After operating in secrecy for years, a startup company called R3 Bio, in Richmond, California, suddenly shared details about its work last week—saying it had raised money to create nonsentient monkey “organ sacks” as an alternative to animal testing.
In an interview with Wired, R3 listed three investors: billionaire Tim Draper, the Singapore-based fund Immortal Dragons, and life-extension investors LongGame Ventures.
But there is more to the story. And R3 doesn’t want that story told.
MIT Technology Review discovered that the stealth startup’s founder John Schloendorn also pitched a startling, medically graphic, and ethically charged vision for what he’s called “brainless clones” to serve the role of backup human bodies.
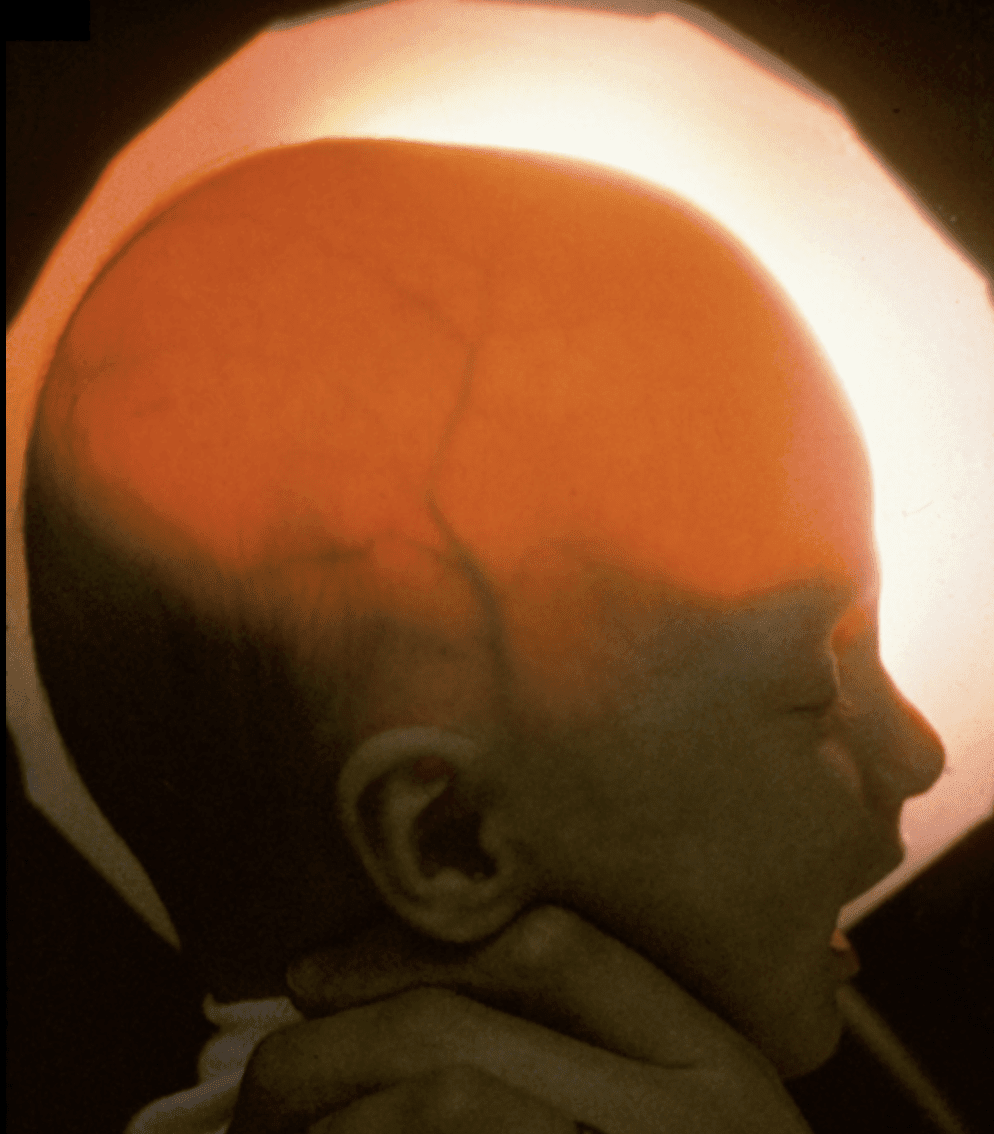
Imagine it like this: a baby version of yourself with only enough of a brain structure to be alive in case you ever need a new kidney or liver.
Or, alternatively, he has speculated, you might one day get your brain placed into a younger clone. That could be a way to gain a second lifespan through a still hypothetical procedure known as a body transplant.
The fuller context of R3’s proposals, as well as activities of another stealth startup with related goals, have not previously been reported. They’ve been kept secret by a circle of extreme life-extension proponents who fear that their plans for immortality could be derailed by clickbait headlines and public backlash.
And that’s because the idea can sound like something straight from a creepy science fiction film. One person who heard R3’s clone presentation, and spoke on the condition of anonymity, was left reeling by its implications and shaken by Schloendorn’s enthusiastic delivery. The briefing, this person said, was like a “close encounter of the third kind” with “Dr. Strangelove.”
A key inspiration for Schloendorn is a birth defect in which children are born missing most of their cortical hemispheres; he’s shown people medical scans of these kids’ nearly empty skulls as evidence that a body can live without much of a brain.
And he’s talked about how to grow a clone. Since artificial wombs don’t exist yet, brainless bodies can’t be grown in a lab. So he’s said the first batch of brainless clones would have to be carried by women paid to do the job. In the future, though, one brainless clone could give birth to another.
Last Monday, the same day it announced itself to the world in Wired, R3 sent us a sweeping disavowal of our findings. It said Schloendorn “never made any statement regarding hypothetical ‘non-sentient human clones’ [that] would be carried by surrogates.” The most overarching of these challenges was its insistence that “any allegations of intent or conspiracy to create human clones or humans with brain damage are categorically false.”
But even Schloendorn and his cofounder, Alice Gilman, can’t seem to keep away from the topic. Just last September, the pair presented at Abundance Longevity, a $70,000-per-ticket event in Boston organized by the anti-aging promoter Peter Diamandis. Although the presentation to about 40 people was not recorded and was meant to be confidential, a copy of the agenda for the event shows that Schloendorn was there to outline his “final bid to defeat aging” in a session called “Full Body Replacement.”
According to a person who was there, both animal research and personal clones for spare organs were discussed. During the presentation, Gilman and Schloendorn even stood in front of an image of a cloning needle. Pressed on whether this was a talk about brainless clones, Gilman told us that while R3’s current business is replacing animal models, “the team reserves the right to hold hypothetical futuristic discussions.”
MIT Technology Review found no evidence that R3 has cloned anyone, or even any animal bigger than a rodent. What we did find were documents, additional meeting agendas, and other sources outlining a technical road map for what R3 called “body replacement cloning” in a 2023 letter to supporters. That road map involved improvements to the cloning process and genetic wiring diagrams for how to create animals without complete brains.
A main purpose of the fundraising, investors say, was to support efforts to try these techniques in monkeys from a base in the Caribbean. That offered a path to a nearer-term business plan for more ethical medical experiments and toxicology testing—if the company could develop what it now calls monkey “organ sacks.” However, this work would clearly inform any possible human version.
Though he holds a PhD, Schloendorn is a biotech outsider who has published little and is best known for having once outfitted a DIY lab in his Bay Area garage. Still, his ties to the experimental fringe of longevity science have earned him a network in Silicon Valley and allies at a risk-taking US health innovation agency, ARPA-H. Together with his success at raising money from investors, this signals that the brainless-clone concept should be taken seriously by a wider community of scientists, doctors, and ethicists, some of whom expressed grave concerns.
“It sounds crazy, in my opinion,” said Jose Cibelli, a researcher at Michigan State University, after MIT Technology Review described R3’s brainless-clone idea to him. “How do you demonstrate safety? What is safety when you’re trying to create an abnormal human?”
Twenty-five years ago, Cibelli was among the first scientists to try to clone human embryos, but he was trying to obtain matched stem cells, not make a baby. “There is no limit to human imagination and ways to make money, but there have to be boundaries,” he says. “And this is the boundary of making a human being who is not a human being.”
“Feasibility research”
Since Dolly the sheep was born in 1996, researchers have cloned dogs, cats, camels, horses, cattle, ferrets, and other species of mammal. Injecting a cell from an existing animal into an egg creates a carbon-copy embryo that can develop, although not always without problems. Defects, deformities, and stillbirths remain common.
Those grave risks are why we’ve never heard of a human clone, even though it’s theoretically possible to create one.
But brainless clones flip the script. That’s because the ultimate aim is to create not a healthy person but an unconscious body that would probably need life support, like a feeding tube, to stay alive. Because this body would share the DNA of the person being copied, its organs would be a near-perfect immunological match.
Backers of this broad concept argue that a nonsentient body would be ethically acceptable to harvest organs from. Some also believe that swapping in fresh, young body parts—known as “replacement”—is the likeliest path to life extension, since so far no drug can reverse aging.
And then there’s the idea of a complete body transplant. “Certainly, for the cryonics patients, that sounds like something really promising,” says Anders Sandberg, a prominent Swedish transhumanist and expert in the ethics of future technologies. He notes that many people who opt to be stored in cryonic chambers after death choose the less expensive “head only” option, so “there might be a market for having an extra cloned body.”
MIT Technology Review first approached Schloendorn two years ago after learning he’d led a confidential online seminar called the Body Replacement Mini Conference, in which he presented “recent lab progress towards making replacement bodies.”
According to a copy of the agenda, that 2023 session also included a presentation by a cloning expert, Young Gie Chung. And there was another from Jean Hébert, who was then a professor at the Albert Einstein College of Medicine and is now a program manager at ARPA-H, where he oversees a project to use stem cells to restore damaged brain tissue. Hébert popularized the so-called replacement solution to avoiding death in a 2020 book called Replacing Aging.
In an interview prior to joining the government in 2024, Hébert described an informal but “very collaborative” relationship with Schloendorn. The overall idea was that to stop aging, one of them would determine how to repair a brain, while the other would figure out how to create a body without one. “It’s a perfect match, right? Body, brain,” Hébert told MIT Technology Review at the time.
Schloendorn, by working outside the mainstream, had the huge advantage of “not being bound by getting the next paper out, or the next grant,” Hébert said, adding, “It’s such a wonderful way of doing research. It’s just clean and pure.” R3 now appears on the ARPA-H website on a list of prospective partners for Hébert’s program.
In a LinkedIn message exchanged with Schloendorn that same year, he described his work as “feasibility research in body replacement.”
“We will try to do it in a way that produces defined societal benefits early on, and we need to be prepared to take no for an answer, if it turns out that this cannot be done safely,” Schloendorn wrote at the time. He declined an interview then, saying that before exiting stealth mode, he wants to be sure the benefits are “reasonably grounded in reality.”
That could prove challenging. While body-part replacement sounds logical, like swapping the timing belt on an old car, in reality there’s scant evidence that receiving organs from a younger twin would make you live any longer.
A complete body transplant, meanwhile, would probably be fatal, at least with current techniques. In the latest test of the concept, published last July, Russian surgeons removed a pig’s head and then sewed it back on. The animal did live—breathing weakly and lapping water from a syringe. But because its spinal cord had been cut, it was otherwise totally paralyzed. (As yet, there’s no proven method to rejoin a severed spinal cord.) In an act of mercy, the doctors ended the pig’s life after about 12 hours.
Even some of R3’s investors say the endeavor is a risky, low-odds project, on par with colonizing Mars. Boyang Wang, head of Immortal Dragons, has spoken at longevity conferences about body-swapping technology, referring to the chance that “when the time comes, you can transplant your brain into a new body.” Wang confirmed in a January Zoom call that he’d been referring to R3 and that he invested $500,000 in the company during a 2024 fundraising round.
But since making his investment, Wang says, he’s become less bullish. He now views whole-body transplant as “very infeasible, not even very scientific” and “far away from hope for any realistic application.”
Still, he says, the investment in R3 fits with his philosophy of making unorthodox bets that could be breakthroughs against aging. “What can really move the needle?” he asks. “Because time is running out.”
Stealth mode
Clonal bodies sit at the extreme frontier of an advancing cluster of technologies all aimed at growing spare parts. Researchers are exploring stem cells, synthetic embryos, and blob-like organoids, and some companies are cloning genetically engineered pigs whose kidneys and hearts have already been transplanted into a few patients. Each of these methods seeks to harness development—the process by which animal bodies naturally form in the womb—to grow fully functional organs.
There’s even a growing cadre of mainstream scientists who say nonsentient bodies could solve the organ shortage, if they could be grown through artificial means. Two Stanford University professors, calling these structures “bodyoids,” published an editorial in favor of manufacturing spare human bodies in MIT Technology Review last year. While that editorial left many details to the imagination, they called the idea “at least plausible—and possibly revolutionary.”
“There are a lot of variations on this where they’re trying to find a socially acceptable form,” says George Church, a Harvard University professor who advises startups in the field. But Church says gestating an entire body is probably taking things too far, especially since nearly all patients on transplant lists are waiting for just a single organ, like a heart or kidney.
“There’s almost no scenario where you need a whole body,” he says. “I just think even if it’s someday acceptable, it’s not a good place to start.” For the moment, Church says, brainless human bodies are “not very useful, in addition to being repulsive.”
That’s arguably why body replacement technology still feels risky to talk about, even among life-extension enthusiasts who are otherwise ready to inject Chinese peptides or have their bodies cryogenically frozen. “I think it’s exciting or interesting from a scientific perspective, but I think the world is not fully ready for it yet,” says Emil Kendziorra, CEO of Tomorrow Bio, a company in Berlin that stores bodies at -196 °C in the hope they can be restored to life in the future.
“Everybody’s like, yeah, you know, cryopreservation makes total sense,” he says. “And then you talk about total body replacement. And then everybody’s like, Whoa, whoa, whoa.”
Even so, “replacement” technology has found a fervent base of support among a group of self-described “hardcore” longevity adherents who follow a philosophy called Vitalism, which holds that society should redirect resources toward achieving unlimited lifespans. The growing influence of this movement, achieved through lobbying, investment, recruiting, and public messaging, was detailed earlier this year in MIT Technology Review.
Last spring, during a meetup for this community, Kendziorra was among the attendees at an invite-only “Replacement Day” gathering that took place off the public schedule. It was where more radical ideas could be discussed freely, since to some in the Vitalist circle, replacing body parts has emerged as the most plausible, least expensive way to beat death.
At least that was the conclusion of a road map for anti-aging technology produced by one Vitalist group, the Longevity Biotech Fellowship, which reckoned that a proof-of-concept human clone lacking a neocortex would cost $40 million to create—a tiny amount, relatively speaking.
Its report cited the existence of two stealth companies working on cloning whole nonsentient bodies, although it took care not to name them. If these companies’ activities become public, “there will be a huge backlash—people will hate it,” the entrepreneur Kris Borer said while presenting the road map at a French resort last August.
“There are a ton of dystopian movies and novels about this kind of stuff. That is why I didn’t talk about any of the companies working on it. They are trying to hide from public attention,” he said. “We have to have the angel investors and other people invest kind of in secret until things are ready.”
Borer did say what he sees as the best way to go public: first, to slowly ease body replacement into society’s awareness by disclosing more limited aims, which will be palatable. “We are not going to start with Let’s clone you and give you a body. We are going to start with Let’s solve the organ shortage,” he said. “Eventually people will warm up to it, and then we can go to the more hardcore stuff.”
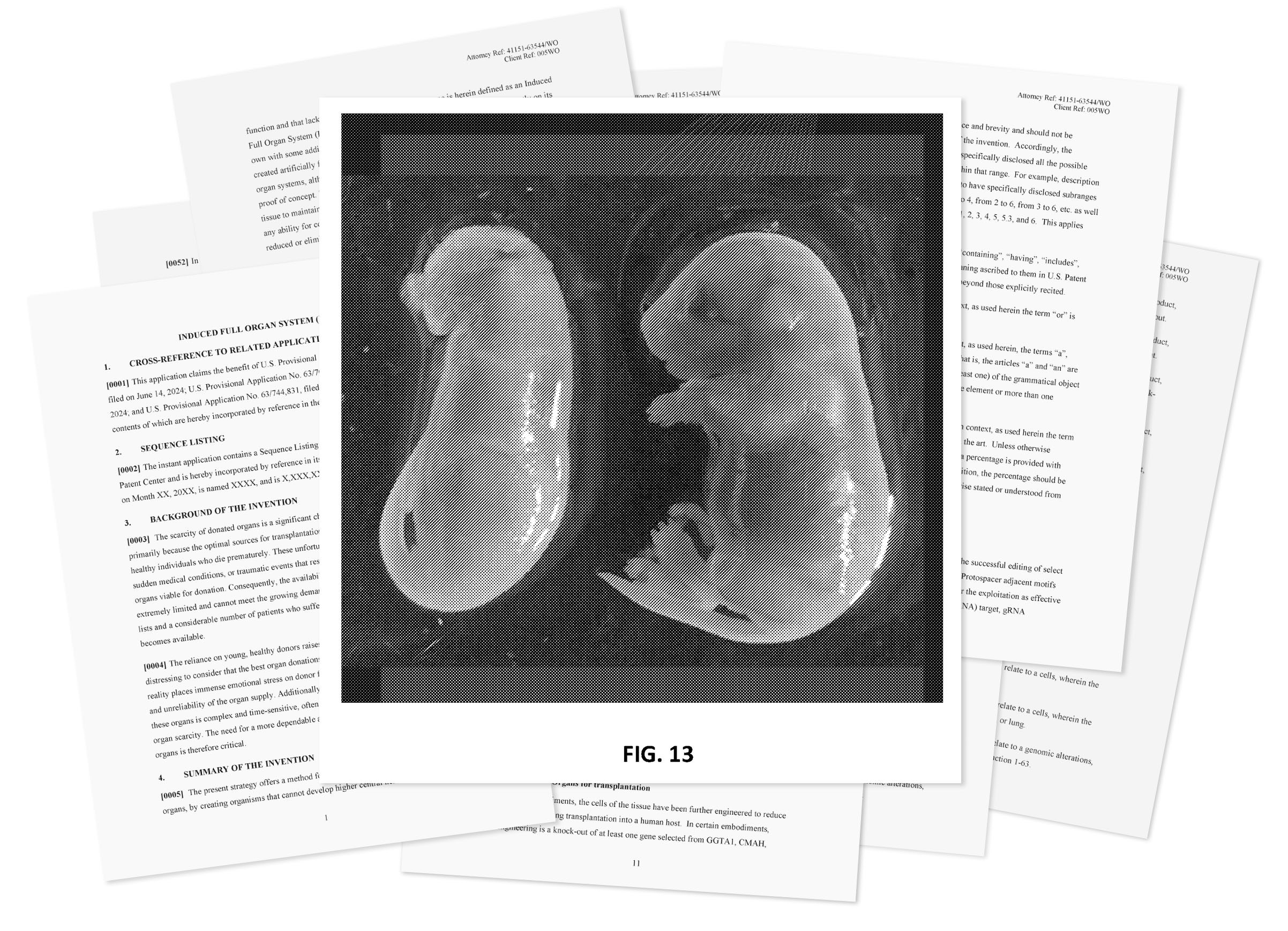
In an interview earlier this month, Borer declined to name the companies involved in his immortality road map, or to say if R3 is one of them. But we did identify one additional stealthy startup, this one focused on replacing a person’s internal organs, not the whole body. Called Kind Biotechnology, it is a New Hampshire–based company headed by the anti-aging researcher Justin Rebo, a sometime collaborator of Schloendorn’s.
According to patent applications filed by the company, Rebo’s team is working to create animals with a “complete lack of ability to feel, think, or sense the environment.” Images included in the patents show mice the company produced that lack a complete brain, and others that don’t have faces or limbs. They did that by deleting genes in embryos using the gene-editing technology CRISPR with the goal of creating a “sack of organs that grows mostly on its own,” with only a minimal nervous system. A cartoon rendering submitted to the patent office shows what looks like a fleshy duffel bag connected to life support tubes.
In an email, Rebo said his company is working on an “ethical and scalable” way to create animal organs for experimental transplant to humans. He notes that “thousands die while waiting” for an organ.
Some of Kind’s patent applications do cover the possibility of producing these organ sacks from human cells. Rebo says that’s more of a speculative possibility. But he does see his work as part of the “replacement” approach to longevity. Firstly, that’s because a “scalable production of young, high-quality organs” would let surgeons try transplants in more types of patients, including many with heart disease in old age who aren’t candidates for a transplant now.
“With abundant high-quality organs, replacement could become a direct form of rejuvenation by replacement of failing parts,” he says.
And Rebo imagines that simultaneously replacing multiple internal organs (grown together in the sack) could have even broader rejuvenating effects. “Ultimately, replacing failing parts is a direct path to extending healthy human lifespan,” he says.
Church, who agreed earlier this year to advise Kind Bio, sees this work as part of an effort to “nudge” these technologies “toward something that is more useful and more acceptable from the get-go,” he says. “And then let’s see how society responds to that—rather than jumping to the most repulsive and most useless form, which some of them seem to be aiming for.”
“There’s one way to find out”
People who know Schloendorn describe a dynamo-like presence who is “100% dedicated” to the goal of extreme life extension. In 2006, he penned a paper in a bioethics journal outlining why the “desire to live forever” is rational, and his doctoral research at the University of Arizona was sponsored by a longevity research organization called the SENS Foundation.
He’s also well connected. In an interview, Aubrey de Grey, the influential and controversial fundraiser and prognosticator who cofounded SENS, called Schloendorn “one of my protégés.” And around 2010, Peter Thiel reportedly invested $1.5 million in ImmunePath, a company started by Schloendorn to develop stem-cell treatments, though it soon failed. (A representative for Thiel did not respond to a request to confirm the figure.)
By 2021, Schloendorn had moved on, founding R3 Biotechnologies. He began to circulate the body replacement idea and discuss a step-by-step scheme to get there: assess techniques in the lab first, then in monkeys, and maybe eventually in humans.
A 2023 “letter to stakeholders” signed by Schloendorn begins by saying that “body replacement cloning will require multicomponent genetic engineering on a scale that has never been attempted in primates.” Fortunately, it adds, molecular techniques for “brain knockout” are well known in mice and should also be expected to function in “birthing whole primates,” a class that includes both monkeys and humans.
Would it work? “There’s one way to find out,” the letter says.
Wang, the investor at Immortal Dragons, says he put money into R3 after it showed him it is possible to create mice without complete brains. “There were imperfections, but the resulting mice survived, grew up, and to me, that is a pretty strong experiment,” he says; it was evidence enough for him to fund R3’s attempt to “replicate the result in primates.”
(In its emailed statement, R3 said the company and its founders “never produced any degree of brain alterations in any species, did not attempt to do so, did not hire another party to do so, and have no specific plans to do so in the future.” It added: “We do not work with live non-human primates.”)
The bigger technical obstacle, though, remains the cloning. Out of 100 attempts to clone an animal, only a few typically succeed. That fact alone makes cloning a human—or a monkey—almost infeasible.
But R3 does seem to have made an effort to tackle the efficiency problem. In one document reviewed by MIT Technology Review, it claims to have implemented improvements to the basic procedure in rodents, referencing a protein, called a histone demethylase, that helps erase a cell’s genetic memory. Adding it can greatly increase the chance that the cell will form a cloned embryo after being injected into an egg in the lab.
Those molecules were used in the first successful cloning of a monkey, which occurred in 2018 in China. But it still wasn’t easy—in fact, it was a huge and costly effort to handle a crowd of monkeys in estrus and perform IVF on them. According to Michigan State’s Cibelli, monkey cloning remains nearly impossible, at least on US territory, just because it’s “unaffordable.”
Nevertheless, success in monkeys did help prove, at least biologically, that human reproductive cloning could be possible.
The company may also have tried to tackle a second long-standing obstacle to cloning: defects in how the placenta works. Because of such problems, some cloned animals die quickly after birth.
The R3 document refers to a “birthing fix” it developed to further improve the cloning success rate. While MIT Technology Review didn’t learn what R3’s process entails, we found a reference to it on the LinkedIn page of Maitriyee Mahanta, a scientist who cosigned the 2023 letter to R3 stakeholders and is a former research assistant to Hébert. (We were unable to reach Mahanta for comment.)
Her page described her current role as “molecular lead” studying cloning, “birth rate fixing,” and cortical development using cells from nonhuman primates. Her job affiliation is given as the Longevity Escape Velocity Foundation, a nonprofit where de Grey is the president and chief science officer. But de Grey says his foundation only arranged a work visa for Mahanta as part of a partnership “with the company she actually spends her time at.”
Like several other people interviewed for this article, de Grey made a resourceful effort to avoid directly confirming the existence of R3 when we spoke, while at the same time freely discussing theoretical aspects of body cloning technology. For instance, he talked about ways to shorten the wait for your double to grow up to a size suitable for organ harvesting; a further genetic mutation could be added to cause “central precocious puberty” in the clone, he said. This condition causes a growth spurt, even pubic hair, in a toddler.
Cloning dictators
Who would clone a body and pay to keep it alive for years, until it’s needed? The first customers for this costly technology (if it ever proves feasible) would likely be the ultra-rich or the ultra-powerful.
Indeed, somehow the world’s top dictators seem to have gotten the memo about replacement parts. In September, a hot mic picked up a conversation between Russian president Vladimir Putin and Chinese leader Xi Jinping as they walked through Beijing with North Korean autocrat Kim Jong Un; in the exchange, the Russian speculated on life extension.
“Biotechnology is continuously developing. Human organs can be continuously transplanted. The longer you live, the younger you become, and [you can] even achieve immortality,” Putin said through an interpreter.
“Some predict that in this century, humans will live to 150 years old,” Xi responded agreeably.
How the leaders learned of these possibilities is unknown. But scenarios involving dictators are a constant topic among body replacement enthusiasts.
“There are companies working on this. They are in stealth—we can’t reveal too much about them—but the general concept on this is if you didn’t have any ethical qualms, you could do most of it today,” Will Harborne, the chief investment officer of LongGame Advisors, said last year, during an interview with the podcaster Julian Issa. “If you were the dictator of some country and wanted a clone of yourself, you can already go grow one. You can create a cloned embryo of yourself, you can get a surrogate to carry it to term, and you can grow [a] body until age 18 with a brain, and eventually, if you were a dictator, you could kill them and try to transplant your head on their body.”
“And now no one is suggesting you do that—it’s very unethical—but most of the technology is there,” he said. He noted that the reason for removing the cortex of a clone created for such a purpose is that “we don’t want to kill other people to live forever.”
Harborne subsequently confirmed to MIT Technology Review that the fund invested $1 million in R3 about a year and a half ago.
In order to make the body replacement process ethical, the clone’s brain needs to be stunted so it lacks consciousness. That is where the interest in birth defects comes in. Remarkable medical scans of kids with a rare condition, hydranencephaly, show a total absence of the cerebral hemispheres. Yet if they are cared for, they may be able to live into their 20s, even though they cannot speak or engage in purposeful movement.
The technical question, then, is how to intentionally produce such a condition in a clone. Sandberg, the futurist, says he’s visited R3’s lab, talked to Gilman, and sat through a presentation about how genetic engineering can be used to shape brain growth. Previous work has shown that by adding a toxic gene, it is possible to kill specific cell types in a growing embryo but spare others, leading to a mouse without a neocortex.
While Sandberg isn’t an expert in biotechnology, he says R3’s theory looked sensible to him. “I think it’s possible to actually prevent the development of the brain well enough that you can say ‘Yeah, there is almost certainly no consciousness here,’” Sandberg says. “Hence, there can’t be any suffering, or any individual, in a practical sense.”
“I think the overall aim—actually, it looks ethically pretty good,” he says.
Yet it could be difficult to really determine where consciousness starts and ends. Under current medical standards, taking the organs of people with hydranencephaly isn’t allowed because they don’t meet the standard of brain death: They have a functioning brain stem. An even more serious problem is evidence that the brain stem alone produces a basic form of consciousness. If that is so, says Bjorn Merker, a neuroscientist who surveyed caretakers of more than a hundred children with hydranencephaly, a plan “to harvest organs from organisms modeled on this condition would be unethical.”
Of course, the most extreme version of the replacement dream isn’t just to take organs. It’s to take over the body entirely. Sergio Canavero, a controversial Italian surgeon who has proposed head and brain transplants, says he was approached for advice by Schloendorn and others a few years ago. “They told me they were looking at a head transplant on a two- or three-year-old,” he says. “I stopped short. How could you even conceive of that? The biomechanical compatibility is not there. You have to wait until at least 14. And I would say 16. It was very clear to me these guys are not surgeons—they are biologists.”
Canavero says he’s not opposed to cloning bodies for transplant—he thinks it could work. “But if you want to use a clone,” he says, “it must be a nonsentient clone. Otherwise it’s murder, a homicide.”
MIT Technology Review has not found any evidence that R3 has yet created an “organ sack,” much less a brainless human clone. And there are many reasons to believe their hypothetical future of “full body replacement” will never come to pass—that it is just a live-forever fantasy.
“There are so many barriers,” says Cibelli. It’s a long list: Human cloning is illegal in many countries, it’s unsafe, and few competent experts would want, or dare, to participate. And then there’s the inconvenient fact that for now, there’s no way to grow a brainless clone to birth, except in a woman’s body. Think about it, Cibelli says: “You’d have to convince a woman to carry a fetus that is going to be abnormal.”
Sandberg agrees that is where things could start to get tricky. “The problem here, of course,” he says, “is that the yuck factor is magnificent.”