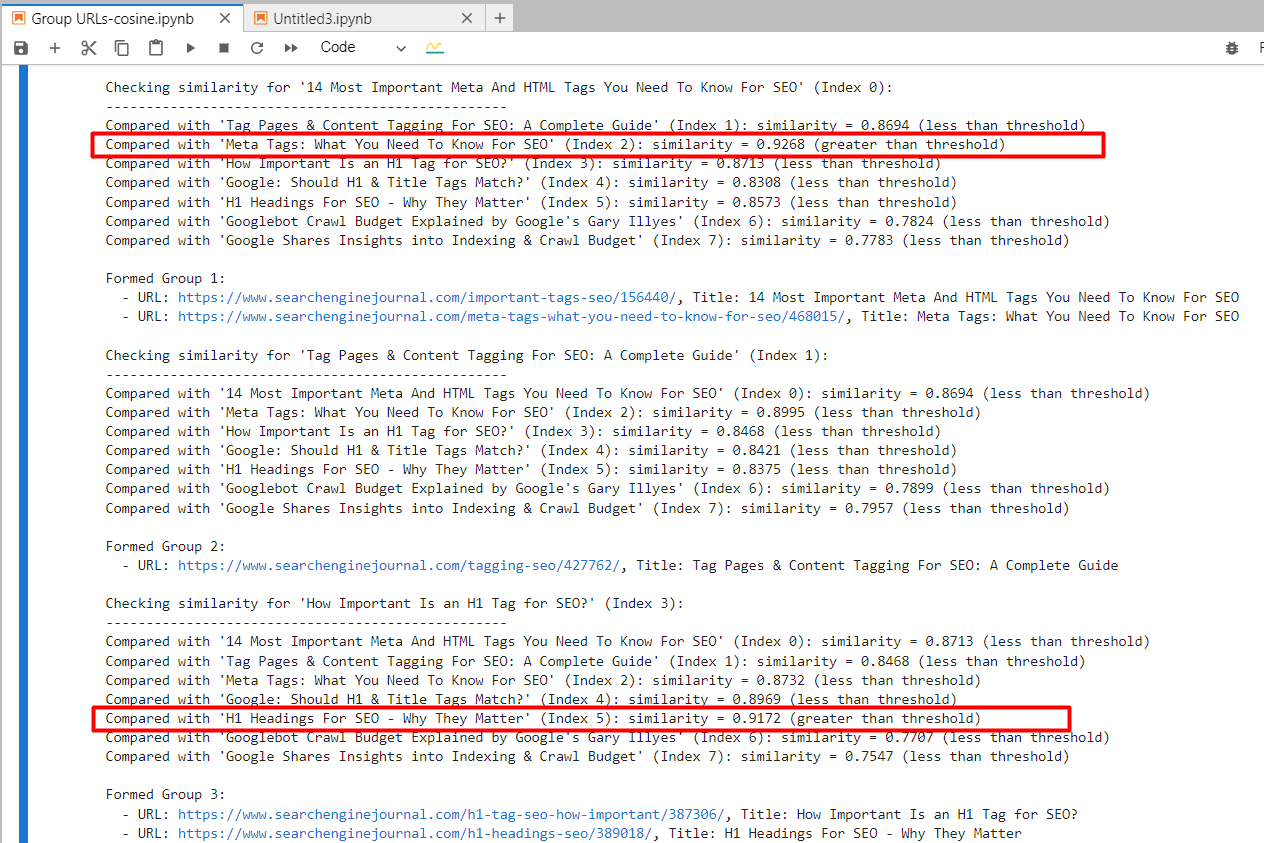
Controversial CRISPR scientist promises “no more gene-edited babies” until society comes around
He Jiankui, the Chinese biophysicist whose controversial 2018 experiment led to the birth of three gene-edited children, says he’s returned to work on the concept of altering the DNA of people at conception, but with a difference.
This time around, he says, he will restrict his research to animals and nonviable human embryos. He will not try to create a pregnancy, at least until society comes to accept his vision for “genetic vaccines” against common diseases.
“There will be no more gene-edited babies. There will be no more pregnancies,” he said during an online roundtable discussion hosted by MIT Technology Review, during which He answered questions from biomedicine editor Antonio Regalado, editor in chief Mat Honan, and our subscribers.
During the interview, He defended his past research and said the “only regret” he had was the difficulties he had caused to his wife and two daughters. He spent three years in prison after a court found him guilty of breaking regulations, but since his release in 2022 he has sought to stage a scientific comeback.
He says he currently has a private lab in the city of Sanya, in Hainan province, where he works on gene therapy for rare disease as well as laboratory tests to determine how, one day, babies could be born resistant to ever developing Alzheimer’s disease.
The Chinese scientist said he’s receiving financial support from individuals in the US and China, and from Chinese companies, and has received an offer to form a research company in Silicon Valley. He declined to name his investors.
Read the full transcript of the event below.
Mat Honan: Hello, everybody. Thanks for joining us today. My name is Mat Honan. I’m the editor in chief here at MIT Technology Review. I’m really thrilled to host what’s going to be, I think, a great discussion today. I’m joined by Antonio Regalado, our senior editor for biomedicine, and He Jiankui, who goes by the name JK.
JK is a biophysicist, He’s based in China, and JK used CRISPR to edit the genes of human embryos, which ultimately resulted in the first children born whose DNA had been tailored using gene editing. Welcome to you both.
To our audience tuning in today, I wanted to let you know if you’ve got questions for us, please do ask them in the chat window. We’ve got a packed discussion planned, but we will get to as many of those as we can throughout. Antonio, I think I’m going to start with you, if we can. You’re the one who broke this story six years ago. Why don’t you set the stage for what we’re going to be talking about here today, and why it’s important.
Antonio Regalado: Mat, thank you.
The subject is genome editing. Of course, it’s a technology for changing the DNA inside of individual cells, including embryos. It’s hard to overstate its importance. I put it up there with the invention of the transistor and artificial intelligence.
And why do I think so? Well, genome editing gives humans control, or at least the ability to try and direct the very processes that brought us about as a species. So it’s that profound.
Getting to JK’s story. In 2018 we had a scoop—he might call it a leak—in which we described his experiment, which, as Mat said, was to edit human embryos to delete a particular gene called CCR5 with the goal of rendering the children, of which there were three, immune to HIV, which their fathers had and which is a source of stigma in China. So that was the project.
Of course our story set off, you know, immediate chaos. Voices were raised all over the world—many critical, a few in support. But one of the consequences was that JK and his team, the parents and the doctors, did not have the ability to tell their own story—in JK’s case because he was, in fact, detained and has completed a term in prison. So we’re happy to have him here to answer my questions and those of our subscribers. JK, thank you for being here.
Several people, including Professor Michael Waitzkin of Duke University, would like to know what the situation is with the three children. What do you know about their health, and where is this information coming from?
He Jiankui: Lulu, Nana, and the third gene-edited baby—they were healthy and are living a normal, peaceful, undisturbed life. They are as happy as any other people, any other children in kindergarten. I have maintained a constant connection with their parents.
Antonio Regalado: I see. JK, on X, you recently made a comment about one of the parents—now a single mother—who you said you were supporting financially. What can you tell us about that situation? What kind of obligations do you have to these children, and are you able to meet those obligations?
He Jiankui: So the third genetic baby—the parents divorced, so the girl is with her mother. You know, a single mother, a single-parent family—life is not easy. So in the last two years, I’m providing some financial support, but I’m not sure it’s the right thing to do or whether it’s ethical, because I’m a scientist or a doctor, and she is a volunteer or patient. For scientists or doctors to provide financial support to the volunteer or patient—it correct? Is it the right thing to do, and is it ethical? That’s something I’m not sure of. So I have this question, actually.
Antonio Regalado: Interesting. Well, there’s a lot of ethical dilemmas here, and one of them is about your publications, the scientific publications which you prepared and which describe the experiment. So a two-part question for you.
First of all, setting the ethics aside, some people who criticized your experiment still want to know the result. They would like to know if it worked. Are the children resistant to HIV or not? So part one of the question is: Are you able to make a measurement on their blood, or is anybody able to make a measurement that would show if the experiment worked? And second part of the question: Do you intend to publish your paper, including as a preprint or as a white paper?
He Jiankui: So I always believe that scientific research must be open and transparent, so I am willing to publish my papers, which I wrote six years ago.
It was rejected by Nature, for some reason. But even today, I would say that I’m willing to publish these two papers in a peer-reviewed journal. It has to be peer-reviewed; that is the standard way to publish in a paper.
The other thing is whether the baby is resistant to HIV. Actually, several years ago, when we designed the experiment, we already collected the [umbilical] cord blood when they were born. We collected cord blood from the babies, and our original experiment design was to challenge the cord blood with the HIV virus to see whether they are actually resistant to HIV. But this experiment never happened, because when the news broke out, there has been no way to do any experiment since then.
I would say I am happy to share my results to the whole world.
Mat Honan: Thanks, Antonio. Let me start with a question from a reader, Karen Jones. She asks, with so much controversy around breaking the law in China, she wanted to know about your credibility. And it reminds me of something that I’m curious about myself. What are the professional consequences of your work? Are you still able to work in China? Are you still able to do experiments with CRISPR?
He Jiankui: Yes, I continue my research in the lab. I have a lab in Sanya [Hainan province], and also previously a lab in Wuhan.
My current work is on gene editing to cure genetic disease such as Duchenne muscular dystrophy and several other genetic diseases. And all this is done by somatic gene therapy, which means this is not working on human embryos.
Mat Honan: I think that leads [to] a question that we have from another reader, Sophie, who wanted to know if you plan to do more gene editing in humans.
He Jiankui: So I have proposed a research project using human embryo gene editing to prevent Alzheimer’s disease. I posted this proposal last year on Twitter. So my goal is we’re going to test the embryo gene editing in mice and monkeys, and in human nonviable embryos. Again, it’s nonviable embryos. There will be no more gene-edited babies. There will be no more pregnancies. We’re going to stop at human nonviable embryos. So our goal is to see if we could prevent Alzheimer’s for offspring or the next generation, because Alzheimer’s has no cure currently.
Mat Honan: I see. And then my last question before I move it back to Antonio. I’m curious if you plan to continue working in China, or if you think that you will ultimately relocate somewhere else. Do you plan to do this work elsewhere?
He Jiankui: Some investors from Silicon Valley proposed to invest in me to start a company in the United States, with research done both in the United States and in China. This is a very interesting proposal, and I am considering it. I would be happy to work in the United States if there’s good opportunity.
Mat Honan: Let me just remind our readers—if you do have questions, you could put them in the chat and we will try to get to them. But in the meantime, Antonio, back over to you, please.
Antonio Regalado: Definitely, I’m curious about what your plans are. Yesterday Stat News reported some of the answers to today’s questions. They said that you have established yourself in the province of Hainan in China. So what kind of facility do you have there? Do you have a lab, or are you doing research? And where is the financial support coming from?
He Jiankui: So here I have an independent private research lab with a few people. We get funding from both the United States and also from China to support me to carry on the research on the gene therapy for Duchenne muscular dystrophy, for high cholesterol, and some other genetic diseases.
Antonio Regalado: Could you be more specific about where the funding is coming from? I mean, who is funding you, or what types of people are funding this research?
He Jiankui: There are people in the United States who made a donation to me. I’m not going to disclose the name and amount. Also the Chinese people, including some companies, are providing funding to me.
Antonio Regalado: I wonder if you could sketch out for us—I know people are interested—where you think all this [is] going to lead. With a long enough time frame—10 years, 20 years, 30 years—do you think the technology will be in use to change embryos, and how will it be used? What is the larger plan that you see?
He Jiankui: I would say in 50 years, like in 2074, embryo gene editing will be as common as IVF babies to prevent all the genetic disease we know today. So the babies born at that time will be free of genetic disease.
Antonio Regalado: You’re working on Alzheimer’s. This is a gene variant that was described in 2012 by deCode Genetics. This is one of these variants that is protective—it would protect against Alzheimer’s. Strictly speaking, it’s not a genetic disease. So what about the role of protective variants, or what could be called improvements to health?
He Jiankui: Well, I decided to do Alzheimer’s disease because my mother has Alzheimer’s. So I’m going to have Alzheimer’s too, and maybe my daughter and my granddaughter. So I want to do something to change it.
There’s no cure for Alzheimer’s today. I don’t know for how many years that will be true. But what we can do is: Since some people in Europe are at a very low risk [for] Alzheimer’s, why don’t we just make some modifications so our next generation also have this protective allele, so they have a low risk of Alzheimer’s or maybe are free of Alzheimer’s. That’s my goal.
Antonio Regalado: Well, a couple of questions. Will any country permit this? I mean, genome editing, producing genome-edited children, was made formally illegal in China, I think in 2021. And it’s prohibited in the United States in another way. So where can you go, or where will you go to further this technology?
He Jiankui: I believe society will eventually accept that embryo gene editing is a good thing because it improves human health. So I’m waiting for society to accept that. My current research is not doing any gene-edited baby or any pregnancy. What I do is a basic research in mice, monkeys, or human nonviable embryos. We only do basic research, but I’m certain that one day society will accept embryo gene editing.
Mat Honan: That raises a question for me. We’re talking about HIV or Alzheimer’s, but there are other aspects of this as well. You could be doing something where you’re optimizing for intelligence or optimizing for physical performance. And I’m curious where you think this leads, and if you think that there is a moral issue around, say, parents who are allowed to effectively design their children by editing their genes.
He Jiankui: Well, I advise you to read the paper I published in 2018 in the CRISPR Journal. It’s my personal thinking of the ethical guidelines for embryo gene editing. It was retracted by the CRISPR Journal. But I proposed that the embryo gene editing should only be used for disease. It should never be used for a nontherapeutic purpose, like making people smarter, stronger, or beautiful.
Mat Honan: Do you not think that becomes inevitable, though, if gene-editing embryos becomes common?
He Jiankui: Society will decide that.
Mat Honan: Moving on: You said that you were only working with animals or with nonviable embryos. Are there other people who you think are working with human embryos, with viable human embryos, or that you know of, or have heard about, continuing with that kind of work?
He Jiankui: Well, I don’t know yet. Actually, many scientists are keeping their distance from me. But there are people from somewhere, an island in Honduras or maybe some small East European country, inviting me to do that. And I refused. I refused. I will only do research in the United States and China or other major countries.
Mat Honan: So the short answer is, that sounded almost like a yes to me? You think that it is happening? Is that correct?
He Jiankui: I’m not answering that.
Mat Honan: Okay, fair enough. I’m going to move on to some reader questions here while we have the time. You mentioned basically having society come around to seeing that this is necessary work. Ravi asks: What type of regulatory framework do you believe is necessary to ensure responsible development and applications of this technology? You had mentioned limiting to therapeutic purposes. Are there other frameworks you think should be in place?
He Jiankui: I’m not answering this question.
Mat Honan: What you think should be in place in terms of regulation?
He Jiankui: Well, there are a lot of regulations. I personally comply with all the laws, regulations, and international ethics for my work.
Mat Honan: I see. Go ahead, Antonio.
Antonio Regalado: Let me just jump in with a related question. You talked about offers of funding from the United States, from Silicon Valley—offers of funding to support you. Is that to create a company, and how would accepting investment from entrepreneurs to start a company change public perception about the technology?
He Jiankui: Well, it was designed as a company registered in the United States and headquartered in the United States.
Antonio Regalado: But do you think that starting a company will make people more enthusiastic or interested in this technology?
He Jiankui: Well, for me, I would certainly be more happy to get an offer from the United States [if it came] from a university or research institution. I would be happy for that, but it’s not happening. But, well, a company started doing some basic research, and that’s also a good contribution.
Antonio Regalado: Getting back to the initial experiment—obviously, it’s been criticized a great deal. And I am just wondering, looking back, which of those criticisms do you accept? Which do you disagree with? Do you have regrets about the experiment?
He Jiankui: The only regret I have is to my family, my wife and my two daughters. In the last few years, they are living in a very difficult situation. I won’t let that happen again.
Antonio Regalado: The technology is viewed as controversial. I’m talking about embryo editing. So it’s a little bit surprising to me that you would return to it. Surprising and interesting. So why is it that you have decided to pursue this vision, this project, despite the problems? I mean, you’re still working on it. What is your motivation?
He Jiankui: Our stance is always for us to do something to benefit mankind.
Antonio Regalado: Speaking of mankind, or humankind, I did have a question about evolution. The gene edits that you made to CCR5 and now are working on to another gene in Alzheimer’s—these are natural mutations that occur in some populations, you mentioned in Europe. They’ve been discovered through population genetics. Studies of a large number of people can find these genetic variations that are protective, or believed to be protective, against disease. In the natural course of evolution, those might spread, right? But it would take hundreds of thousands of years. So with gene editing, you can introduce such a change into an embryo, I guess, in a matter of minutes.
So the question I have is: Is this an evolutionary project? Is it human technology being used to take over from evolution?
He Jiankui: I’m not interested in evolution. Evolution takes thousands of years. I only care about the people surrounding me—my family, and also the patients who would come to find me. What I want to do is help those people, help people in this living world. I’m not interested in evolution.
Antonio Regalado: Mat, any other question from the audience you’d like to throw in?
Mat Honan: Yeah, let me get to one from Rez, who’s asking: What do you see as the major hurdles in advancing CRISPR to more general health-care use cases? What do you see as the big barriers there?
He Jiankui: If you’re talking about somatic gene therapy, the bottleneck, of course, is delivery. Without breakthroughs in delivery technology, somatic gene therapy is heading toward a dead end. For the embryo gene editing, the bottleneck, of course, is: How long will it take people to accept new technology? Because as humans, we are always conservative. We are always worried about the new things, and it takes time for people to accept new technology.
Mat Honan: I wanted to get a question from Robert that goes back to our earlier discussion here, which is: What was your initial motivation to take this step with the three children?
He Jiankui: So several years ago, I went to a village in the center of China where more than 30% of people are infected with HIV. Back to the 1990s, many years ago, people sold blood, and it did something [spread HIV]. When I was there, I saw that there’s a very small kindergarten, only designed for the children of HIV patients. Why did that happen? Other public schools won’t take them. I felt that there’s a kind of discrimination to these children. And what I want to do is to do something to change it. If the HIV patient—if their children are not just free from but actually immune to HIV, then it will help them to go back to the society. For me, it’s just like a vaccine. It’s one vaccine to protect them for a lifetime.
Mat Honan: I see we’re running short on time here, and I do want to try to get to some more of our reader questions. I know Antonio has a last one as well. If you do have questions, please put them in the chat. And from Joseph, he wants to know: You say that you think that the society will come around. What do you think will be the first types of embryo DNA edits that would be acceptable to the medical community or to society at large?
He Jiankui: Very recently, a patient flew here to visit me in my office. They are a couple, they are over 40 years old. They want to have a baby and already did IVF. They have embryos, but the embryos have a problem with a chromosome. So this embryo is not good. So one thing, apparently, we could do to help them is to correct the chromosome problem so they can have a healthy embryo, so they can have children. We’re not creating any immunity to anything—it’s just to restore the health of the embryo. And I believe that would be a good start.
Mat Honan: Thank you, JK. Antonio, back over to you.
Antonio Regalado: JK, I’m curious about your relationship to the government in China, the central government. You were punished, but on the other hand, you’re free to continue to talk about science and do research. Does the government support you and your ideas? Are you a member of the political party? Have you been offered membership? What is your relationship to the government?
He Jiankui: Next question.
Antonio Regalado: Next question? Okay. Interesting. We’ll have to postpone that one for another day.
Mat, anything else? I think we’re coming up against time, and I’m wondering if we have reader questions. I have one here that I could ask, which is about the new technologies in CRISPR. People want to know where this technology is going, in terms of the methods. You used CRISPR to delete a gene. But CRISPR itself is constantly being improved. There are new tools. So in your lab, in your experiments, what gene-editing technology are you employing?
He Jiankui: So six years ago, we were using the original CRISPR-Cas9 invented by Jennifer Doudna. But today, we are moving on to base editing, invented by David Liu. The base editing, it’s safe in embryos. It won’t cut the DNA or break it—just small changes. So we no longer use CRISPR-Cas9. We’re using base editing.
Antonio Regalado: And can you tell me the nature of the genetic change that you’re experimenting with or would like to make in these cells to make them resistant to Alzheimer’s? How big a change are you making with this base editor, or trying to make with it?
He Jiankui: So to make people protected against Alzheimer’s, we just need a single base change in the whole human 3 billion letters of DNA. We just change one letter of it to protect people from Alzheimer’s.
Antonio Regalado: And how soon do you think that this could be in use? I mean, it sounds interesting. If I had a child, I might want them to be immune to Alzheimer’s. So this is quite an interesting proposal. What is the time frame in years—if it works in the lab—before it could be implemented in IVF clinics?
He Jiankui: I would say there’s the basic research that could be finished in two years. I won’t move on to the human trial. That’s not my role. It’s determined by society whether to accept it or not. And that’s the ethical side.
Antonio Regalado: A last question on this from a reader. The question is: How do you prove the benefits? Of course, you can make a genetic change. You can even create a person with a genetic change. But if it’s for Alzheimer’s, it’s going to take 70 years before you know and can prove the results. So how can you prove its medical benefit? Or how can you predict the medical benefit?
He Jiankui: So one thing is that we can observe it in the natural world. There are already thousands of people with this mutation. It helps them against Alzheimer’s. It naturally exists in the population, in humans, so that’s a natural human experiment. And also we could do it in mice. We could use Alzheimer’s model mice and then to modulate DNA to see the results.
You might argue that it takes many years to develop Alzheimer’s, but in society, we’ve done a lot with the HPV vaccine against certain women’s cancers. Cancer takes many years to happen, but they take the HPV vaccine at age eight or seven.
Mat Honan: Thank you so much. JK and Antonio, we are slightly past time here, and I’m going to go ahead and wrap it up. Thank you very much for joining us today, to both of you. And I also want to thank all of our subscribers who tuned in today. I do hope that we see you again next month at our Roundtable in August. It’s our subscriber-only series. And I hope you enjoyed today. Thanks, everybody.
Antonio Regalado: Thank you, JK.
He Jiankui: Thank you.