILTER variable.
If you have publish_year metadata, you can set the years as array values, and it will pull articles published in the specified years.
Generate Redirects Using OpenAI’s Text Embeddings
Let’s do the same task with OpenAI’s “text-embedding-ada-002” model. The purpose is to show the difference in output from Google Vertex AI.
Simply create a new notebook file in the same directory, copy and paste this code, and run it.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from openai import OpenAI
from pinecone import Pinecone, PineconeException
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter)
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_API_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-ada" # The name of the Pinecone index where article vectors are stored.
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY" # Your API key for OpenAI. Replace with your actual key.
OPENAI_EMBEDDING_MODEL_ID = "text-embedding-ada-002" # Identifier for the OpenAI text embedding model to use.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List[int] = [] # Optional: List of years to filter Pinecone results by 'publish_year' metadata eg. [2024,2025].
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (OpenAI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE OPENAI CLIENT & PINECONE ───────────────────────────────────────
# Initialize the OpenAI client once globally. This handles resource management efficiently
# as the client object manages connections and authentication.
client = OpenAI(api_key=OPENAI_API_KEY)
try:
# Initialize the Pinecone client and connect to the specified index.
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
1. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
2. Handling URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)[0]
temp = temp.split('#', 1)[0]
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Determine if the original URL path ended with a trailing slash.
preserve_slash = temp.endswith('/')
# Strip trailing slash if not originally present.
if not preserve_slash:
temp = temp.rstrip('/')
return temp
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = [seg for seg in path.split('/') if seg] # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for OpenAI API errors. This makes the embedding generation
# more resilient to transient issues like network problems or API rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(Exception), # Retry on any Exception from OpenAI client (can be refined to openai.APIError if desired).
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional[List[float]]:
"""
Generate a vector embedding for the given text using OpenAI's text-embedding-ada-002
via the globally initialized OpenAI client. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional[List[float]]: A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
resp = client.embeddings.create( # Use the globally initialized OpenAI client to get embeddings.
model=OPENAI_EMBEDDING_MODEL_ID,
input=text
)
return resp.data[0].embedding # Return the embedding vector (list of floats).
except Exception as e:
# Log a warning if an OpenAI error occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"OpenAI embedding error (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev["URL"].iloc[-1]
# Find the index of this last URL in the original input DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == last].tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs[0] + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List[Dict[str, Any]] = [] # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
category = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
raw_slug = slug_from_url(raw_url)
if not raw_slug or len(raw_slug) < MIN_SLUG_LENGTH:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context.")
continue
text = raw_slug.replace('-', ' ').replace('_', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except Exception as e: # Catch any exception from generate_embedding after all retries.
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict[str, Any] = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = [c.strip() for c in category.split(",") if c.strip()]
if cats:
filt["primary_category"] = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt["publish_year"] = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt["id"] = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", []):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# 1. It exists (cid is not None).
# 2. It's not the original URL itself (to prevent self-redirects).
# 3. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode = 'a' if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
clear_output(wait=True) # Clear output in Jupyter for cleaner progress display.
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode = 'a' if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
While the quality of the output may be considered satisfactory, it falls short of the quality observed with Google Vertex AI.
Below in the table, you can see the difference in output quality.
When it comes to SEO, even though Google Vertex AI is three times more expensive than OpenAI’s model, I prefer to use Vertex.
The quality of the results is significantly higher. While you may incur a greater cost per unit of text processed, you benefit from the superior output quality, which directly saves valuable time on reviewing and validating the results.
From my experience, it costs about $0.04 to process 20,000 URLs using Google Vertex AI.
While it’s said to be more expensive, it’s still ridiculously cheap, and you shouldn’t worry if you’re dealing with tasks involving a few thousand URLs.
In the case of processing 1 million URLs, the projected price would be approximately $2.
If you still want a free method, use BERT and Llama models from Hugging Face to generate vector embeddings without paying a per-API-call fee.
The real cost comes from the compute power needed to run the models, and you must generate vector embeddings of all your articles in Pinecone or any other vector database using those models if you will be querying using vectors generated from BERT or Llama.
In Summary: AI Is Your Powerful Ally
AI enables you to scale your SEO or marketing efforts and automate the most tedious tasks.
This doesn’t replace your expertise. It’s designed to level up your skills and equip you to face challenges with greater capability, making the process more engaging and fun.
Mastering these tools is essential for success. I’m passionate about writing about this topic to help beginners learn and feel inspired.
As we move forward in this series, we will explore how to use Google Vertex AI for building an internal linking WordPress plugin.
Now that so many people use AI tools to create content, the questions about the credibility of those tools keep popping up. Can you really make AI-generated content and still meet Google’s E-E-A-T standards? Of course, the answer is yes, but there’s a limit to what you should let these tools do. Incorporating human insights in AI content can help uphold these standards.
Table of contents
AI helps you move faster and do more, but it can’t replace humans (yet). Do you want readers to trust your content and have it seen as a reliable source in traditional and AI-driven search? Then, you need to have people involved in every stage of the content production process.
In this article, we’ll discuss how to combine AI content with human editing to maintain experience, expertise, authoritativeness, and trustworthiness. But we’ll also discuss what happens if you don’t do that.
AI can help you start, but humans make it credible
AI tools like ChatGPT, Claude, and Gemini are trained on enormous data sets. These tools are very good at outlining topics, summarizing facts, and writing initial, high-level drafts of articles. However, the benefits stop there, and going much further will present a risk.
You must remember that AI does not have the intent, context, or experience in your industry. With all the low-quality content that’s spit out daily, that matters more than ever. Google, using the AI Overviews and AI Mode, is trying to surface content that shows real insights from real people.
But why does human involvement matter so much? AI is great, but it often misses nuances and is prone to add filler to your content. It’s also very good at oversimplifying topics. And, because of the way these systems were taught, they cannot pick up evolving best practices or shifts that happen in the real world.
What’s more, if you let the AI run wild, it can even produce content that’s factually wrong. These hallucinations are so confidently written that they sound like they are true, which makes it harder to detect misinformation.
What to do?
It’s fine to use AI, but use it to help you structure content or brainstorm, and don’t publish anything directly. Always use real editors with real knowledge of the topics to fact-check, correct the tone, and make sure the message is on point. This helps you improve trustworthiness in E-E-A-T. You should show that you wrote your content with good intent and oversight.
Remember that AI-generated content is not perfect. In fact, if you use it without having actual people working on it, it could hurt your visibility or reputation. In the end, this could hurt your business. But what are some of those risks when you over-rely on AI content?
False authority and misinformation
Search online and you’ll find many stories describing how AI wrote things that are just plain wrong. AI can misstate facts, make up statistics, and even come up with well-known experts that don’t exist. Publishing content like this in your brand’s name can damage your trustworthiness. What’s more, when search engines or visitors lose trust, it’s very hard to regain that.
Outdated or incomplete information
While there are many developments on this front, with grounding/RAG and LLMs connected to search, most models aren’t updated in real-time. These models often don’t know the latest insights until you specifically tell them. It’s easy to create outdated AI content when you don’t keep a very close eye on this.
Content redundancy
As you know, AI tools get data from existing sources, which will lead to content that looks a lot like content that’s already out there. If your content only repeats those same things, it’s very easy for search engines to ignore your site. It will be hard for Google to see your site as an authority on the topic.
Legal and compliance issues
There are many topics and industries that are very risky to publish on, for instance, the medical, financial, and legal fields. If your AI tool spits out incorrect advice and you publish without a human doing the fact-checking, your business could be found liable in court.
Trust breakdown with your audience
Remember that your readers are also developing a nose for AI content. When they sense that something sounds too generic or disconnected, they might move on to your competitor’s content, if that’s real. This will especially hurt industries that thrive on expertise and trust.
Add experience to strengthen the E’s
The biggest update of E-E-A-T was the addition of Experience. This is Google’s way of recognizing content created by people who have done or experienced what they wrote about. AI does not have this experience; real human beings do.
So, how do you do this? Be sure to include real stories from your team, clients, or projects, ideally with real names, results, and lessons learned. Give internal experts, such as engineers, consultants, or practitioners, a voice and direct input in your content. Don’t forget to interview team members and customers and use their perspectives in your content.
Giving your content more context can also make it stand out more, even in AI search. For instance, instead of simply writing “Solar panels reduce energy bills,” write, “After installing 28 commercial panels, our client in Portland, Oregon, cut annual costs by 35% — enough to pay off the system three years early.”
Make it easy for Google (and your audience) to trust you
Google’s systems, including AI Overviews and AI Mode, look at a lot more than just the words on your page. Google looks at all of the signals surrounding your business and yourself. These signals can help it understand if you and your content are trustworthy.
Improving your credibility signals for users and search engines starts by adding clear bylines with author bios that link to real credentials. This way, it’s easier to find out who is behind the content and why it makes sense for them to write about the topic. Support this with proper structured data, like schema markup for authors, products, reviews, and what else makes sense. Search engines use this to understand your content.
Remember to cite high-quality sources when referring to data instead of vague phrases like “research shows.” Also, set up a system to gather and use reader feedback so you can immediately fix things when they are unclear or plain wrong. Try everything to build and maintain trust while keeping content quality high.
Keep an eye on your Knowledge Graph. Try to get your brand and your experts or owners recognized as entities in search through structured data, Wikidata, Google Publisher Center, or by getting other citations. Think of authority and trust in E-E-A-T as something more visible, both to users and large language models (LLMs).
Always show who’s behind the content
AI content isn’t “real”. You, as a writer, are real. The best way to make your content real is by showing who wrote or reviewed it. Plus, you should show what makes them qualified to write about it. Transparency supports user trust and sets content apart from generic, anonymous posts.
Now, you don’t need a PhD from Harvard to be recognized as an expert for E-E-A-T, but you do need real-world, verifiable experience. In addition, you should publish author bios on your site with specific roles and industry backgrounds. You can also add an editorial or “reviewed by” credit for topics that your experts have fact-checked and edited.
Many big publishers have content guidelines and/or review policies that are available to read at any time. In those guidelines, you might have something simple, like what kind of disclosure you use when you’ve used AI to create a piece of content. That might be something simple like: “This article was drafted using generative AI and reviewed by [Editor Name], [Job Title] at [Company Name].”
Final thoughts
AI is a helpful tool for quickly generating content, but it shouldn’t replace real experiences, insights, or proper editing. Without the human element, you’ll miss the quality and trustworthiness needed to succeed with your content.
If you want your brand to be mentioned in AI search results and stand out amongst the competition, you need to make it clear that there are real people behind this content — real people with real knowledge and experiences.
Feel free to use AI where it can to speed up your work. But do make sure that the essential parts that your readers and search engines will value most are always human.
Google’s guidance on using AI-generated content (for quick reference) The bottom line is that using AI is fine as long as the final content is accurate, original, clearly labeled when necessary, and actually helpful to users.
Generative AI can support research and help structure original content—but using it to mass-produce low-value pages may violate Google’s spam policies, especially those related to scaled content abuse.
Content must meet Google’s Search Essentials and spam policy standards, even when AI tools are involved.
Focus on accuracy, originality, and value—this includes metadata like tags, meta descriptions, structured data, and image alt text.
Always ensure your structured data aligns with both general and feature-specific guidelines, and validate your markup to remain eligible for rich results.
Add transparency by explaining how the content was created—especially if automation was involved. This could include background details and appropriate image metadata.
Ecommerce sites must follow Google Merchant Center’s policies, including correctly tagging AI-generated product data and images (e.g., using IPTC metadata).
Review Search Quality Rater Guidelines sections 4.6.5 and 4.6.6 to understand how low-effort or unoriginal AI-generated content may be evaluated by Google’s systems.
Edwin is an experienced strategic content specialist. Before joining Yoast, he worked for a top-tier web design magazine, where he developed a keen understanding of how to create great content.
Reddit Karma has evolved far beyond a simple upvote tally.
It plays a central role in how content spreads, how trust is earned, and how visibility is gained, especially for brands.
With Reddit’s monetization programs and algorithmic surfacing now tightly tied to karma, it has become a built-in vetting system that shapes who gets seen, who gets trusted, and who gets access to Reddit’s most valuable communities.
If you’re a brand trying to earn influence on the platform, understanding karma isn’t optional anymore. It is the first filter between your content and the audience you’re hoping to reach.
The Early Days: More Than Just Numbers
When Reddit first introduced karma, it served as a basic measure of community contribution. Upvotes added points, downvotes subtracted them. But the system was always more nuanced than it looked.
What many users don’t realize is that karma isn’t handed out one-to-one with every upvote. Instead, it’s calculated through Reddit’s own formula, which takes into account things like:
Post Karma: Points earned from submitted content.
Comment Karma: Points from community interactions.
Awards and recognitions within the community.
The Rise Of Digital Influence
Times have changed, and karma’s influence has blown up.
Take users like mvea with over 32 million karma or TooShiftyForYou with nearly 27 million karma. Those aren’t just numbers. That kind of karma reflects reach, trust, and a track record of content that resonates with the community.
Erik Martin, Reddit’s former general manager, said it best: “Karma isn’t just about popularity anymore. It’s become a crucial factor in how information flows through online communities.”
How Karma Reflects Quality And Builds Trust
Reddit has steadily increased its focus on rewarding authentic engagement and meaningful participation.
The karma system, paired with subreddit-level thresholds, encourages users to contribute value before gaining access to certain spaces.
Many communities require users to meet minimum karma scores, often starting around 10 to 100 points, before posting. Some expert-driven or niche subs push that requirement much higher.
This isn’t just about moderation. It’s part of Reddit’s broader push to promote quality signals across the platform.
As Reddit expands monetization and leans into features like Reddit Answers and the Contributor Program, karma acts as a built-in filter for trust and relevance.
In a landscape filled with AI content, bots, and throwaway accounts, karma has also become a visible sign of authenticity.
When users see a high-karma profile, they are more likely to assume it belongs to a real person who has been around and contributed consistently.
Reddit CEO Steve Huffman called karma “an indicator of how valuable you are to the website,” and that credibility influences everything from content engagement to purchase decisions.
For brands, this shift raises the bar. One-off promotions and low-effort posts won’t work here.
Gaining traction requires real participation, a history of contribution, and a willingness to be part of the conversation, not just interrupt it.
Understanding Karma Tiers And How They Vary Across Communities
Reddit karma isn’t one-size-fits-all. Where you fall on the karma ladder says a lot about how active and trusted you are, but it also depends on the communities you engage with.
Here’s how karma levels typically break down:
New Users (0–50 karma): Still learning the ropes.
Casual Users (50–500 karma): In and out, posting occasionally.
Active Users (500–2,000 karma): Contributing regularly.
Experienced Users (2,000–10,000 karma): Posting with purpose.
Power Users (10,000–100,000 karma): Major voices in multiple subs.
Reddit Celebrities (100,000+ karma): The names you see everywhere.
The average Redditor sits around a few hundred karma, but that number means very different things depending on where you’re posting.
Smaller or niche communities may only require 30 to 100 karma to participate, while top-tier subreddits may set the bar at 1,000 or more.
And karma doesn’t grow at the same pace in every community. Educational subs like r/AskScience see users rack up karma 30% faster than general entertainment ones.
Regional subreddits also vary, often influenced by local behavior, cultural tone, or even language.
Understanding where you’re posting, and how that sub rewards contribution, makes a big difference in how fast your karma builds. This matters not just for individuals but for brands looking to enter the right communities in the right way.
Where Reddit’s Scoring System Falls Short, And How It’s Evolving
While karma opens doors, it’s not perfect. The system has its share of critics, and several long-standing issues continue to shape how people interact on the platform.
Here are some common pain points:
Karma Farming: Cash incentives have encouraged spammy content and attempts to game the system, including participation in karma-exchange subreddits that Reddit strictly discourages.
Echo Chambers: People fear posting unpopular opinions, leading to self-censorship and groupthink.
Opaque Math: Reddit doesn’t fully explain its karma algorithm, making it hard for users to understand what’s working.
Gatekeeping: New users face steep entry barriers, and users with negative karma may quietly lose access to many communities, even if it’s not visibly apparent.
To Reddit’s credit, they’re working on it. In recent years, the platform has rolled out updates aimed at making karma smarter and more meaningful.
Some of those innovations include:
Enhanced Post Insights: Metrics for views, votes, and engagement trends.
Potential for Paid Subreddit Access: Future features may tie karma to premium community perks.
Reddit is clearly investing in tools that make karma more than just a vanity metric. It’s becoming a core piece of how the platform works.
Turning Reddit Karma Into Real Rewards
Here’s where it gets interesting.
In September 2023, Reddit launched the Contributor Program. Suddenly, karma started converting into real money. Eligible users can cash in Reddit gold awards at the following rates:
Contributors (100–4,999 karma): Around $0.90 per gold.
Top Contributors (5,000+ karma): $1.00 per gold.
To join, users have to be 18+, based in the U.S. (international is coming), verify their ID, have a clean account, and hit the 1,000-gold payout threshold.
Reddit’s official language doesn’t sugarcoat it: “Yes, this means participating redditors can earn money from brightening someone’s day, sharing fascinating content, developing a helpful bot, or even sh*tposting.”
Oh, and during Reddit’s 2024 IPO? Users with 25,000 to 200,000 karma were invited to buy shares before the public through the Directed Shares Program. That’s a major shift from digital clout to financial opportunity.
What Karma Means For Brands On Reddit
For brands and creators, karma isn’t just a vanity metric anymore. It influences everything from visibility to credibility.
High-karma accounts are more likely to gain traction with both the community and Reddit’s algorithm. This opens doors to AMA opportunities, trusted conversations with subreddit moderators, and real community influence.
Brands that try to shortcut the process or rely on one-off promotions are unlikely to see results. Instead, success on Reddit requires long-term community engagement and an understanding of the culture.
When brands take the time to build a solid reputation, they gain more than just karma points. They earn access to communities that gate participation behind karma thresholds, build trust that can help manage reputational risks, and unlock insights by engaging with users on their terms.
High-karma brand accounts can:
Show up better in Reddit’s ranking system.
Build trust-based relationships with subreddit moderators.
Access communities with karma thresholds.
Manage crises more effectively.
Gather feedback and insights directly from target audiences.
Reddit Karma: How It Evolved And Where It’s Going
To understand where we are, it helps to know where we’ve been:
2005–2008: The Foundation Years
Karma launches alongside Reddit’s core voting system. It appeared on user profiles by 2008.
2009–2015: System Refinements
Algorithm changes reduce over-weighted posts. Subreddit-specific karma filters appear. The idea of “softcapping” surfaces.
2016–2020: Community Features
Karma gets more visible. Reddit experiments with crypto-tied karma in limited subs.
2021–2023: Monetization Foundation
Spam protection gets better. Gold system expands. The Contributor Program starts in September 2023.
2024–2025: Advanced Integration
Karma becomes a core part of Reddit’s AI tools and business model. Daily users hit 108.1 million.
In Q4 2024, Reddit turns its first profit as a public company, pointing directly to karma-driven engagement.
Looking forward, karma’s role is only getting bigger. We’re likely to see:
Global rollout of the Contributor Program.
Subreddit-specific karma scores.
Predictive analytics for content success.
Smarter AI surfacing based on karma history.
New monetization paths for high-karma users.
As Alexis Ohanian once said, “Better to post positive things about other people’s work and then let the good karma work for you.” It’s less about gaming the system and more about adding value consistently.
Reddit Karma’s Growing Role In The Platform
Reddit karma has officially outgrown its “internet points” status. It shapes how people trust, engage, and even spend money on the platform.
Whether you’re just lurking, posting regularly, or trying to build a brand presence, karma isn’t optional. It’s your reputation. It’s your access pass. It’s your potential paycheck.
If you’re just getting started and want to build up karma the right way, check out Reddit’s own guide and resources on how to earn karma through meaningful participation.
A great place to begin is r/NewToReddit, which has a helpful list of new-user-friendly communities that don’t have strict karma requirements.
These subreddits are intentionally welcoming to new users and don’t have strict karma or account age requirements, making them a smart starting point for anyone building up their Reddit presence.
As Reddit continues evolving, karma isn’t just a score. It is a signal of credibility, opportunity, and long-term value for anyone serious about building presence on the platform.
Circle, highlight, or tap anything you want to search.
You can identify objects, translate text, or learn about locations. The results appear right above the video. When you’re finished, just swipe down to continue watching.
Here’s an example of the interface:
Screenshot from: YouTube.com/CreatorInsider, May 2025.
The feature works with products, plants, animals, landmarks, and text. You can even translate captions in real-time. Some searches include AI Overviews that provide more detailed information about what you’re looking for.
Google shared an example in its announcement:
“If you’re watching a short filmed in a location that you want to visit, you can select a landmark to identify it and learn more about the destination’s culture and history.”
See a demonstration in the video below:
Important Limitations
There are some key restrictions. Google Lens won’t work on Shorts with YouTube Shopping affiliate tags or paid product promotions.
“Tagging a product via YouTube Shopping will disable the lens search.”
Search results only show organic content, meaning no ads will appear when you use Lens. Google also states that it doesn’t use facial recognition technology, although the system may display results for famous people when relevant.
The feature is only compatible with mobile devices (iOS and Android). Google says the beta is “starting to roll out to all viewers this week,” though it hasn’t shared specific dates for different regions.
What This Means For Marketers
This update presents several opportunities for content creators and marketers:
Visual elements in your Shorts can now boost engagement.
Travel and hospitality businesses receive free visibility when their locations feature in videos. Educational creators can benefit as viewers explore the topics presented in their content.
The ban on affiliate content poses a challenge. Creators who rely on YouTube Shopping must carefully consider their monetization strategies. They will need to find a balance between discoverable content and their revenue goals.
Looking Ahead
Google Lens in YouTube Shorts signals a shift in how people interact with video content. You can now search within videos, not just for them.
For marketers, this means visual elements matter more than ever. The objects, locations, and text in your videos are now searchable entry points.
The exclusion of monetized content also sets up an interesting dynamic. Creators must choose between affiliate revenue and visibility in visual search.
Start planning your Shorts with searchable moments in mind. Your viewers are about to become visual searchers.
Imagine: China deploys hundreds of thousands of autonomous drones in the air, on the sea, and under the water—all armed with explosive warheads or small missiles. These machines descend in a swarm toward military installations on Taiwan and nearby US bases, and over the course of a few hours, a single robotic blitzkrieg overwhelms the US Pacific force before it can even begin to fight back.
Maybe it sounds like a new Michael Bay movie, but it’s the scenario that keeps the chief technology officer of the US Army up at night.
“I’m hesitant to say it out loud so I don’t manifest it,” says Alex Miller, a longtime Army intelligence official who became the CTO to the Army’s chief of staff in 2023.
Even if World War III doesn’t break out in the South China Sea, every US military installation around the world is vulnerable to the same tactics—as are the militaries of every other country around the world. The proliferation of cheap drones means just about any group with the wherewithal to assemble and launch a swarm could wreak havoc, no expensive jets or massive missile installations required.
While the US has precision missiles that can shoot these drones down, they don’t always succeed: A drone attack killed three US soldiers and injured dozens more at a base in the Jordanian desert last year. And each American missile costs orders of magnitude more than its targets, which limits their supply; countering thousand-dollar drones with missiles that cost hundreds of thousands, or even millions, of dollars per shot can only work for so long, even with a defense budget that could reach a trillion dollars next year.
The US armed forces are now hunting for a solution—and they want it fast. Every branch of the service and a host of defense tech startups are testing out new weapons that promise to disable drones en masse. There are drones that slam into other drones like battering rams; drones that shoot out nets to ensnare quadcopter propellers; precision-guided Gatling guns that simply shoot drones out of the sky; electronic approaches, like GPS jammers and direct hacking tools; and lasers that melt holes clear through a target’s side.
Then there are the microwaves: high-powered electronic devices that push out kilowatts of power to zap the circuits of a drone as if it were the tinfoil you forgot to take off your leftovers when you heated them up.
That’s where Epirus comes in.
When I went to visit the HQ of this 185-person startup in Torrance, California, earlier this year, I got a behind-the-scenes look at its massive microwave, called Leonidas, which the US Army is already betting on as a cutting-edge anti-drone weapon. The Army awarded Epirus a $66 million contract in early 2023, topped that up with another $17 million last fall, and is currently deploying a handful of the systems for testing with US troops in the Middle East and the Pacific. (The Army won’t get into specifics on the location of the weapons in the Middle East but published a report of a live-fire test in the Philippines in early May.)
Up close, the Leonidas that Epirus built for the Army looks like a two-foot-thick slab of metal the size of a garage door stuck on a swivel mount. Pop the back cover, and you can see that the slab is filled with dozens of individual microwave amplifier units in a grid. Each is about the size of a safe-deposit box and built around a chip made of gallium nitride, a semiconductor that can survive much higher voltages and temperatures than the typical silicon.
Leonidas sits on top of a trailer that a standard-issue Army truck can tow, and when it is powered on, the company’s software tells the grid of amps and antennas to shape the electromagnetic waves they’re blasting out with a phased array, precisely overlapping the microwave signals to mold the energy into a focused beam. Instead of needing to physically point a gun or parabolic dish at each of a thousand incoming drones, the Leonidas can flick between them at the speed of software.
The Leonidas contains dozens of microwave amplifier units and can pivot to direct waves at incoming swarms of drones.
EPIRUS
Of course, this isn’t magic—there are practical limits on how much damage one array can do, and at what range—but the total effect could be described as an electromagnetic pulse emitter, a death ray for electronics, or a force field that could set up a protective barrier around military installations and drop drones the way a bug zapper fizzles a mob of mosquitoes.
I walked through the nonclassified sections of the Leonidas factory floor, where a cluster of engineers working on weaponeering—the military term for figuring out exactly how much of a weapon, be it high explosive or microwave beam, is necessary to achieve a desired effect—ran tests in a warren of smaller anechoic rooms. Inside, they shot individual microwave units at a broad range of commercial and military drones, cycling through waveforms and power levels to try to find the signal that could fry each one with maximum efficiency.
On a live video feed from inside one of these foam-padded rooms, I watched a quadcopter drone spin its propellers and then, once the microwave emitter turned on, instantly stop short—first the propeller on the front left and then the rest. A drone hit with a Leonidas beam doesn’t explode—it just falls.
Compared with the blast of a missile or the sizzle of a laser, it doesn’t look like much. But it could force enemies to come up with costlier ways of attacking that reduce the advantage of the drone swarm, and it could get around the inherent limitations of purely electronic or strictly physical defense systems. It could save lives.
Epirus CEO Andy Lowery, a tall guy with sparkplug energy and a rapid-fire southern Illinois twang, doesn’t shy away from talking big about his product. As he told me during my visit, Leonidas is intended to lead a last stand, like the Spartan from whom the microwave takes its name—in this case, against hordes of unmanned aerial vehicles, or UAVs. While the actual range of the Leonidas system is kept secret, Lowery says the Army is looking for a solution that can reliably stop drones within a few kilometers. He told me, “They would like our system to be the owner of that final layer—to get any squeakers, any leakers, anything like that.”
Now that they’ve told the world they “invented a force field,” Lowery added, the focus is on manufacturing at scale—before the drone swarms really start to descend or a nation with a major military decides to launch a new war. Before, in other words, Miller’s nightmare scenario becomes reality.
Why zap?
Miller remembers well when the danger of small weaponized drones first appeared on his radar. Reports of Islamic State fighters strapping grenades to the bottom of commercial DJI Phantom quadcopters first emerged in late 2016 during the Battle of Mosul. “I went, ‘Oh, this is going to be bad,’ because basically it’s an airborne IED at that point,” he says.
He’s tracked the danger as it’s built steadily since then, with advances in machine vision, AI coordination software, and suicide drone tactics only accelerating.
Then the war in Ukraine showed the world that cheap technology has fundamentally changed how warfare happens. We have watched in high-definition video how a cheap, off-the-shelf drone modified to carry a small bomb can be piloted directly into a faraway truck, tank, or group of troops to devastating effect. And larger suicide drones, also known as “loitering munitions,” can be produced for just tens of thousands of dollars and launched in massive salvos to hit soft targets or overwhelm more advanced military defenses through sheer numbers.
As a result, Miller, along with largeswaths of the Pentagon and DC policycircles, believes that the current US arsenal for defending against these weapons is just too expensive and the tools in too short supply to truly match the threat.
Just look at Yemen, a poor country where the Houthi military group has been under constant attack for the past decade. Armed with this new low-tech arsenal, in the past 18 months the rebel group has been able to bomb cargo ships and effectively disrupt global shipping in the Red Sea—part of an effort to apply pressure on Israel to stop its war in Gaza. The Houthis have also used missiles, suicide drones, and even drone boats to launch powerful attacks on US Navy ships sent to stop them.
The most successful defense tech firm selling anti-drone weapons to the US military right now is Anduril, the company started by Palmer Luckey, the inventor of the Oculus VR headset, and a crew of cofounders from Oculus and defense data giant Palantir. In just the past few months, the Marines have chosen Anduril for counter-drone contracts that could be worth nearly $850 million over the next decade, and the company has been working with Special Operations Command since 2022 on a counter-drone contract that could be worth nearly a billion dollars over a similar time frame. It’s unclear from the contracts what, exactly, Anduril is selling to each organization, but its weapons include electronic warfare jammers, jet-powered drone bombs, and propeller-driven Anvil drones designed to simply smash into enemy drones.
In this arsenal, the cheapest way to stop a swarm of drones is electronic warfare: jamming the GPS or radio signals used to pilot the machines. But the intense drone battles in Ukraine have advanced the art of jamming and counter-jamming close to the point of stalemate. As a result, anew state of the art is emerging: unjammable drones that operate autonomously by using onboard processors to navigate via internal maps and computer vision, or even drones connected with 20-kilometer-long filaments of fiber-optic cable for tethered control.
But unjammable doesn’t mean unzappable. Instead of using the scrambling method of a jammer, which employs an antenna to block the drone’s connection to a pilot or remote guidance system, the Leonidas microwave beam hits a drone body broadside. The energy finds its way into something electrical, whether the central flight controller or a tiny wire controlling a flap on a wing, to short-circuit whatever’s available. (The company also says that this targeted hit of energy allows birds and other wildlife to continuetomove safely.)
Tyler Miller, a senior systems engineer on Epirus’s weaponeering team, told me that they never know exactly which part of the target drone is going to go down first, but they’ve reliably seen the microwave signal get in somewhere to overload a circuit. “Based on the geometry and the way the wires are laid out,” he said, one of those wires is going to be the best path in. “Sometimes if we rotate the drone 90 degrees, you have a different motor go down first,” he added.
The team has even tried wrapping target drones in copper tape, which would theoretically provide shielding, only to find that the microwave still finds a way in through moving propeller shafts or antennas that need to remain exposed for the drone to fly.
EPIRUS
Leonidas also has an edge when it comes to downing a mass of drones at once. Physically hitting a drone out of the sky or lighting it up with a laser can be effective in situations where electronic warfare fails, but anti-drone drones can only take out one at a time, and lasers need to precisely aim and shoot. Epirus’s microwaves can damage everything in a roughly 60-degree arc from the Leonidas emitter simultaneously and keep on zapping and zapping; directed energy systems like this one never run out of ammo.
As for cost, each Army Leonidas unit currently runs in the “low eight figures,” Lowery told me. Defense contract pricing can be opaque, but Epirus delivered four units for its $66 million initial contract, giving a back-of-napkin price around $16.5 million each. For comparison, Stinger missiles from Raytheon, which soldiers shoot at enemy aircraft or drones from a shoulder-mounted launcher, cost hundreds of thousands of dollars a pop, meaning the Leonidas could start costing less (and keep shooting) after it downs the first wave of a swarm.
Raytheon’s radar, reversed
Epirus is part of a new wave of venture-capital-backed defense companies trying to change the way weapons are created—and the way the Pentagon buys them. The largest defense companies, firms like Raytheon, Boeing, Northrop Grumman, and Lockheed Martin, typically develop new weapons in response to research grants and cost-plus contracts, in which the US Department of Defense guarantees a certain profit margin to firms building products that match their laundry list of technical specifications. These programs have kept the military supplied with cutting-edge weapons for decades, but the results may be exquisite pieces of military machinery delivered years late and billions of dollars over budget.
Rather than building to minutely detailed specs, the new crop of military contractors aim to produce products on a quick time frame to solve a problem and then fine-tune them as they pitch to the military. The model, pioneered by Palantir and SpaceX, has since propelled companies like Anduril, Shield AI, and dozens of other smaller startups into the business of war as venture capital piles tens of billions of dollars into defense.
Like Anduril, Epirus has direct Palantir roots; it was cofounded by Joe Lonsdale, who also cofounded Palantir, and John Tenet, Lonsdale’s colleague at the time at his venture fund, 8VC. (Tenet, the son of former CIA director George Tenet, may have inspired the company’s name—the elder Tenet’s parents were born in the Epirus region in the northwest of Greece. But the company more often says it’s a reference to the pseudo-mythological Epirus Bow from the 2011 fantasy action movie Immortals, which never runs out of arrows.)
While Epirus is doing business in the new mode, its roots are in the old—specifically in Raytheon, a pioneer in the field of microwave technology. Cofounded by MIT professor Vannevar Bush in 1922, it manufactured vacuum tubes, like those found in old radios. But the company became synonymous with electronic defense during World War II, when Bush spun up a lab to develop early microwave radar technology invented by the British into a workable product, and Raytheon then began mass-producing microwave tubes—known as magnetrons—for the US war effort. By the end of the war in 1945, Raytheon was making 80% of the magnetrons powering Allied radar across the world.
From padded foam chambers at the Epirus HQ, Leonidas devices can be safely tested on drones.
EPIRUS
Large tubes remained the best way to emit high-power microwaves for more than half a century, handily outperforming silicon-based solid-state amplifiers. They’re still around—the microwave on your kitchen counter runs on a vacuum tube magnetron. But tubes have downsides: They’re hot, they’re big, and they require upkeep. (In fact, the other microwave drone zapper currently in the Pentagon pipeline, the Tactical High-power Operational Responder, or THOR, still relies on a physical vacuum tube. It’s reported to be effective at downing drones in tests but takes up a whole shipping container and needs a dish antenna to zap its targets.)
By the 2000s, new methods of building solid-state amplifiers out of materials like gallium nitride started to mature and were able to handle more power than silicon without melting or shorting out. The US Navy spent hundreds of millions of dollars on cutting-edge microwave contracts, one for a project at Raytheon called Next Generation Jammer—geared specifically toward designing a new way to make high-powered microwaves that work at extremely long distances.
Lowery, the Epirus CEO, began his career working on nuclear reactors on Navy aircraft carriers before he became the chief engineer for Next Generation Jammer at Raytheon in 2010. There, he and his team worked on a system that relied on many of the same fundamentals that now power the Leonidas—using the same type of amplifier material and antenna setup to fry the electronics of a small target at much closer range rather than disrupting the radar of a target hundreds of miles away.
The similarity is not a coincidence: Two engineers from Next Generation Jammer helped launch Epirus in 2018. Lowery—who by then was working at the augmented-reality startup RealWear, which makes industrial smart glasses—joined Epirus in 2021 to run product development and was asked to take the top spot as CEO in 2023, as Leonidas became a fully formed machine. Much of the founding team has since departed for other projects, but Raytheon still runs through the company’s collective CV: ex-Raytheon radar engineer Matt Markel started in January as the new CTO, and Epirus’s chief engineer for defense, its VP of engineering, its VP of operations, and a number of employees all have Raytheon roots as well.
Markel tells me that the Epirus way of working wouldn’t have flown at one of the big defense contractors: “They never would have tried spinning off the technology into a new application without a contract lined up.” The Epirus engineers saw the use case, raised money to start building Leonidas, and already had prototypes in the works before any military branch started awarding money to work on the project.
Waiting for the starting gun
On the wall of Lowery’s office are two mementos from testing days at an Army proving ground: a trophy wing from a larger drone, signed by the whole testing team, anda framed photo documenting the Leonidas’s carnage—a stack of dozens of inoperative drones piled up in a heap.
Despite what seems to have been an impressive test show, it’s still impossible from the outside to determine whether Epirus’s tech is ready to fully deliver if the swarms descend.
The Army would not comment specifically on the efficacy of any new weapons in testing or early deployment, including the Leonidas system. A spokesperson for the Army’s Rapid Capabilities and Critical Technologies Office, or RCCTO, which is the subsection responsible for contracting with Epirus to date, would only say in a statement that it is “committed to developing and fielding innovative Directed Energy solutions to address evolving threats.”
But various high-ranking officers appear to be giving Epirus a public vote of confidence. The three-star general who runs RCCTO and oversaw the Leonidas testing last summer toldBreaking Defense that “the system actually worked very well,” even if there was work to be done on “how the weapon system fits into the larger kill chain.”
And when former secretary of the Army Christine Wormuth, then the service’s highest-ranking civilian, gave a parting interview this past January, she mentioned Epirus in all but name, citing “one company” that is “using high-powered microwaves to basically be able to kill swarms of drones.” She called that kind of capability “critical for the Army.”
The Army isn’t the only branch interested in the microwave weapon. On Epirus’s factory floor when I visited, alongside the big beige Leonidases commissioned by the Army, engineers were building a smaller expeditionary version for the Marines, painted green, which it delivered in late April. Videos show that when it put some of its microwave emitters on a dock and tested them out for the Navy last summer, the microwaves left their targets dead in the water—successfully frying the circuits of outboard motors like the ones propelling Houthi drone boats.
Epirus is also currently working on an even smaller version of the Leonidas that can mount on top of the Army’s Stryker combat vehicles, and it’s testing out attaching a single microwave unit to a small airborne drone, which could work as a highly focused zapper to disable cars, data centers, or single enemy drones.
Epirus’s microwave technology is also being tested in devices smaller than the traditional Leonidas.
EPIRUS
While neither the Army nor the Navy has yet to announce a contract to start buying Epirus’s systems at scale, the company and its investors are actively preparing for the big orders to start rolling in. It raised $250 million in a funding round in early March to get ready to make as many Leonidases as possible in the coming years, adding to the more than $300 million it’s raised since opening its doors in 2018.
“If you invent a force field that works,” Lowery boasts, “you really get a lot of attention.”
The task for Epirus now, assuming that its main customers pull the trigger and start buying more Leonidases, is ramping up production while advancing the tech in its systems. Then there are the more prosaic problems of staffing, assembly, and testing at scale. For future generations, Lowery told me, the goal is refining the antenna design and integrating higher-powered microwave amplifiers to push the output into the tens of kilowatts, allowing for increased range and efficacy.
While this could be made harder by Trump’s global trade war, Lowery says he’s not worried about their supply chain; while China produces 98% of the world’s gallium, according to the US Geological Survey, and has choked off exports to the US, Epirus’s chip supplier uses recycled gallium from Japan.
The other outside challenge may be that Epirus isn’t the only company building a drone zapper. One of China’s state-owned defense companies has been working on its own anti-drone high-powered microwave weapon called the Hurricane, which it displayed at a major military show in late 2024.
It may be a sign that anti-electronics force fields will become common among the world’s militaries—and if so, the future of war is unlikely to go back to the status quo ante, and it might zag in a different direction yet again. But military planners believe it’s crucial for the US not to be left behind. So if it works as promised, Epirus could very well change the way that war will play out in the coming decade.
While Miller, the Army CTO, can’t speak directly to Epirus or any specific system, he will say that he believes anti-drone measures are going to have to become ubiquitous for US soldiers. “Counter-UAS [Unmanned Aircraft System] unfortunately is going to be like counter-IED,” he says. “It’s going to be every soldier’s job to think about UAS threats the same way it was to think about IEDs.”
And, he adds, it’s his job and his colleagues’ to make sure that tech so effective it works like “almost magic” is in the hands of the average rifleman. To that end, Lowery told me, Epirus is designing the Leonidas control system to work simply for troops, allowing them to identify a cluster of targets and start zapping with just a click of a button—but only extensive use in the field can prove that out.
Epirus CEO Andy Lowery sees the Leonidas as providing a last line of defense against UAVs.
EPIRUS
In the not-too-distant future, Lowery says, this could mean setting up along the US-Mexico border. But the grandest vision for Epirus’s tech that he says he’s heard is for a city-scale Leonidas along the lines of a ballistic missile defense radar system called PAVE PAWS, which takes up an entire 105-foot-tall building and can detect distant nuclear missile launches. The US set up four in the 1980s, and Taiwan currently has one up on a mountain south of Taipei. Fill a similar-size building full of microwave emitters, and the beam could reach out “10 or 15 miles,” Lowery told me, with one sitting sentinel over Taipei in the north and another over Kaohsiung in the south of Taiwan.
Riffing in Greek mythological mode, Lowery said of drones, “I call all these mischief makers. Whether they’re doing drugs or guns across the border or they’re flying over Langley [or] they’re spying on F-35s, they’re all like Icarus. You remember Icarus, with his wax wings? Flying all around—‘Nobody’s going to touch me, nobody’s going to ever hurt me.’”
“We built one hell of a wax-wing melter.”
Sam Dean is a reporter focusing on business, tech, and defense. He is writing a book about the recent history of Silicon Valley returning to work with the Pentagon for Viking Press and covering the defense tech industry for a number of publications. Previously, he was a business reporter at the Los Angeles Times.
This piece has been updated to clarify that Alex Miller is a civilian intelligence official.
It’s been a little over a week since we published Power Hungry, a package that takes a hard look at the expected energy demands of AI. Last week in this newsletter, I broke down the centerpiece of that package, an analysis I did with my colleague James O’Donnell. (In case you’re still looking for an intro, you can check out this Roundtable discussion with James and our editor in chief Mat Honan, or this short segment I did on Science Friday.)
But this week, I want to talk about another story that I also wrote for that package, which focused on nuclear energy. I thought this was an important addition to the mix of stories we put together, because I’ve seen a lot of promises about nuclear power as a saving grace in the face of AI’s energy demand. My reporting on the industry over the past few years has left me a little skeptical.
As I discovered while I continued that line of reporting, building new nuclear plants isn’t so simple or so fast. And as my colleague David Rotman lays out in his story for the package, the AI boom could wind up relying on another energy source: fossil fuels. So what’s going to power AI? Let’s get into it.
When we started talking about this big project on AI and energy demand, we had a lot of conversations about what to include. And from the beginning, the climate team was really focused on examining what, exactly, was going to be providing the electricity needed to run data centers powering AI models. As we wrote in the main story:
“A data center humming away isn’t necessarily a bad thing. If all data centers were hooked up to solar panels and ran only when the sun was shining, the world would be talking a lot less about AI’s energy consumption.”
But a lot of AI data centers need to be available constantly. Those that are used to train models can arguably be more responsive to the changing availability of renewables, since that work can happen in bursts, any time. Once a model is being pinged with questions from the public, though, there needs to be computing power ready to run all the time. Google, for example, would likely not be too keen on having people be able to use its new AI Mode only during daylight hours.
Solar and wind power, then, would seem not to be a great fit for a lot of AI electricity demand, unless they’re paired with energy storage—and that increases costs. Nuclear power plants, on the other hand, tend to run constantly, outputting a steady source of power for the grid.
As you might imagine, though, it can take a long time to get a nuclear power plant up and running.
Large tech companies can help support plans to reopen shuttered plants or existing plants’ efforts to extend their operating lifetimes. There are also some existing plants that can make small upgrades to improve their output. I just saw this news story from the Tri-City Herald about plans to upgrade the Columbia Generating Station in eastern Washington—with tweaks over the next few years, it could produce an additional 162 megawatts of power, over 10% of the plant’s current capacity.
But all that isn’t going to be nearly enough to meet the demand that big tech companies are claiming will materialize in the future. (For more on the numbers here and why new tech isn’t going to come online fast enough, check out my full story.)
Instead, natural gas has become the default to meet soaring demand from data centers, as David lays out in his story. And since the lifetime of plants built today is about 30 years, those new plants could be running past 2050, the date the world needs to bring greenhouse-gas emissions to net zero to meet the goals set out in the Paris climate agreement.
One of the bits I found most interesting in David’s story is that there’s potential for a different future here: Big tech companies, with their power and influence, could actually use this moment to push for improvements. If they reduced their usage during peak hours, even for less than 1% of the year, it could greatly reduce the amount of new energy infrastructure required. Or they could, at the very least, push power plant owners and operators to install carbon capture technology, or ensure that methane doesn’t leak from the supply chain.
AI’s energy demand is a big deal, but for climate change, how we choose to meet it is potentially an even bigger one.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
This giant microwave may change the future of war
Imagine: China deploys hundreds of thousands of autonomous drones in the air, on the sea, and under the water—all armed with explosive warheads or small missiles. These machines descend in a swarm toward military installations on Taiwan and nearby US bases, and over the course of a few hours, a single robotic blitzkrieg overwhelms the US Pacific force before it can even begin to fight back.
The proliferation of cheap drones means just about any group with the wherewithal to assemble and launch a swarm could wreak havoc, no expensive jets or massive missile installations required.
The US armed forces are now hunting for a solution—and they want it fast. Every branch of the service and a host of defense tech startups are testing out new weapons that promise to disable drones en masse.
And one of these is microwaves: high-powered electronic devices that push out kilowatts of power to zap the circuits of a drone as if it were the tinfoil you forgot to take off your leftovers when you heated them up.Read the full story.
—Sam Dean
This article is part of the Big Story series: MIT Technology Review’s most important, ambitious reporting that takes a deep look at the technologies that are coming next and what they will mean for us and the world we live in. Check out the rest of them here.
What will power AI’s growth?
Last week we published Power Hungry, a series that takes a hard look at the expected energy demands of AI. Last week in this newsletter, I broke down its centerpiece, an analysis I did with my colleague James O’Donnell.
But this week, I want to talk about another story that I also wrote for that package, which focused on nuclear energy. As I discovered, building new nuclear plants isn’t so simple or so fast. And as my colleague David Rotman lays out in his story, the AI boom could wind up relying on another energy source: fossil fuels. So what’s going to power AI? Read the full story.
—Casey Crownhart
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Elon Musk is leaving his role in the Trump administration To focus on rebuilding the damaged brand reputations of Tesla and SpaceX. (Axios) + Musk has complained that DOGE has become a government scapegoat. (WP $) + Tesla shareholders have asked its board to lay out a succession plan. (CNN) + DOGE’s tech takeover threatens the safety and stability of our critical data. (MIT Technology Review)
2 The US will start revoking the visas of Chinese students Including those studying in what the US government deems “critical fields.” (Politico) + It’s also ordered US chip software suppliers to stop selling to China. (FT $)
3 The US is storing the DNA of migrant children It’s been uploaded into a criminal database to track them as they age. (Wired $) + The US wants to use facial recognition to identify migrant children as they age. (MIT Technology Review)
4 RFK Jr is threatening to ban federal scientists from top journals Instead, they may be forced to publish in state-run alternatives. (The Hill) + He accused major medical journals of being funded by Big Pharma. (Stat)
5 India and Pakistan are locked in disinformation warfare False reports and doctored images are circulating online. (The Guardian) + Fact checkers are working around the clock to debunk fake news. (Reuters)
6 How North Korea is infiltrating remote jobs in the US With the help of regular Americans. (WSJ $)
7 This Discord community is creating its own hair-growth drugs Men are going to extreme lengths to reverse their hair loss. (404 Media)
8 Inside YouTube’s quest to dominate your living room It wants to move away from controversial clips and into prestige TV. (Bloomberg $)
9 Sergey Brin threatens AI models with physical violence The Google co-founder insists that it produces better results. (The Register)
10 It must be nice to be a moving day influencer They reap all of the benefits, with none of the stress. (NY Mag $)
Quote of the day
“I studied in the US because I loved what America is about: it’s open, inclusive and diverse. Now my students and I feel slapped in the face by Trump’s policy.”
—Cathy Tu, a Chinese AI researcher, tells the Washington Post why many of her students are already applying to universities outside the US after the Trump administration announced a crackdown on visas for Chinese students.
One more thing
The second wave of AI coding is here
Ask people building generative AI what generative AI is good for right now—what they’re really fired up about—and many will tell you: coding.
Everyone from established AI giants to buzzy startups is promising to take coding assistants to the next level. Instead of providing developers with a kind of supercharged autocomplete, this next generation can prototype, test, and debug code for you. The upshot is that developers could essentially turn into managers, who may spend more time reviewing and correcting code written by a model than writing it from scratch themselves.
But there’s more. Many of the people building generative coding assistants think that they could be a fast track to artificial general intelligence, the hypothetical superhuman technology that a number of top firms claim to have in their sights. Read the full story.
—Will Douglas Heaven
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ If you’ve ever dreamed of owning a piece of cinematic history, more than 400 of David Lynch’s personal items are going up for auction. + How accurate are those Hollywood films based on true stories? Let’s find out. + Rest in peace Chicago Mike: the legendary hype man to Kool & the Gang. + How to fully trust in one another.
This week’s rundown of new products from companies offering services to ecommerce merchants includes cross-border shipping, agentic commerce, virtual try-on, AI-powered store builders, embedded financing, fulfillment platforms, product summaries, and hosting.
Got an ecommerce product release? Email releases@practicalecommerce.com.
New Tools for Merchants
DHL Group partners with Shopify to accelerate cross-border shipping.DHL Group has expanded its shipping partnership with Shopify. DHL now integrates with the Shopify platform, enabling sellers worldwide to access the carrier’s global network and shipping services with just a few clicks. Sellers on Shopify will no longer need to onboard a logistics provider independently, per DHL, adding that the integration helps sellers manage complex customs, legal, and administrative tasks.
DHL Group
StellarWP launches StellarSites to build and launch a WordPress site.StellarWP, a provider of solutions for WordPress, has launched StellarSites to remove the complexity of traditional WordPress setups. According to StellarWP, publishing a full-featured site is now fast and easy with pre-built templates, premium plugins, and WordPress bundled in. Features include an AI setup wizard, automatic updates, backups, and built-in optimization. Premium plugins include KadenceWP (themes), The Events Calendar, GiveWP (fundraising), LearnDash (courses), IconicWP (WooCommerce tools), and SolidWP (security).
Shopify debuts an AI-powered store builder and new AI tools. At its semi-annual “Editions” showcase earlier this month, Shopify released an AI store builder and an AI element generator for banners and other creative. The platform also upgraded Sidekick, its AI assistant, with new voice chat and screen sharing capabilities. Shopify also introduced a new public theme called “Horizon,” which includes built-in AI to assist merchants with designs.
YouLend to finance sellers on eBay.YouLend, an embedded financing platform, has entered a partnership with eBay Germany to provide sellers with flexible access to capital. YouLend and eBay Germany will provide personalized, pre-approved financing offers to sellers, enabling them to determine their eligibility before applying. Via the integration, eBay Seller Capital will support sellers in accessing up to €2 million.
YouLend
Google adds AI shopping features to search. At its annual I/O conference, Google announced several new AI features, including a new shopping experience in AI Mode with a virtual “try it on” feature and an agentic checkout experience within search. With Google Search’s AI Mode, shoppers can conversationally chat what they’re looking for, and the AI feature draws from Google’s visual images and Shopping Graph. Shoppers have the option to let the agentic agent pay autonomously.
InfoSum integrates with Amazon Ads for first-party insights.InfoSum, a data collaboration platform, has announced a new set of integrations with Amazon Ads to enable first-party signals across Amazon DSP (Demand Side Platform) and Amazon Marketing Cloud. According to InfoSum, advertisers can push first-party signals directly to Amazon Ads using InfoSum’s secure user interface. Advertisers can also create custom audiences for targeting in Amazon DSP and leverage insights within Marketing Cloud for advanced analysis. Per InfoSum, advertisers can optimize their media strategies with real-time access to audience insights.
InfoSum
CommerceIQ launches agentic AI for ecommerce.CommerceIQ, an ecommerce platform, has released Ally, a suite of role-specific AI agents to help brands across ecommerce platforms. Trained on data across more than 1,400 retailers such as Amazon, Walmart, and Target, Ally provides ecommerce businesses with insights, performance recommendations, and instant optimizations. The suite offers a Sales Teammate, a Category Teammate to track and manage SKUs, and a Media Teammate to improve ad performance.
Worldpay partners with Yarbie for U.K. SMBs. Point-of-sale provider Yabie has partnered with payments platform Worldpay to power merchant tools within Worldpay 360, a management and payment platform for small to midsize businesses in the U.K. Available across retail, hospitality and service sectors, Yabie integrates with Worldpay’s payment hardware and technology. Worldpay 360 enables merchants to set up and access features such as inventory management, table management, and customizable receipts.
Amazon’s generative AI-powered audio feature synthesizes product summaries.Amazon is testing short-form audio summaries on select product detail pages, with AI-powered shopping experts discussing key product features. Shoppers can listen to the summaries by tapping the “Hear the highlights” button in the Amazon app. The initial test feature focuses on products that typically require consideration and is available to a subset of U.S. customers.