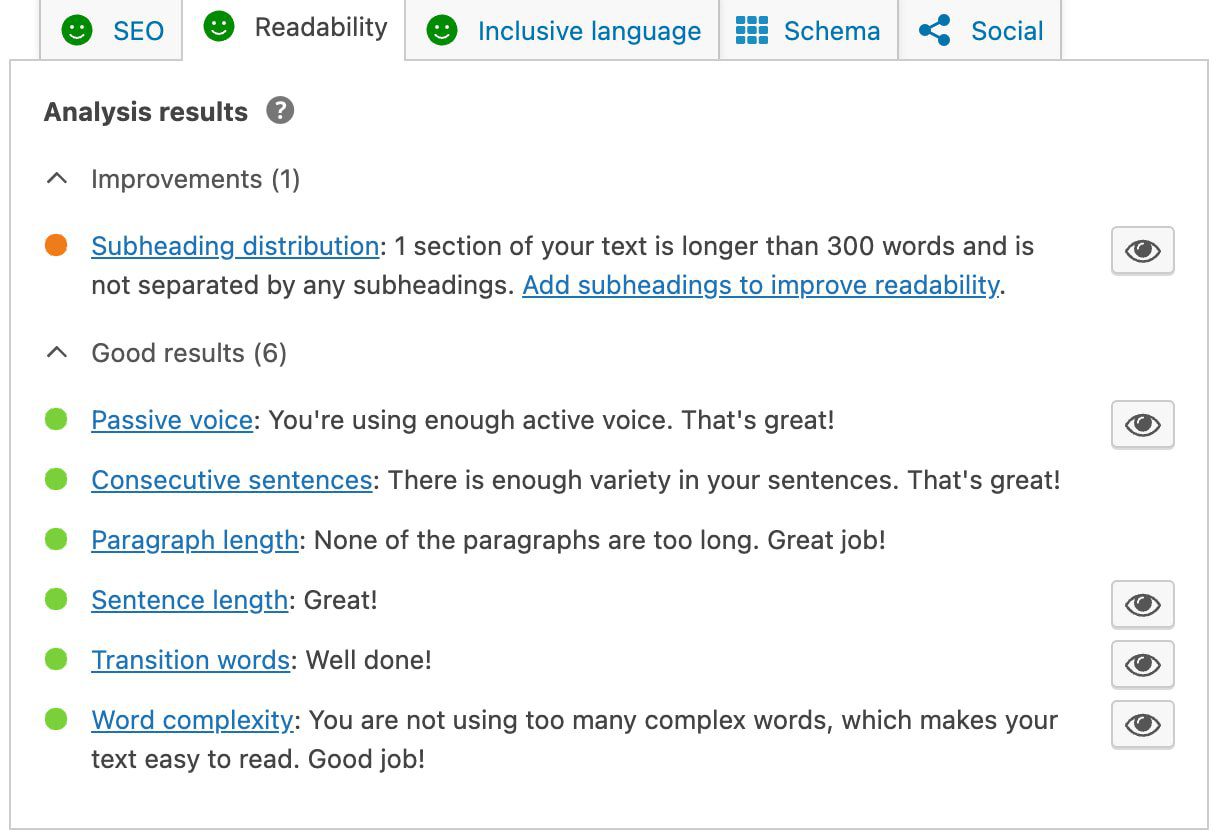
Stanford’s Human-Centered Artificial Intelligence Institute published its 2026 AI Index Report. The report runs over 400 pages across nine chapters covering technical performance, investment, workforce effects, and public sentiment.
The number getting the most attention is that Generative AI reached 53% adoption among the global population within three years of ChatGPT’s launch. That’s faster than either the personal computer or the internet reached comparable levels.
For anyone working in search, the report contains data that connects directly to the changes you’ve been navigating all year.
What The Report Found
This is the ninth annual AI Index, and it covers a lot of ground. A few findings matter most for the search industry.
In terms of capability, frontier models now exceed human performance on PhD-level science questions and in competitive mathematics. AI agents handling real-world tasks improved from a 20% success rate in 2025 to 77% today. Coding benchmarks that models struggled with a year ago are now nearly solved.
On investment, global corporate AI investment hit $581 billion in 2025, up 130% from the prior year. US private AI investment reached $285 billion. More than 90% of frontier models now come from private companies, not academic labs.
Regarding workforce effects, employment among software developers aged 22 to 25 has dropped by nearly 20% since 2024. A similar pattern appeared in customer service and other roles with higher AI exposure.
Transparency is declining. The Foundation Model Transparency Index fell from 58 to 40. The most capable models now disclose the least about their training data, parameters, and methods. Of the 95 most notable models launched last year, 80 were released without their training code.
The Adoption Number Everyone Is Citing
Understanding the 53% figure, what it includes, and what it doesn’t, matters for how you interpret it.
The comparison to PCs and the internet is based on research by the St. Louis Fed, Vanderbilt, and Harvard Kennedy School. The team compared adoption rates by years since each technology’s first mass-market product. The IBM PC launched in 1981. Commercial internet traffic opened in 1995. ChatGPT launched in November 2022.
At comparable points after launch, generative AI adoption runs well ahead of both earlier technologies.
But the comparison isn’t apples-to-apples, and the researchers said so themselves. Harvard’s David Deming pointed out that AI is built on top of PCs and the internet. People already had the hardware and the connectivity. Nobody needed to buy new equipment or wait for connectivity to reach their area. AI adoption rode on decades of prior technology investment.
Adoption numbers also vary depending on who’s counting and how. The Stanford report puts US adoption at 28%, ranking the country 24th globally. The St. Louis Fed’s own tracker puts US adoption at 54% as of August 2025. Same country, nearly double the rate, measured differently. The Fed team even revised its earlier estimate upward from 39% to 44% after changing the order of its survey questions.
“Adoption” also doesn’t distinguish intensity. Someone who signed up for a free ChatGPT account and tried it once counts the same as someone who uses it eight hours a day. The Stanford report notes that most users access free or near-free tiers. That’s a different picture than the one the headline number implies.
None of this means the adoption data is wrong. Generative AI is spreading faster than comparable technologies did at the same stage. But the speed of adoption alone doesn’t tell you how deeply it’s embedded in workflows or how much it’s changing search behavior specifically.
The Jagged Frontier
The report’s most useful concept for search professionals might be its “jagged frontier” of AI capability.
The same models that win gold at the International Mathematical Olympiad read analog clocks correctly only 50% of the time. IEEE Spectrum reported that Claude Opus 4.6 scores at the top of Humanity’s Last Exam while reading clocks at just 8.9% accuracy. Models that ace PhD-level science questions still struggle with video understanding and multi-step planning.
Ray Perrault, co-director of the AI Index steering committee, told IEEE Spectrum that benchmarks don’t map cleanly to real-world results. Knowing a model scores 75% on a legal reasoning benchmark “tells us little about how well it would fit in a law practice’s activities,” he said.
Search professionals have seen similar unevenness in AI search products. Ahrefs research showed that AI Mode and AI Overviews cite different URLs for the same queries, with only 13% overlap. Google’s Robby Stein acknowledged that the system pulls AI Overviews back when people don’t engage with them. Those signals suggest AI search performance is uneven across contexts, even if Google hasn’t fully explained where those differences are most pronounced.
Stanford’s data suggest that strong benchmark performance doesn’t guarantee reliable results across all tasks or query types. Whether that unevenness improves with future models is an open question the report doesn’t answer.
What’s Happening To Transparency
What the report says about transparency connects directly to search.
The Foundation Model Transparency Index dropped from 58 to 40 in a single year. The most capable models score lowest. Google, Anthropic, and OpenAI have all stopped disclosing dataset sizes and training duration for their latest models. 80 of the 95 most notable models launched in 2025 shipped without training code.
TechCrunch noted a disconnect between expert optimism about AI and public anxiety about it. The US reported the lowest trust in its government’s ability to regulate AI among the countries surveyed, at 31%.
For context on the index itself, a drop from 58 to 40 could indicate that companies are becoming more secretive. It could also reflect that the index penalizes closed-source models by design, and the most capable models happen to be closed-source. Both explanations can be true at the same time.
What matters for practitioners is the implication. The models powering AI Overviews, AI Mode, and ChatGPT Search are getting more capable and less explainable simultaneously. You’re optimizing for systems where the companies building them are sharing less about how they work, not more.
The report’s acknowledgments disclose that Stanford HAI receives financial support from Google, OpenAI, and others, and that the report was produced with assistance from ChatGPT and Claude.
The Entry-Level Question
Employment among software developers aged 22 to 25 dropped nearly 20% since 2024, according to the report. Older developers’ headcounts grew over the same period. A similar pattern appeared in customer service roles.
At first glance, that looks like AI replacing entry-level work. But the report included a caveat that complicates that conclusion. Unemployment is rising across many occupations, and workers least exposed to AI have seen it rise more than those most exposed.
That doesn’t rule out AI as a factor. It means the 20% decline could reflect AI displacement, broader hiring slowdowns, companies restructuring their entry-level hiring, or all three at once. The report presents correlation, not causation.
For search and content teams, the signal is directional even if the cause is mixed. The Stanford data is consistent with what the Tufts AI Jobs Risk Index showed earlier this year. Roles that involve assembling information from existing sources face more pressure than roles that require judgment, experience, and original analysis.
Why This Matters For Search Professionals
Even with its caveats, the adoption speed explains the pace of what you’ve been seeing.
The adoption curve helps explain why Google has been expanding AI search features at this pace. It doesn’t tell us how much of that usage is happening inside search rather than standalone AI tools.
The “jagged frontier” means you can’t make blanket assumptions about AI search quality across query categories. A query type that returns accurate AI Overviews today might hallucinate with slight variations. Monitoring needs to happen at the query level, not the category level. Search Console doesn’t currently separate AI Overview or AI Mode performance from traditional search metrics, which makes this harder.
The decline in transparency affects how well you can understand why your content appears or doesn’t appear in AI-generated answers. When Google shares less about the models powering its search features, the feedback loop between what you publish and what gets surfaced becomes harder to read.
Shelley Walsh spoke at SEJ Live and referenced Grant Simmons, “golden knowledge” is content built on original data, firsthand experience, and depth that AI summaries can’t replicate from training data. The Stanford report’s data on adoption speed and model limitations support that position. The models are fast and widely used, but they’re uneven. Content that fills the gaps where AI is unreliable has a structural advantage.
What The Report Doesn’t Tell Us
The Stanford report doesn’t break out search-specific adoption data. We don’t know what percentage of that 53% uses AI via search specifically, rather than via ChatGPT, Gemini, or other standalone tools.
The report also can’t tell us whether the jagged frontier problem is improving or worsening in search applications. The benchmark data shows models improving overall, but the clock-reading example shows that improvement isn’t uniform. Whether AI Overviews and AI Mode are getting more reliable for the specific queries that matter to your business requires your own monitoring, not aggregate benchmark data.
Looking Ahead
The Stanford report lands one week after Google’s March core update completed. Alphabet’s next earnings call will likely include updated AI search usage numbers.
The adoption data doesn’t predict what search will look like by year-end. But it does confirm that AI-first behavior isn’t speculative anymore. The question is whether Google’s AI search products will get reliable enough to match the pace of adoption.
The handsome new book Maintenance: Of Everything, Part One, by the tech industry legend Stewart Brand, promises to be the first in a series offering “a comprehensive overview of the civilizational importance of maintenance.” One of Brand’s several biographers described him as a mainstay of both counterculture and cyberculture, and with Maintenance, Brand wants us to understand that the upkeep and repair of tools and systems has profound impact on daily life. As he puts it, “Taking responsibility for maintaining something—whether a motorcycle, a monument, or our planet—can be a radical act.”
Radical how? This volume doesn’t say. In an outline for the overall work, Brand says his goal is to “end with the nature of maintainers and the honor owed them.”
The idea that maintainers are owed anything, much less honor, might surprise some readers. Actually, maintenance and repair have been hot topics in academia since the mid-2010s. I played some role in that movement as a cofounder of the Maintainers, a global, interdisciplinary network dedicated to the study of maintenance, repair, care, and all the work that goes into keeping the world going.
Brand is right, too, that maintainers haven’t gotten the laurels they deserve. Over the past few decades, scholars have shown that work from oiling tools to replacing worn parts to updating code bases all tends to be lower in status than “innovation.” Maintenance gets neglected in many organizational and social settings. (Just look at some American infrastructure!) And as the right-to-repair movement has shown, companies in pursuit of greater profits have frequently locked us out of being able to do repairs or greatly reduced the maintainable life of their products. It’s hard to think of any other reason to put a computer in the door of a refrigerator.
Some of Brand’s earlier work helped inspire those insights. But his new book makes me think he doesn’t see things that way. For Brand, maintenance seems to be a solitary act, profound but more about personal success and fulfillment than tending to a shared world or making it better.
Born in 1938, Brand is 87 years old. A sense hangs over the book—with its battles against corrosion, rust, and decay, with its attempts to keep things going even as they inevitably falter—of someone looking over life and pondering its end. Maintenance: Of Everything connects to every stage of Brand’s life. It’s worth reviewing where it falls in that arc. Brand has always been interested in tools and fixing things, but rarely has he focused on the systems that need the most care.
More than a half-century ago, Brand was a member of the Merry Pranksters, a countercultural, LSD-centered hippie collective famously led by Ken Kesey, the author of One Flew Over the Cuckoo’s Nest. In 1966, Brand co-produced the Trips Festival, where bands like the Grateful Dead and Big Brother and the Holding Company performed for thousands amid psychedelic light shows.
Brand’s Whole Earth Catalog had a vision that might feel progressive, but its libertarian, rugged-individualist philosophy of remaking civilization alone stood in contrast to more collective social change movements.
In some ways, the Trips Festival set a paradigm for the rest of his life’s work. Brand’s biographers have described him as a network celebrity—someone who got ahead by bringing people together, building coalitions of influential figures who could boost his signal. As Kesey put it in 1980, “Stewart recognizes power. And cleaves to it.”
Brand applied this network logic to the undertaking he will always be best remembered for: the Whole Earth Catalog. First published in 1968 and aimed at hippies and members of the nascent back-to-the-land movement, the publication had the motto “Access to tools.” Its pages were full of Quonset huts, geodesic domes, solar panels, well pumps, water filters, and other technologies for life off the grid. It was a vision that might feel progressive or left-leaning, but the libertarian, rugged-individualist philosophy of eschewing corrupt systems and remaking civilization alone stood in contrast to the more collective movements pushing for deep social change at the time—like civil rights, feminism, and environmentalism.
That vision also led straight to the empowerment that came with new digital tools, and to Silicon Valley. In 1985, Brand published the Whole Earth Software Catalog, the last of the series, and also cofounded the WELL—the Whole Earth ’Lectronic Link, a pioneering online community famous for, among other things, facilitating the trade of Grateful Dead bootlegs. He also wrote a hagiographic book about the MIT Media Lab, known for its corporate-sponsored research into new communications tech. “The Lab would cure the pathologies of technology not with economics or politics but with technology,” Brand wrote. Again, not collective action, not policymaking: tools. And Brand then cofounded the Global Business Network, a group of pricey consulting futurists that further connected him to MIT, Stanford, and the Valley. Brand had literally helped bring about the modern digital revolution.
His attention then turned toward its upkeep. Brand’s 1994 book, How Buildings Learn: What Happens After They’re Built, argued against high-modernist architectural ideas. Nearly all buildings eventually get remade, he argued, but he especially favored cheap, simple structures that inhabitants could easily retool to suit changing needs. In some ways, Brand was recapitulating the liberated—or libertarian—philosophy of the Whole Earth Catalog: People can remake their world, if they have access to tools. In a chapter titled “The Romance of Maintenance,” he asked readers to see the beauty, value, and occasional pleasures of fixer-uppers of all kinds.
This chapter was a touchstone for many of us in the academic subfield of maintenance studies. Researchers in disciplines like history, sociology, and anthropology, as well as artists and practitioners in fields like libraries, IT, and engineering, all started trying to understand the realities and, yes, romance of maintenance and repair. Brand joined and contributed to Listservs, attended conferences, chatted with intellectual leaders. So it’s a bit uncharitable when he writes that his new book is “the first to look at maintenance in general.” He knows better. The real question, though, is what his work has to teach us that others have not said before. In this first volume, the answer is unclear.
Maintenance: Of Everything, Part One is an odd book. If so much of Brand’s thinking has been about access to tools, he now asks, in a more extended way: How are our tools maintained? But where Brand began his career with a catalogue, in this volume we get … what? A digest? An almanac? An encyclopedia? Its form and riotous variety fit no genre easily.
The book has two chapters. The first, “The Maintenance Race,” recounts the story of three men who took part in the Golden Globe, a round-the-world race for solo sailors held in 1968. Each of the sailors, Brand explains, had a different philosophy of maintenance. One neglected it and hoped for the best. He died. Another thought of and prepared for everything in advance, and while he didn’t win the race, he completed it and once held the record for the “world’s longest recorded nonstop solo sailing voyage.” The final sailor won and did so through heroic acts of perseverance; his style was “Whatever comes, deal with it,” Brand explains. Structured like a fairy tale and unremittingly romantic, the story—like most of the anecdotes in the book—focuses on the derring-do of vigorous white guys. The strategy is no secret. Brand’s outline explains: “Start with a dramatic contest of maintenance styles under life-critical conditions—a true story told as a fable.” This myth is meant to inspire.
The second chapter, “Vehicles (and Weapons),” is over 150 pages long. It has five sections, multiple subsections, five subsections designated “digressions,” one called a “subdigression,” two “postscripts,” and several “footnotes” that are not footnotes in a formal sense but, rather, further addenda. At times, it all feels like notes for a future work. Brand makes no apology for the book’s woolliness. “All I can offer here,” he writes, “is to muse across a representative of maintenance domains and see what emerges.” Perhaps the most charitable reading of the potpourri is that it represents the return of a Merry Prankster, offering us a riotous varied light show. It’s a good book to leave on a table and occasionally open to a random page for entertainment. But it often seems as if it does not know what it wants to say or be.
“Vehicles (and Weapons)” begins by paraphrasing two famous works of maintenance philosophy, Robert M. Pirsig’s Zen and the Art of Motorcycle Maintenance and Matthew B. Crawford’s Shop Class as Soulcraft. Maintenance involves both “problem finding” and “problem solving.” While much repair work is marked by anxiety, impatience, and boredom, it also offers positive values and outcomes. “Motorcycle maintainers take heart from what they repair for—the glory of the ride,” Brand writes.
The beauty and triumph of cheapness is a running theme throughout the work, harking back to How Buildings Learn. Henry Ford’s Model T won out over early electric vehicles and hugely expensive luxury vehicles like Rolls-Royce’s Silver Ghost because it was cheap and easier to maintain. The three most popular cars in human history—the Ford Model T, the Volkswagen Bug, and the Lada “Classic” from Russia—all privileged cheapness, “retained their basic design for decades, and … invited repair by the owner.” Or, to be fair, maybe demanded it? For every hobbyist who delighted in being able to self-reliantly keep a VW running, there must have been thousands who appreciated how cheap it was and hated that it broke a lot. Brand never points to social research, like surveys, that might help us know people’s feelings on such matters.
Other sections recount how Americans created interchangeable parts (enabling not only cheap mass production but also easy maintenance), examine how maintenance works with assault rifles and in war, and track the history of technical manuals from the early modern period to the age of YouTube. These stories are solid, but they’re also well known to students of technology, and nearly all are recycled from the work of others, featuring many large block quotes. The volume breaks little new ground.
Brand treats maintenance as an unalloyed good. But the field of maintenance studies has moved on, burrowing into the domain’s ironies, complexities, and difficulties. A simple example: In most cases, it is environmentally far better to retire and recycle an internal-combustion vehicle and buy an electric one than to keep the polluting beast going forever. Maintaining a gas-guzzler or a coal-burning power plant isn’t a radical act but a regressive one. Also, maintenance can become a life-breaking burden on the poor, and it falls inequitably on the shoulders of women and people of color. Keeping existing systems going can be a way of avoiding tough, necessary change—like making technological systems more accessible for people with disabilities. In this volume, Brand is uninterested in such difficult trade-offs. He avoids any question of how politics shapes these issues, or how they shape politics.
This avoidance comes out most clearly in a section of “Vehicles (and Weapons)” that talks about Elon Musk—a character of “unique mastery,” Brand informs us. He tells us that Bill Gates once shorted Tesla’s stock, only to lose $1.5 billion. The lesson is clear: Elon won.
In what political and social vision is money the best way to keep the score? Brand rightly points out that electric vehicles have fewer moving parts and, in that sense, are more maintainable than internal-combustion vehicles. He celebrates Musk most of all because his products “have all proven to be game changers in part because they combine ingenious design with surprisingly low cost.” Again, it’s Brand’s “cheap, available tools” hypothesis. But there’s a real superficiality and lack of follow-through in thinking here: Teslas remain luxury vehicles whose sales have slumped since federal tax subsidies disappeared. The company has faced several right-to-repair lawsuits; there’s even a law review article on the topic. Musk is in no sense a maintenance hero. Yet Brand writes that with his companies, “Musk may have done more practical world saving than any other business leader of his time.” By the time Brand was writing this book, the controversies surrounding Musk for at least flirting with antisemitism, racism, sexism, authoritarianism, and more were quite clear. About this, the book says not a word.
Maintenance: Of Everything, Part One Stewart Brand
STRIPE PRESS, 2026
For sure, Brand needn’t agree with Musk’s critics, but failing to even broach the subject is tone deaf and out of touch. Others have argued that Silicon Valley’s “Move fast and break things” mentality undermines healthy maintenance. Brand doesn’t raise the idea—even to dismiss it.
It could be that with Maintenance: Of Everything, Part One Brand is just getting going; that in subsequent volumes he’ll have something more coherent to say; that he’ll raise really hard questions and try to answer them. But given his track record, we might reasonably doubt it. Kesey said Brand cleaves to power; he certainly doesn’t question it.
Lee Vinsel is an associate professor of science, technology, and society at Virginia Tech and host of Peoples & Things, a podcast about human life with technology.
Roboticists used to dream big but build small. They’d hope to match or exceed the extraordinary complexity of the human body, and then they’d spend their career refining robotic arms for auto plants. Aim for C-3P0; end up with the Roomba.
The real ambition for many of these researchers was the robot of science fiction—one that could move through the world, adapt to different environments, and interact safely and helpfully with people. For the socially minded, such a machine could help those with mobility issues, ease loneliness, or do work too dangerous for humans. For the more financially inclined, it would mean a bottomless source of wage-free labor. Either way, a long history of failure left most of Silicon Valley hesitant to bet on helpful robots.
That has changed. The machines are yet unbuilt, but the money is flowing: Companies and investors put $6.1 billion into humanoid robots in 2025 alone, four times what was invested in 2024.
What happened? A revolution in how machines have learned to interact with the world.
Imagine you’d like a pair of robot arms installed in your home purely to do one thing: fold clothes. How would it learn to do that? You could start by writing rules. Check the fabric to figure out how much deformation it can tolerate before tearing. Identify a shirt’s collar. Move the gripper to the left sleeve, lift it, and fold it inward by exactly this distance. Repeat for the right sleeve. If the shirt is rotated, turn the plan accordingly. If the sleeve is twisted, correct it. Very quickly the number of rules explodes, but a complete accounting of them could produce reliable results. This was the original craft of robotics: anticipating every possibility and encoding it in advance.
Around 2015, the cutting edge started to do things differently: Build a digital simulation of the robotic arms and the clothes, and give the program a reward signal every time it folds successfully and a ding every time it fails. This way, it gets better by trying all sorts of techniques through trial and error, with millions of iterations—the same way AI got good at playing games.
The arrival of ChatGPT in 2022 catalyzed the current boom. Trained on vast amounts of text, large language models work not through trial and error but by learning to predict what word should come next in a sentence. Similar models adapted to robotics were soon able to absorb pictures, sensor readings, and the position of a robot’s joints and predict the next action the machine should take, issuing dozens of motor commands every second.
This conceptual shift—to reliance on AI models that ingest large amounts of data—seems to work whether that helpful robot is supposed to talk to people, move through an environment, or even do complicated tasks. And it was paired with other ideas about how to accomplish this new way of learning, like deploying robots even if they aren’t yet perfect so they can learn from the environment they’re meant to work in. Today, Silicon Valley roboticists are dreaming big again. Here’s how that happened.
Jibo
Jibo
A movable social robot carried out conversations long before the age of LLMs.
An MIT robotics researcher named Cynthia Breazeal introduced an armless, legless, faceless robot called Jibo to the world in 2014. It looked, in fact, like a lamp. Breazeal’s aim was to create a social robot for families, and the idea pulled in $3.7 million in a crowdsourced funding campaign. Early preorders cost $749.
The early Jibo could introduce itself and dance to entertain kids, but that was about it. The vision was always for it to become a sort of embodied assistant that could handle everything from scheduling and emails to telling stories. It earned a number of devoted users, but ultimately the company shut down in 2019.
A crowdfunding campaign started in 2014 and drew 4,800 Jibo preorders.
COURTESY OF MIT MEDIA LAB
In retrospect, one thing that Jibo really needed was better language capabilities. It was competing against Apple’s Siri and Amazon’s Alexa, and all those technologies at the time relied on heavy scripting. In broad terms, when you spoke to them, software would translate your speech into text, analyze what you wanted, and create a response pulled from preapproved snippets. Those snippets could be charming, but they were also repetitive and simply boring—downright robotic. That was especially a challenge for a robot that was supposed to be social and family oriented.
What has happened since, of course, is a revolution in how machines can generate language. Voice mode from any leading AI provider is now engaging and impressive, and multiple hardware startups are trying (and failing) to build products that take advantage of it.
But that comes with a new risk: While scripted conversations can’t really go off the rails, ones generated by AI certainly can. Some popular AI toys have, for example, talked to kids about how to find matches and knives.
OpenAI
Dactyl
A robot hand trained with simulations tries to model the unpredictability and variation of the real world.
By 2018, every leading robotics lab was trying to scrap the old scripted rules and train robots through trial and error. OpenAI tried to train its robotic hand, Dactyl, virtually—with digital models of the hand and of the palm-size cubes Dactyl was supposed to manipulate. The cubes had letters and numbers on their faces; the model might set a task like “Rotate the cube so the red side with the letter O faces upward.”
Here’s the problem: A robotic hand might get really good at doing this in its simulated world, but when you take that program and ask it to work on a real version in the real world, the slight differences between the two can cause things to go awry. Colors might be slightly different, or the deformable rubber in the robot’s fingertips could turn out to be stretchier than it was in simulation.
Dactyl, part of OpenAI’s first attempt at robotics, was trained in simulation to solve Rubik’s Cubes.
COURTESY OF OPENAI
The solution is called domain randomization. You essentially create millions of simulated worlds that all vary slightly and randomly from one another. In each one the friction might be less, or the lighting more harsh, or the colors darkened. Exposure to enough of this variation means the robots will be better able to manipulate the cube in the real world. The approach worked on Dactyl, and one year later it was able to use the same core techniques to do something harder: solving Rubik’s Cubes (though it worked only 60% of the time, and just 20% when the scrambles were particularly hard).
Still, the limits of simulation mean that this technique plays a far smaller role today than it did in 2018. OpenAI shuttered its robotics effort in 2021 but has recently started the division up again—reportedly focusing on humanoids.
Google DeepMind
RT-2
Training on images from across the internet helps robots translate language into action.
Around 2022, Google’s robotics team was up to some strange things. It spent 17 months handing people robot controllers and filming them doing everything from picking up bags of chips to opening jars. The team ended up cataloguing 700 different tasks.
The point was to build and test one of the first large-scale foundation models for robotics. As with large language models, the idea was to input lots of text, tokenize it into a format an algorithm could work with, and then generate an output. Google’s RT-1 received input about what the robot was looking at and how the many parts of the robotic arm were positioned; then it took an instruction and translated it into motor commands to move the robot. When it had seen tasks before, it carried out 97% of them successfully; it succeeded at 76% of the instructions it hadn’t seen before.
The model RT-2, for Robotic Transformer 2, incorporated internet data to help robots process what they were seeing.
COURTESY OF GOOGLE DEEPMIND
The second iteration, RT-2, came out the following year and went even further. Instead of training on data specific to robotics, it went broad: It trained on more general images from across the internet, like the vision-language models lots of researchers were working on at the time. That allowed the robot to interpret where certain objects were in the scene.
“All these other things were unlocked,” says Kanishka Rao, a roboticist at Google DeepMind who led work on both iterations. “We could do things now like ‘Put the Coke can near the picture of Taylor Swift.’”
In 2025, Google DeepMind further fused the worlds of large language models and robotics, releasing a Gemini Robotics model with improved ability to understand commands in natural language.
Covariant
RFM-1
An AI model that allows robotic arms to act like coworkers.
In 2017, before OpenAI shuttered its first robotics team, a group of its engineers spun out a project called Covariant, aiming to build not sci-fi humanoids but the most pragmatic of all robots: an arm that could pick up and move things in warehouses. After building a system based on foundation models similar to Google’s, Covariant deployed this platform in warehouses like those operated by Crate & Barrel and treated it as a data collection pipeline.
By 2024, Covariant had released a robotics model, RFM-1, that you could interact with like a coworker. If you showed an arm many sleeves of tennis balls, for example, you could then instruct it to move each sleeve to a separate area. And the robot could respond—perhaps predicting that it wouldn’t be able to get a good grip on the item and then asking for advice on which particular suction cups it should use.
This sort of thing had been done in experiments, but Covariant was launching it at significant scale. The company now had cameras and data collection machines in every customer location, feeding back even more data for the model to train on.
A Covariant robot demonstrates “induction”—the common warehouse task of placing objects on sorters or conveyors.
COURTESY OF COVARIANT
It wasn’t perfect. In a demo in March 2024 with an array of kitchen items, the robot struggled when it was asked to “return the banana” to its original location. It picked up a sponge, then an apple, then a host of other items before it finally accomplished the task.
It “doesn’t understand the new concept” of retracing its steps, cofounder Peter Chen told me at the time. “But it’s a good example—it might not work well yet in the places where you don’t have good training data.”
Chen and fellow founder Pieter Abbeel were soon hired by Amazon, which is currently licensing Covariant’s robotics model (Amazon did not respond to questions about how it’s being used, but the company runs an estimated 1,300 warehouses in the US alone).
Agility Robotics
Digit
Companies are putting this humanoid to the test in real-world settings.
The new investment dollars flowing to robotics startups are aimed largely at robots shaped not like lamps or arms but like people. Humanoid robots are supposed to be able to seamlessly enter the spaces and jobs where humans currently work, avoiding the need to retool assembly lines to accommodate new shapes such as giant arms.
It’s easier said than done. In the rare cases where humanoids appear in real warehouses, they’re often confined to test zones and pilot programs.
Amazon and other companies are using Digit to help move shipping totes.
COURTESY OF AGILITY ROBOTICS
That said, Agility’s humanoid Digit appears to be doing some real work. The design—with exposed joints and a distinctly unhuman head—is driven more by function than by sci-fi aesthetics. Amazon, Toyota, and GXO (a logistics giant with customers like Apple and Nike) have all deployed it—making it one of the first examples of a humanoid robot that companies see as providing actual cost savings rather than novelty. Their Digits spend their days picking up, moving, and stacking shipping totes.
The current Digit is still a long way from the humanlike helper Silicon Valley is betting on, though. It can lift only 35 pounds, for example—and every time Agility makes Digit stronger, its battery gets heavier and it has to recharge more often. And standards organizations say humanoids need stricter safety rules than most industrial robots, because they’re designed to be mobile and spend time in proximity to people.
But Digit shows that this revolution in robot training isn’t converging on a single method. Agility relies on simulation techniques like those OpenAI used to train its hand, and the company has worked with Google’s Gemini models to help its robots adapt to new environments. That’s where more than a decade of experiments have gotten the industry: Now it’s building big.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The problem with thinking you’re part Neanderthal
There’s a theory that many of us have an “inner Neanderthal.” The idea is that Homo sapiens and a cousin species once bred, leaving some people today with a trace of Neanderthal DNA.
This DNA is arguably the 21st century’s most celebrated discovery in human evolution. But in 2024, a pair of French geneticists called into question the theory’s very foundations.
They proposed that what scientists interpret as interbreeding could instead be explained by population structure—the way genes concentrate in smaller, isolated groups.
This story is from the next issue of our print magazine, which is all about nature. Subscribe now to read it when it lands on Wednesday, April 22.
Why having “humans in the loop” in an AI war is an illusion
—Uri Maoz
AI is starting to shape real wars. It’s at the center of a legal battle between Anthropic and the Pentagon, playing a growing role in the conflict with Iran, and raising questions about how much humans should remain “in the loop.”
Under Pentagon guidelines, human oversight is meant to provide accountability, context, and security. But the idea of “humans in the loop” is a comforting distraction.
The real danger isn’t that machines will act without oversight; it’s that human overseers have no idea what the machines are actually “thinking.” Thankfully, science may offer a way forward.
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Despite blacklisting Anthropic, the White House wants its new model Trump officials are negotiating access to Mythos. (Axios) + Anthropic said it was too dangerous for a public release. (Bloomberg $) + Finance ministers are alarmed about the security risks. (BBC) + Anthropic just rolled out a model that’s less risky than Mythos. (CNBC) + The Pentagon has pursued a culture war against the company. (MIT Technology Review)
2 Sam Altman’s side hustles have raised conflict-of-interest concerns His opaque investments could influence decisions at OpenAI. (WSJ $) + A jury will soon decide if OpenAI abandoned its founding mission. (Wired $) + The company is making a big play for science. (MIT Technology Review)
3 A Starlink outage during drone tests exposed the Pentagon’s SpaceX reliance It was one of several Navy test disruptions linked to Starlink. (Reuters $) + The DoD is also tapping Ford and GM for military innovations.(NYT $)
4 Data center delays threaten to choke AI expansion 40% of this year’s projects are at risk of falling behind schedule. (FT $) + Partly because no one wants a data center in their backyard. (MIT Technology Review)
5 Alibaba just released its own version of a world model Happy Oyster is the latest attempt to extend AI’s ability to comprehend physical reality. (SCMP) + But they still need to understand cause and effect. (FT $)
6 Google’s Gemini is now generating AI images tailored to personal data By analyzing users’ Google services and data. (Quartz) + Google says it will cut the need for detailed prompts. (TechCrunch)
7 OpenAI is beefing up its agentic coding and development system Its Codex update is a direct shot at Claude Code. (The Verge) + But not everyone is convinced about AI coding. (MIT Technology Review)
8 Europe’s online age verification app is here It’s available for free to any company that wants it. (Wired $)
9 Smartglasses are giving Korean theaters hope of a K-Pop moment Their AI-powered translations are taking the shows to the world. (NYT $)
10 Global voice actors are fighting Hollywood’s AI push Their voices are training the models that are replacing them. (Rest of World)
Quote of the day
“There’s this dark period between now and some time in the future where the advantage is very much offensive AI.”
—Rob Joyce, former director of cybersecurity at the National Security Agency, tells Bloomberg how AI is creating new hacking threats.
One More Thing
COURTESY OF NOVEON MAGNETICS
The race to produce rare earth elements
Access to rare earth elements will determine which countries meet their goals for lowering emissions or generating energy from non-fossil-fuel sources. But some nations, including the US, are worried about the supply of these elements.
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ This ska cover of Rage Against the Machine is an upbeat way to start a revolution. + We finally know how far Stretch Armstrong can really stretch. + Customize these ambient sounds to wash away disruptive thoughts. + Here’s proof childhood dreams can come true: a girl guiding a seal to perform tricks.
I’ve interviewed a slew of impressive entrepreneurs on this podcast. Drew Fallon is among the most versatile. He and I last spoke in 2022 when he had co-founded a tattoo skincare company. Before that he was an investment banker.
He now runs Iris, an AI-driven financial modeling platform, while also tracking and reporting on consumer-focused M&A transactions.
In our recent conversation, he shared the benefits of agent-powered automation, common merchant use cases, and, yes, the enterprise M&A boom in 2026.
Our entire audio is embedded below. The transcript is edited for length and clarity.
Eric Bandholz: What the heck do you do?
Drew Fallon: I’m the founder and CEO of Iris. We work with brands to deploy AI agents and automate many of their financial and operational workflows.
Prior to Iris, I was a co-founder of the tattoo skincare company Mad Rabbit for about five years, serving as CFO and COO. Before that I was an investment banker. Iris launched two years ago.
Bandholz: I’ve seen your social media posts announcing M&A deals. How do you obtain that info?
Fallon: I’ve got a handful of AI agents that crawl the web. They know what I’ve written and care about. They will surface those types of stories to me. I then pick them and blast them out.
The last couple of weeks have been crazy. Unilever scooped up Grüns, the nutritional gummy snacks, for $1.2 billion. The Finnish Long Drink, a citrus-flavored alcohol beverage, has just sold to the Mark Anthony Group, the company that owns White Claw. Huel, a British meal-replacement company, sold for $1.1 billion to Danone, the global food and beverage giant.
A lot is going on now, but very few big deals occurred in 2025. You had Poppi and Siete Foods, both acquired by PepsiCo. But overall the year was pretty lackluster for M&A.
But now we’re seeing deals of all sizes. There was a lot of pent-up demand, in part from privacy equity firms that had raised a lot of money.
Bandholz: Should today’s brands focus on mass consumers or on high-price-point niches?
Fallon: I would avoid price-conscious shoppers, especially if I were an emerging brand. It’s much better to pursue a high-dollar niche. Beardbrand, your company, is a good example. Not every dude with a beard will spend the money on your products, but those who really care about their beard will.
We’re seeing good traction with premium supplements, beauty, apparel, and food and beverage niches.
Bandholz: Tell us more about Iris’s use of AI.
Fallon: We started the company roughly when ChatGPT launched. I knew I had to be involved with that industry. Think of Iris as the data infrastructure to deploy AI agents. We integrate with Shopify, Amazon, Walmart, Facebook, Gusto, Rippling, bank accounts, credit cards, Bill.com, QuickBooks, and others.
We operate like a centralized data warehouse. We transform the data so AI agents can use it easily. Our agents are purpose-built for automating finance workflows. But the Iris infrastructure could create all sorts of agents. We’ve chosen to tackle financial models, inventory needs, business intelligence dashboards, cash flow forecasts — pretty much anything that an internal or fractional CFO would do.
For example, we help merchants determine how much to spend on customer acquisition. We’ll analyze variables such as gross margin, channel mix, operating expenses, and cash balances. A client could ask us for the profitability of $60, $70, or $80 CAC. We’ll provide the trade-offs for each and suggest the best channels for scaling.
Our inventory planning models are demand-driven. We first predict sales, then we look at the historical product mix, both seasonally and in aggregate. From there, it’s a basic mathematical model to estimate product distribution, such as 15% for beard oil, 25% for balm, and so on.
We can also model inventory velocity in December versus July, for example.
It is no secret that publishing SEO-friendly blog posts is one of the easiest and most effective ways to drive organic traffic and improve SERP rankings. However, in the era of artificial intelligence, blog posts matter more than ever. They help establish brand authority by consistently delivering fresh, valuable content that can be cited in AI-generated answers.
In this guide, we will share a practical, detailed approach to writing SEO-friendly blog content that not only ranks on Google SERPs but is also surfaced by AI models.
Table of contents
Key takeaways
SEO friendly blog post now means writing with search intent, ensuring content is clear and quotable for AI systems
Key factors for SEO friendly blog posts include trustworthiness, machine-readability, answer-first structure, and topical authority
Conduct thorough keyword research and find readers’ questions to match search intent effectively
Use clear headings, improve readability, include inclusive language, and add relevant media to engage readers
Write compelling meta titles and descriptions, link to existing content, and focus on building authority to enhance visibility
What does an SEO-friendly blog post mean in the AI era?
The way people search for information has changed, and with it, the meaning of an SEO-friendly blog post. Before the rise of generative AI, writing an SEO-friendly blog post mostly meant this:
‘Writing content with the intention of ranking highly in search engine results pages (SERPs). The content is optimized for specific target keywords, easy to read, and provides value to the reader.’
That definition is not wrong. But it is no longer complete.
In the AI era, an SEO-friendly blog post is written with search intent first, answering a user’s question clearly and efficiently. It is not just about placing keywords in the right spots. It is about creating an information-dense piece with accurate, well-structured, and quotable sentences that AI systems can confidently extract and surface as direct answers.
The new definition clearly shows that strong SEO foundations still matter, and they matter more than ever. What has changed is how content is evaluated and discovered. Search engines and AI models now look beyond clicks and rankings to understand whether your content is trustworthy, helpful, and easy to interpret.
Here are some key factors that play a key role in determining whether a blog post is truly SEO-friendly:
Trustworthiness (E-E-A-T): Demonstrating real-world experience, expertise, and credibility helps your content stand out from low-value AI-generated rehashes
Machine-readability: Clear structure, clean HTML, and technical signals such as schema markup help search engines and AI systems understand what your content is about
Answer-first structure: Placing concise, direct answers at the beginning of sections makes it easier for AI models to extract and reference your content
Topical authority: Publishing interconnected, in-depth content around a subject is far more effective than creating isolated blog posts
9 tips to write SEO-friendly blogs for LLM and SERP visibility
Now we get to the core of this guide. Below are some foundational tips to help you plan and write SEO-friendly blog posts that are genuinely helpful, easy to understand, and focused on solving real reader problems. When done right, these practices not only improve search visibility but also shape how your brand is perceived by both users and AI systems.
1. Conduct thorough keyword research
Before you start writing a single word, start with solid keyword research. This step helps you understand how people search for a topic, which terms carry demand, and how competitive those searches are. It also ensures your content aligns with real user intent instead of assumptions.
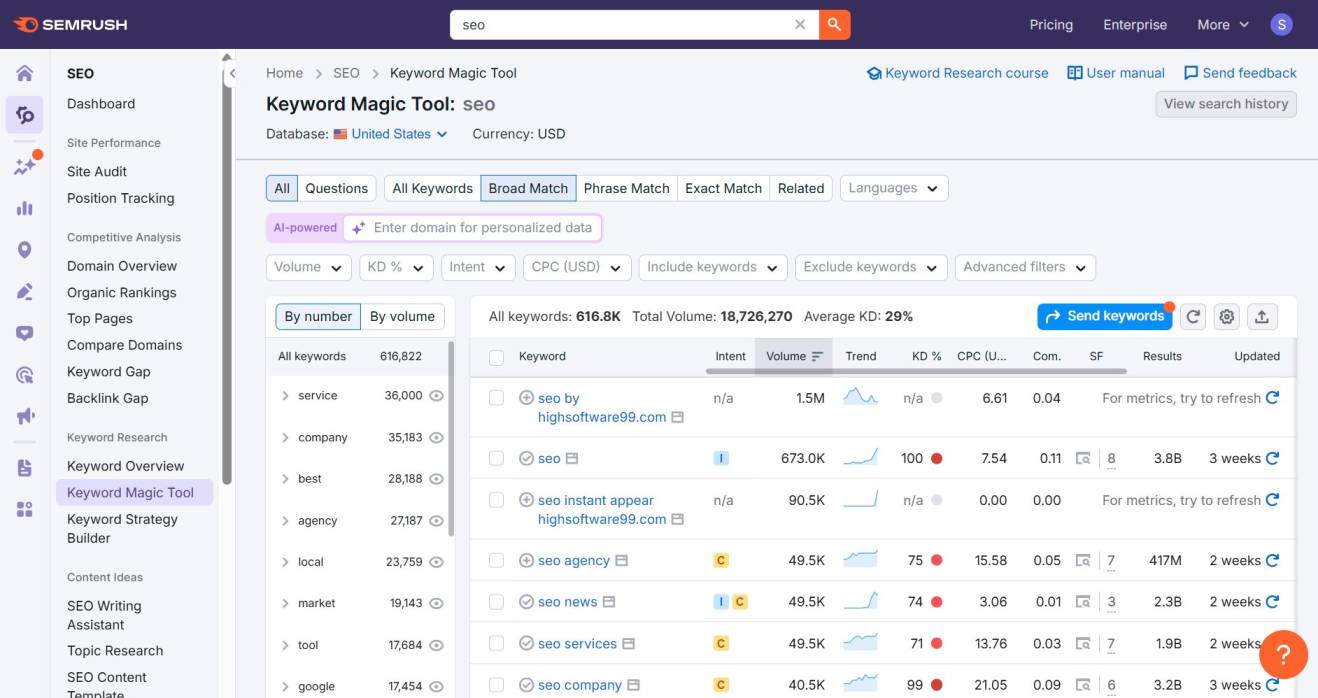
You can use tools like Google Keyword Planner, Ahrefs, or Semrush for this. Personally, I prefer using Semrush’s Keyword Magic Tool because it quickly surfaces thousands of relevant keyword ideas around a single topic.
Keyword Magic Tool by Semrush for the relevant keyword list
Here’s how I usually approach it. I enter a broad keyword related to my topic, for example, ‘SEO.’ The tool then returns an extensive list of related keywords along with important metrics. I mainly focus on three of them:
Search intent, to understand what the user is really looking for
Keyword Difficulty (KD%), to estimate how hard it is to rank
Search volume, to gauge demand
This combination helps me choose keywords that are realistic to rank for and meaningful for readers.
If you use Yoast SEO, this process becomes even easier. Semrush is integrated into Yoast SEO (both free and Premium), giving you keyword suggestions directly in Yoast SEO. With a single click, you can access relevant keyword data while writing, making it easier to create focused, useful content from the start.
Keyword research tells you what people search for. Questions tell you why they search.
When you actively look for the questions your audience is asking, you move closer to matching search intent. This is especially important in the AI era, where search engines and AI models prioritize clear, answer-driven content.
For example, consider these two queries:
What are the key features of good running shoes?
This shows informational intent. The searcher wants to understand what makes a running shoe good.
What are the best running shoes?
This suggests a transactional or commercial intent. The searcher is likely comparing options before making a purchase.
Both questions are valid, but they require very different content approaches.
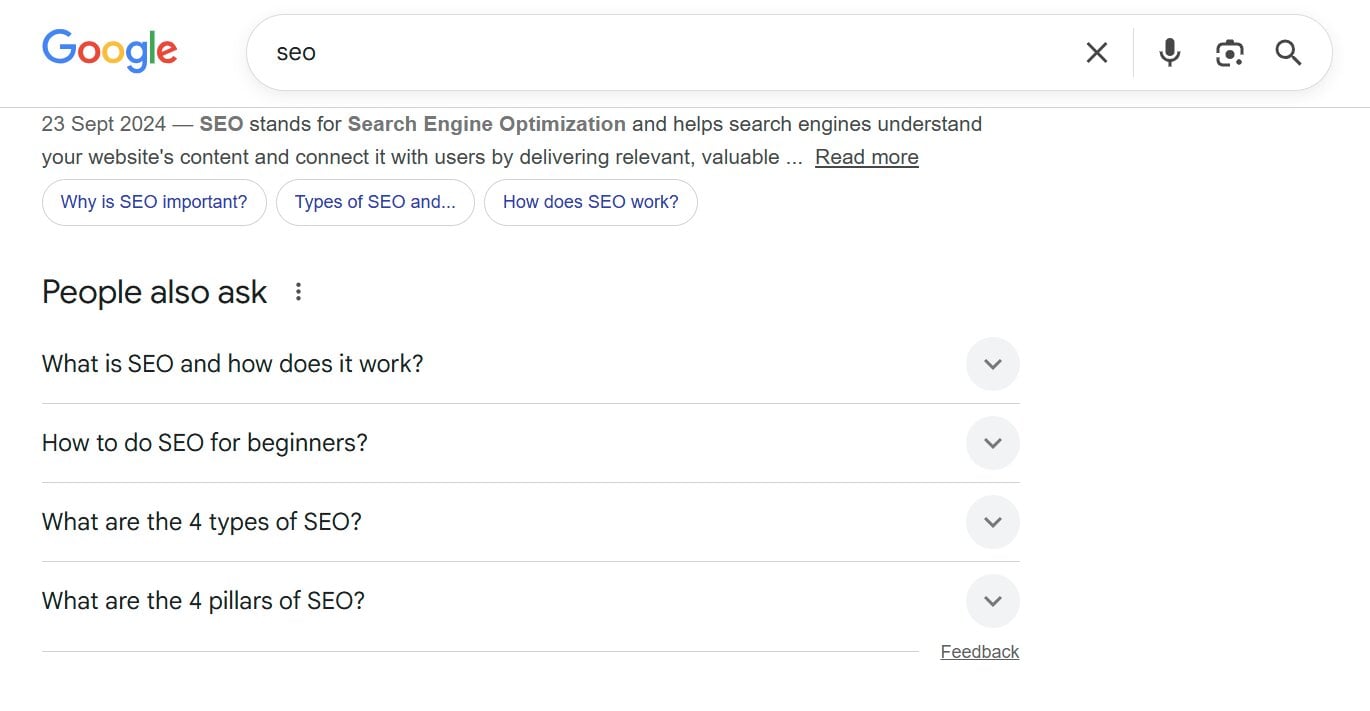
There are two simple ways I usually find relevant questions. The first is by checking the People also ask section in Google search results. By typing in a broad keyphrase, you can see related questions that Google itself considers relevant.
The People also ask section showing questions related to the broad keyphrase ‘SEO’
The second method is to use the Questions filter in Semrush’s Keyword Magic Tool. This helps uncover question-based queries directly tied to your main topic.
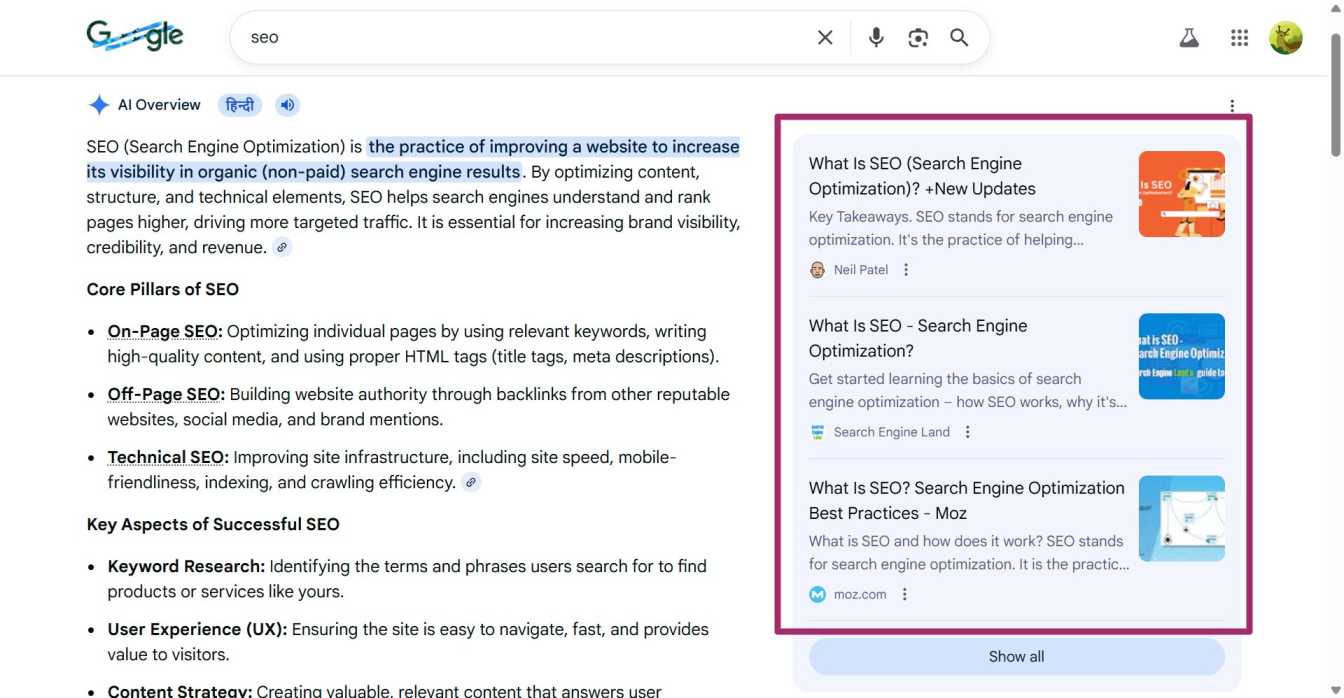
Apart from these methods, I also like using Google’s AI Overview and AI mode as a quick research layer. When I search for my main topic, I pay close attention to AI-cited sources, as they often surface broad questions people are actively seeking. The structured points and highlighted terms usually reflect the answers and subtopics that matter most to users. If I want to go deeper, I click “Show more,” which reveals additional angles and follow-up questions I might not have considered initially.
AI cited sources by Google AI Overview
Finding and answering these questions helps you do lightweight online audience research and create content that feels genuinely helpful. It also increases the chances of your blog post being referenced in AI-generated answers, since LLMs are designed to surface clear responses to specific questions.
3. Structure your content with headings and subheadings
In our 2026 SEO predictions, we highlighted that editorial quality is no longer just about good writing. It has become a machine-readability requirement. Content that is clearly structured is easier to understand, reuse, and surface across both search and AI-driven experiences.
How LLMs use headings
AI models rely on headings to identify topics, questions, and answers within a page. When your content is broken into clear sections, it becomes easier for them to extract key information and include it in AI-generated summaries.
Why headings still matter for SEO
Headings help search engines understand the hierarchy of your content and the main points you are trying to rank for. They also improve scannability and usability, especially on mobile devices, and increase the chances of earning featured snippets.
Good structure has always been a core SEO principle. In the AI era, it remains one of the simplest and most effective ways to improve visibility and discoverability.
4. Focus on readability aspects
An SEO-friendly blog post should be easy to read before it can rank or get picked up by AI systems. Readability helps readers stay engaged and helps search engines and AI models better understand your content.
A few key readability aspects to focus on while writing:
Avoid passive voice where possible Active sentences are clearer and more direct. They make it easier for readers to understand who is doing what, and they reduce ambiguity for AI systems processing your content.
Use transition words Transition words like “because,” “for example,” and “however” guide readers through your content. They improve flow and make it easier to follow relationships between sentences and paragraphs.
Keep sentences and paragraphs short Long, complex sentences reduce clarity. Breaking content into shorter sentences and paragraphs improves scannability and comprehension.
Avoid consecutive sentences starting in the same way Varying sentence structure keeps your writing engaging and prevents it from sounding repetitive or robotic.
The readability analysis in the Yoast SEO for WordPress metabox
If you are a WordPress or Shopify user, Yoast SEO (and Yoast SEO for Shopify for Shopify users) can help here. Its readability analysis checks for passive voice, transition words, sentence length, and other clarity signals while you write. If you prefer drafting in Google Docs, you can use the Yoast SEO Google Docs add-on to get the same readability feedback before publishing.
Use Yoast SEO in Google Docs
Optimize as you draft for SEO, inclusivity, and readability. The Yoast SEO Google Docs add-on lets you export content ready for WordPress, no reformatting required.
Good readability is not just about pleasing algorithms. It helps readers understand your message more quickly and makes your content easier to reuse in AI-generated responses.
5. Use inclusive language
Inclusive language helps ensure your content is respectful, clear, and welcoming to a broader audience. It avoids assumptions about gender, ability, age, or background, and focuses on people-first communication.
From an SEO and AI perspective, inclusive language also improves clarity. Content that avoids vague or biased terms is easier to interpret, digest, and trust. This directly supports brand perception, especially when your content is surfaced in AI-generated responses.
Yoast SEO supports this through its inclusive language check, which flags potentially non-inclusive terms and suggests better alternatives. This feature is available in Yoast SEO, Yoast SEO Premium, and in the Yoast SEO Google Docs add-on, making it easier to build inclusive habits directly into your writing workflow.
Inclusive language ensures your content is intentional, thoughtful, and clear, aligning closely with what modern SEO and AI systems value.
6. Add relevant media and interaction points
A well-written blog post should not feel like a long block of text. Adding the right media and interaction points helps guide readers through your content, keeps them engaged, and encourages them to take action.
Why media matters
Media elements such as images, videos, embeds, and infographics make your content easier to consume and more engaging. Blog posts that include images receive 94% more views than those without, simply because visuals break up large blocks of text and make pages easier to scan.
Video content plays an even bigger role. Embedded videos help explain complex ideas faster and can significantly improve organic visibility compared to text-only posts. Together, these elements encourage readers to stay longer on your page, which is a strong signal of content quality for search engines and AI systems alike.
Media also improves accessibility. Properly optimized images with descriptive alt text make content usable for screen readers, while original visuals, screenshots, or diagrams help reinforce credibility and expertise.
Use interaction points to guide and engage readers
Interaction does not always mean complex features. Even simple elements can significantly improve engagement when used well.
Table of contents and sidebar CTA used as interaction points in a Yoast blog post
A table of contents, for example, allows readers to jump directly to the section they care about most.
Other interaction points include clear calls to action (CTAs) that guide readers to the next step, relevant recommendations that encourage users to keep exploring your site, and social sharing buttons that make it easy to amplify your content. Interactive elements like polls, quizzes, or embedded tools further encourage participation and increase time on page.
7. Plan your content length
Content length still matters, but not in the way many people think it does.
A common question is what the ideal word count is for a blog post that performs well. A 2024 study by Backlinko found that while longer content tends to attract more backlinks, the average page ranking on Google’s first page contains around 1,500 words.
That said, this should not be treated as a fixed benchmark. The ideal length is the one that fully answers the user’s question. In an AI-driven era, publishing long content that adds little value or is padded with unnecessary fluff can do more harm than good.
If a topic genuinely requires a longer format, breaking the content into clear subheadings makes a big difference. I personally prefer structuring long articles this way because it improves readability, helps readers navigate the page more easily, and makes the content easier for search engines and AI systems to understand.
If you use Yoast SEO or Yoast SEO Premium, the paragraph and sentence length checks can help here. These checks exist to prevent pages from being too thin to provide real value. Pages with very low word counts often lack context and struggle to demonstrate relevance or expertise. Yoast SEO flags such cases as a warning, while clearly indicating that adding more words alone does not guarantee better rankings.
Think of word count as a guideline, not a goal. Your focus should always be on clarity, completeness, and usefulness.
8. Link to existing content
Internal linking is one of the most underrated SEO practices, yet it does a lot of heavy lifting behind the scenes.
By linking to relevant content within your site, you help readers discover additional resources and help search engines understand how your content is connected. Over time, this strengthens topical authority and signals that your site consistently covers a subject in depth.
Good internal linking follows a few simple principles:
Link only when it adds value and feels natural in context
Use clear, descriptive anchor text so users and search engines know what to expect
Avoid linking to outdated URLs or pages that redirect, as this wastes crawl signals
Internal links also keep readers engaged longer by guiding them to related articles. This improves overall site engagement while reinforcing your expertise on a topic.
From an AI and search perspective, internal linking plays an even bigger role. Modern search systems analyze content structure, metadata hierarchies, schema markup, and internal links to assess topical depth and clarity. Well-linked content clusters make it easier for search engines and AI systems to understand what your site is about and which pages are most important.
For WordPress users, Yoast SEO Premium offers internal linking suggestions directly in the editor. This makes it easier to spot relevant linking opportunities as you write, helping you build stronger content connections without interrupting your workflow.
A smarter analysis in Yoast SEO Premium
Yoast SEO Premium has a smart content analysis that helps you take your content to the next level!
9. Write compelling meta titles and descriptions
Meta titles and meta descriptions help users decide whether to click on your content. While meta descriptions are not a direct ranking factor, they strongly influence click-through rates, making them an essential part of writing SEO-friendly blog posts.
A good meta title clearly communicates what the page is about. Place your main keyword near the beginning, keep it concise, and aim for roughly 55-60 characters so it doesn’t get truncated in search results.
Meta descriptions act like a short invitation. They should explain what the reader will gain from clicking and why it matters. Instead of stuffing keywords, focus on clarity and usefulness. Mention what aspects of the topic your content covers and how it helps the reader. Simple language works best.
Pro tip: Using action-oriented verbs such as “learn,” “discover,” or “read” can also encourage clicks and make your description more engaging.
If you use Yoast SEO Premium, this process becomes much easier. The AI-powered meta title and description generation feature helps you create relevant, well-structured metadata in just one click. It follows SEO best practices while producing descriptions and titles that are clear, engaging, and aligned with search intent.
Bonus tips
Once you have the fundamentals in place, a few extra refinements can go a long way. The following bonus tips help improve usability, clarity, and long-term discoverability. They are not mandatory, but when applied thoughtfully, they can make your blog posts more helpful for readers and easier to surface across search engines and AI-driven experiences.
1. Add a table of contents
A table of contents (TOC) helps readers quickly understand what your blog post covers and jump straight to the section they care about. This is especially useful for long-form content, where users often scan rather than scroll from top to bottom.
From an SEO perspective, a TOC improves structure and readability and can create jump links in search results, which may increase click-through rates. It reduces bounce rates by helping users find answers faster and improves accessibility by offering clear navigation.
By the way, did you know Yoast can help you here too? Yes, the Yoast SEO Internal linking blocks feature lets you add a TOC block to your blog post that automatically includes all the headings with just one click!
2. Add key takeaways
Key takeaways help readers quickly grasp the main points of your blog post without having to read the whole post. This is especially helpful for time-constrained users who want quick, actionable insights.
Summaries also support SEO by reinforcing topic relevance and improving content comprehension for search engines and AI systems. Well-written takeaways might increase visibility in featured snippets and “People also ask” results.
If you use Yoast SEO Premium, the Yoast AI Summarize feature can generate key takeaways for your content in just one click, making it easier to add concise summaries without extra effort.
3. Add an FAQ section
An FAQ section gives you space to answer specific questions your readers may still have after reading your post. This improves user experience by addressing concerns directly and building trust.
FAQs also help search engines better understand your content by clearly outlining common questions and answers related to your topic. While they can support rankings, their real value lies in reducing friction, improving clarity, and even supporting conversions by clearing doubts.
4. Short permalinks
A permalink is the permanent URL of your blog post. Short, descriptive permalinks are easier to read, easier to share, and more likely to be clicked.
Good permalinks clearly describe what the page is about, avoid unnecessary words, and include the main topic where relevant. They improve usability and help search engines understand page context at a glance.
5. Focus on building authority (EEAT aspect)
Building authority is critical, especially for sites that cover sensitive or high-impact topics. Demonstrating Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T) helps both users and search engines trust your content.
This includes citing reliable sources, showing real-world experience, maintaining consistent quality, and clearly communicating who is behind the content. Strong E-E-A-T signals are especially important for YMYL topics, where accuracy and credibility matter most.
6. Plan content distribution
Writing a great blog post is only half the work. Distribution helps your content reach the right audience.
Sharing posts on social media, repurposing key insights into newsletters, and earning backlinks from relevant sites can drive more traffic and visibility. Distribution also increases engagement signals and helps your content gain traction faster, which supports long-term SEO performance.
Target your readers always!
In AI-driven search, retrieval beats ranking. Clarity, structure, and language alignment now decide if your content gets seen. – Carolyn Shelby
This perfectly sums up what writing SEO-friendly blog posts looks like today. Success is no longer just about rankings. It is about being clear, helpful, and easy to understand for both readers and AI systems.
Throughout this guide, we focused on the fundamentals that still matter: understanding search intent, structuring content well, improving readability, using inclusive language, and supporting your writing with media, internal links, and thoughtful metadata. These are not new tricks. They are strong SEO foundations, adapted for how search and discovery work in the AI era.
If there is one takeaway, it is this: always write for your readers first. When your content genuinely helps people, answers their questions, and respects how they search and read, it naturally becomes easier to surface across SERPs and AI-driven experiences.
Good SEO has not changed. It has simply become more human.
I’m a Computer Science grad who accidentally stumbled into writing—and stayed because I fell in love with it. Over the past six years, I’ve been deep in the world of SEO and tech content, turning jargon into stories that actually make sense. When I’m not writing, you’ll probably find me lifting weights to balance my love for food (because yes, gym and biryani can coexist) or catching up with friends over a good cup of chai.
Welcome to the week’s Pulse: updates affect what Google considers spam, what happens when you report it, and what agentic search looks like in practice.
Here’s what matters for you and your work.
Google’s New Spam Policy Targets Back Button Hijacking
Google added back button hijacking to its spam policies, with enforcement beginning June 15. The behavior is now an explicit violation under the malicious practices category.
Key facts: Back button hijacking occurs when a site interferes with browser navigation and prevents users from returning to the previous page. Pages engaging in the behavior face manual spam actions or automated demotions.
Why This Matters
Google called out that some back button hijacking originates from included libraries or advertising platforms, which means the liability sits with the publisher even when the behavior comes from a vendor.
You have two months to audit every script running on your site, including ad libraries and recommendation widgets you didn’t write yourself.
Sites that receive a manual action after June 15 can submit a reconsideration request through Search Console once the offending code is removed.
What SEO Professionals Are Saying
Daniel Foley Carter, SEO Consultant, summed up the community reaction on LinkedIn:
“So basically, that spammy thing you do to try and stop users leaving? Yeah, don’t do it.”
Manish Chauhan, SEO Head at Groww, added on LinkedIn that he was:
“glad this is being addressed. It always felt like a short-term hack for pageviews at the cost of user trust.”
Google updated its report-a-spam documentation on April 14 to say user submissions may now trigger manual actions against sites found violating spam policies. The previous guidance said spam reports were used to improve spam detection systems rather than to take direct action.
Key facts: Google may use spam reports to take manual action against violations. If Google issues a manual action, the report text is sent verbatim to the reported website through Search Console.
Why This Matters
Google now states that spam reports can be used to initiate manual actions, making reports explicitly part of its enforcement process in official documentation.
This also raises concerns about potential abuse, as grudge reports and competitor sabotage may become more appealing when reports have a tangible impact. Therefore, the true test will be the quality of reports that Google actually considers.
What SEO Professionals Are Saying
Gagan Ghotra, SEO Consultant, wrote on LinkedIn about why the change may lead to better reports:
“Now spam reports have direct relation to Google issuing manual actions against domains. Google announced if there is a spam report from a user and based upon that report Google decide to issue manual action against a domain then Google will just send the user submitted content in report to the site owner (Search Console – Manual Action report) and will ask them to fix those things. Seems like Google was getting too many generic spam reports and now as the incentive to report are aligned. That’s why I guess people are going to submit reports which have a lot of relevant information detailing why/how a specific site is violating Google’s spam policies.”
Google expanded agentic restaurant booking in AI Mode to additional markets on April 10, including the UK and India. Robby Stein, VP of Product for Google Search, announced the rollout on X.
Key facts: Searchers can describe group size, time, and preferences to AI Mode, which scans booking platforms simultaneously for real-time availability. The booking itself is completed through Google partners rather than directly on restaurant websites.
Why This Matters
Restaurant booking shows how task completion within search works. For local SEOs and marketers, traffic patterns shift: users now often stay within Google during discovery, with bookings routed through partners.
This depends on Google booking partners, which may limit visibility for restaurants outside those platforms, making presence on Google-supported booking sites more important than the restaurant’s own website. This model may or may not extend to other experiences.
What SEO Professionals Are Saying
Glenn Gabe, SEO and AI Search Consultant at G-Squared Interactive, flagged the rollout on X:
I feel like this is flying under the radar -> Google rolls out worldwide agentic restaurant booking via AI Mode. TBH, not sure how many people would use this in AI Mode versus directly in Google Maps or Search (where you can already make a reservation), but it does show how Google is moving quickly to scale agentic actions.
Aleyda Solís, SEO Consultant and Founder at Orainti, noted a key limitation in a LinkedIn post:
“Google expands agentic restaurant booking in AI Mode globally: You still need to complete the booking via Google partners though.”
What counts as spam, what happens when spam gets reported, and what agentic search looks like all got clearer definitions this week.
Back button hijacking becomes a named violation with an enforcement date. Google’s documentation now says spam reports may be used for manual actions, not just fed into detection systems. Agentic search becomes a live product for restaurant reservations in specific markets rather than a talking point about the future.
Now, the compliance work, reporting mechanics, and agentic experience are all clearly understood enough to be tracked directly, instead of just forecasted.
For years, many advertisers treated product feeds as a channel task tied mainly to Shopping campaigns.
If you were running Shopping ads, feed optimization likely got attention. If you weren’t, it often slipped behind priorities for the PPC campaigns you were running.
Now, that approach is starting to show its age.
Google’s recent Ads Decoded podcast episode suggests that mindset may need to change. Product data was discussed in connection with free listings, AI-powered search experiences, YouTube formats, Lens, virtual try-on, and newer e-commerce surfaces still evolving.
That reflects a much broader role than many advertisers have historically assigned to their feed.
Google appears to be positioning product data as a larger part of how products are discovered across its platforms, not just how Shopping campaigns perform.
Advertisers who still view Merchant Center as a side task may be underestimating how much visibility now starts with product data.
The more interesting question is what that shift tells us about where Google wants retail advertising to go next.
Merchant Center Is Starting To Look Like Retail Infrastructure
What stood out most in the podcast was how broadly Google described the role of Merchant Center data.
Nadja Bissinger, General Product Manager of Retail on YouTube, described Merchant Center feeds as the “backbone that powers organic and ads experiences,” adding that merchants should submit the most robust product data possible to increase discoverability.
That is a wider role than many advertisers have traditionally associated with Merchant Center.
Google said in a 2025 retail insights piece that people shop across Google more than 1 billion times per day. It also highlighted Search, YouTube, Maps, and visual discovery as key parts of modern shopping journeys. That helps explain why reusable product data is becoming more valuable than channel-specific assets alone.
Google also said Google Lens now sees more than 20 billion visual searches per month, and 1 in 4 Lens searches carry commercial intent. That is another signal that structured product data is becoming more important outside traditional Shopping ads.
For years, many brands viewed Merchant Center as a necessary setup for Shopping campaigns. Google now appears to be positioning it as a core input for how products are surfaced across its platforms.
That should change how feed work is prioritized internally.
Feed optimization is no longer just a PPC responsibility. It can influence:
Organic visibility
Merchandising strategy
Creative presentation
Promotions
How products appear in newer AI-led experiences.
For larger organizations, that may require closer coordination between paid media, SEO, e-commerce, merchandising, and product teams.
For smaller brands, it may be as simple as giving feed quality the same level of attention already given to ad copy, landing pages, and campaign structure.
Many advertisers still treat feed work as cleanup work. That mindset is becoming expensive as product data plays a larger role in who gets seen across Google.
Why Is Google Pushing Product Data So Hard Right Now?
Google’s direction here makes sense when you look at where its retail products are heading.
The company wants more e-commerce activity to happen across Search, YouTube, Maps, AI experiences, and future agentic tools. To support that expansion, it needs merchant data that is accurate, structured, and easy to reuse across different surfaces (as Google refers to them as).
Google has financial reasons to expand e-commerce activity beyond traditional ad clicks. In their 2025 Q4 Earnings Release, they reported a 17% growth in Google Search, and YouTube revenue across ads and subscriptions over $60 billion.
A strong feed helps Google understand:
What a product is
Who it is for
What makes it different
Where it is available
What it costs
How the product should be presented
That matters even more as retail experiences, paid or organic, become more visual, more personalized, and more automated.
Traditional search ads leaned heavily on keywords, headlines, and landing pages. Newer e-commerce formats can also depend on product images, attributes, ratings, promotions, availability, shipping details, and other feed inputs that help match products to user intent.
Better data can lead to better experiences for users. It can also create more places where merchants can appear across Google’s properties.
Google is building more e-commerce surfaces, and product data is the fuel behind them. Advertisers who ignore that may keep optimizing campaigns while missing the larger shift happening around them.
Is Google Prepping For A More Strategic Shift?
From my perspective, there is a larger strategic shift behind Google’s product data push.
I don’t see this as a routine push for better feeds or cleaner campaign inputs. I see Google working to become more of a growth engine for advertisers, with a role that reaches beyond media buying and campaign delivery.
That expansion is moving into areas that shape business performance, including merchandising, product discovery, pricing visibility, local commerce, measurement, and newer purchase-ready experiences.
Google is not only trying to improve how ads run. It appears to be building a deeper position in how products are surfaced, how demand is created, how buying decisions are influenced, and how performance is measured.
My view is that the more Google becomes embedded across those moments, the more connected it becomes to broader business growth rather than media performance alone.
Why Many Advertisers Are Still Measuring Feed Value Wrong
One reason feed optimization still gets deprioritized is simple: many teams are using an outdated scorecard.
Google cited a 33% conversion uplift for advertisers using Demand Gen with product feeds during the podcast discussion. Even if results vary by account, it is another sign that feed quality is being tied to campaign types beyond classic Shopping ads.
If the main question is whether Shopping ROAS improved last week, it becomes easy to undervalue the broader impact of stronger product data.
That measurement approach came from a time when feeds were more closely tied to Shopping campaigns. Google is now using the same data across a much wider set of retail experiences, including discovery surfaces, visual placements, AI-led results, and other formats that do not fit neatly into one campaign report.
That creates a gap between where feed work adds value and where many teams are looking for it.
A stronger title may improve discoverability. Better imagery can increase engagement in visual placements. Accurate pricing and promotions can improve click appeal. Richer attributes can help Google better understand relevance. Availability data can support local and omnichannel visibility.
Those gains may show up across multiple touchpoints, assisted paths, and blended performance trends rather than one Shopping dashboard.
That is why some advertisers continue to underinvest in feed quality. The value is there, but their reporting model was built for an earlier version of Google.
As Google expands where products can appear, feed optimization deserves to be measured more like a visibility and growth lever, not just a Shopping maintenance task.
One of the more important quotes from the podcast came from Ginny Marvin, Google Ads Liaison, as she wrapped up the episode:
Merchants with the most structured, high quality data foundations will be positioned to win.
Winning will not come from uploading a feed once and forgetting about it for months at a time.
It comes from treating product data as an ongoing optimization just like your existing campaigns.
What Google’s AI Max Focus May Be Signaling About Search
One of the more revealing parts of the podcast was how often Search strategy was discussed through the lens of AI Max for Search, while traditional standard Search campaigns were barely mentioned.
During the episode, Firas Yaghi, Global Product Lead for Retail Solutions, talked about how advertisers should be thinking about different campaign types:
I think the role of each campaign really depends on your high level objective. Whether you’re prioritizing cross channel efficiency, granular control or hybrid approach that balances top line sales with OKRs.
He mentioned a lot around Performance Max, Demand Gen, with a little bit of AI Max for Search.
I would avoid treating that as proof that standard Search is going away. There is still clear value in campaigns built around tighter search control, brand protection, and proven high-intent terms.
At the same time, it’s hard to ignore the direction of Google’s messaging.
When Google talks about growth, expansion, and newer retail opportunities, the conversation increasingly centers on AI-assisted campaign types. We have seen similar signals elsewhere, including Google’s announcement that Dynamic Search Ads will upgrade into AI Max for Search and that AI Max represents the next step for search expansion.
My read is that standard Search remains important, but it is no longer the only story Google wants advertisers thinking about.
The company appears to be steering incremental growth toward campaign types that rely on broader matching, stronger inputs, automation, and first-party signals.
I think that Search strategies built around legacy structures will become less competitive over time. I’m not confident enough yet to say that standard Search campaigns will go away completely in the near future, but the increasing signals around keyword-less technology has me thinking more changes for Search campaigns are bound to happen.
What This Means For Your Campaigns
The bigger risk for PPC managers is assuming the teams responsible for merchandising or product data already understand how much feed quality can affect campaign performance.
In many organizations, merchandising, e-commerce, product, or development teams control what goes into Merchant Center. Their priorities may be centered on inventory, pricing, site operations, or category management, not media efficiency or visibility across Google.
That is where PPC managers can add real value.
If product information is influencing how products appear across paid, organic, and AI-led surfaces, someone needs to connect those decisions to marketing outcomes. PPC managers are often in the best position to do that because they can see changes in impressions, traffic quality, conversion trends, and missed opportunities firsthand.
That may mean bringing examples into weekly meetings, showing where missing attributes are limiting reach, flagging weak imagery, highlighting pricing issues, or sharing results from tests that improved performance.
You may not own the feed, but you can help the business understand why it deserves greater priority and where better inputs can improve campaign results.
Put More Focus On Inputs That Can Scale Performance
Many teams spend valuable time on small bid changes, minor budget moves, or endless rounds of creative tweaks while core product data remains incomplete or outdated.
Those tasks still have value, but the upside is often limited when the underlying product information is weak.
If titles are thin, images are poor, attributes are missing, or product details are outdated, fixing those gaps may create more value than another round of minor account adjustments.
Add Feed Health To Regular Performance Reviews
Most reporting cycles focus on spend, ROAS, CPA, and conversion volume.
Those metrics are important, but they do not always show whether product data is helping or limiting visibility.
Feed health deserves a place in regular reviews. Look at disapprovals, missing fields, image quality, pricing accuracy, promotional coverage, and product-level gaps with the same discipline used for media metrics.
Broaden How You Test For Growth
Many retail accounts still treat Search, Shopping, YouTube, and newer campaign types as separate lanes.
Google’s recent direction suggests those lines are becoming less rigid.
Growth testing should include where products can appear across newer surfaces, how feeds support Demand Gen and AI-led placements, and whether stronger product data can unlock reach that existing campaigns are not capturing today.
Treat Better Product Data As A Competitive Advantage
Some advertisers will wait until these newer placements are fully mature before investing seriously in feed quality.
While that delay may be costly for them, your proactiveness can pay off significantly.
What PPC Professionals Are Saying
Recent LinkedIn discussions suggest many practitioners are viewing feed quality as a larger performance lever.
Comments from the podcast episode have been overall positive and has many marketers agreeing that feed management needs to be routine.
Really interesting to see how something that used to feel mostly like ad ops plumbing is now becoming core infra for AI commerce.
Sophie Westall had similar sentiments, stating that “feed quality is quickly becoming a core part of overall media strategy, not just a hygiene task.”
In a recent LinkedIn post, Menachem Ani said that by fixing a product feed, “campaigns start working harder without touching a single bid.”
More marketers appear to be focusing less on isolated settings and more on the quality of the data – regardless if they’re running paid campaigns or not.
What Comes Next For Retail Marketers
Some advertisers will hear Google’s renewed focus on product data and assume it mainly matters for brands running Shopping campaigns.
That interpretation misses how much wider the opportunity has become.
Google is quickly expanding how products can show up across paid placements, organic surfaces, visual experiences, and newer AI-led formats. As that happens, feed quality becomes more connected to visibility and performance than many teams have historically assumed.
In many organizations, product data still gets treated as maintenance work. It gets attention when something breaks or when Shopping results decline, then falls back down the priority list.
That approach may be harder to justify going forward.
Product data needs a larger role in planning, testing, and cross-functional discussions because it can influence far more than one campaign type.
When the covid-19 pandemic started, Jennifer Phillips thought about the songs of the sparrows.
They were easier to hear, because the world had suddenly become quieter. Car traffic plummeted as people sheltered at home and shifted to remote work. Air travel collapsed. Cities—normally filled with the honking, screeching, engine-gunning riot of transportation—became as silent as tombs.
For years, Phillips has studied how animals react to “anthropogenic noise,” or the racket created by human activity. Most animals really don’t like it, she and her colleagues have learned. Animals constantly listen to the world around them: They’re on the alert for the rustle of approaching predators, or a mating call from a member of their species. As human society has expanded—with sprawling cities, industrial mines, and roads crisscrossing the world—it has gotten noisier too, and animals have trouble hearing one another.
Noise is invisible; there’s no billowing smokestack, no soiled waterway. We just got used to it as it vibrated in the background.
Phillips and her colleagues had spent time in the 2010s in San Francisco recording the sound of white-crowned sparrows in the Presidio. It’s a park that is half peaceful nature and half automobile noise, since it’s filled with thick clumps of trees and grassy fields but also has two highways that slice through it, feeding onto the Golden Gate Bridge. In past recordings, starting in the 1950s, sparrows had sung with complex and lower-pitched melodies and three major “dialects.” But by the 2010s, traffic in the Presidio had exploded, and the hubbub was so loud that the birds began to sing with faster trills—and at a higher pitch—so their fellows could hear them. The two quietest dialects were either dead or on their way to extinction.
They’re “screaming at the top of their lungs,” says Phillips. “They really can’t hear the lower frequencies when the traffic noise is present.” Urban noise can even change birds’ bodies; they get thinner and more stressed out. Their mating calls aren’t as effective, because female birds, as researchers have found, generally don’t enjoy high-pitched, high-volume shouting. (It makes them wonder if the males are unhealthy.) The noise can increase bird-on-bird conflict, because when birds can’t hear warning cries they accidentally stumble into enemy territory. Perhaps worst of all, in situations like these biodiversity takes a hit: Entire species that can’t handle urban clamor simply head out of town and never come back.
But as the sudden, eerie silence of the pandemic descended, Phillips sat at home thinking, It’s really quiet. And then she wondered: Would the Presidio birds now be able to hear each other better?
She raced over to the park and started recording. Sure enough, the park was seven decibels quieter—a huge drop. (That’s like the difference between the noise of the average home and whispering.)
And remarkably, the researchers found that the songs of the white-crowned sparrows had transformed. They were singing more quietly, with a richer range of frequencies. A bird could be heard twice as far as before. And the mating calls had gotten more sultry.
“They could sing a higher performance, basically a sexier song, but not have to scream it so loud,” Phillips says.
It was as if time had been reversed and all the damage abruptly repaired. And it proved what Phillips and her peers have been increasingly documenting: that anthropogenic noise is the newest form of pollution we need to tackle. The noise of our relentlessly on-the-move industrial society affects all life on Earth, wildlife and humans, in ways we’re just beginning to grasp. Yet strategies such as electrification and clever urban design could help. As the Presidio showed, noise can vanish overnight—once we figure out how to shut up.
Hidden impacts
Many forms of pollution are obvious to us humans. Dumping toxic goo into lakes? Sure, that’s bad. Coal smokestacks pumping soot and carbon dioxide, plastic bags and sea nets choking whales—we now understand that these, too, are problems. Even an idea as gauzy as light pollution has penetrated the public consciousness to some extent, since it’s why city dwellers can’t see many stars, and we’ve heard it confuses migratory birds.
But noise, mostly from transportation, took longer to hit our radar. This is partly because it’s invisible; there’s no billowing smokestack, no soiled waterway. We just got used to it as it vibrated in the background.
Sparrows in San Francisco’s Presidio began to sing with faster trills—and at a higher pitch—so their fellows could hear them over the noise of nearby traffic.
GETTY IMAGES
The black-chinned hummingbird seems to prefer noisy areas, fledging more chicks than the same species does in quieter areas.
MDF/WIKIMEDIA COMMONS
There were a few studies in the ’70s and ’80s showing that animals were upset by our noise. But the field really began to take off in the ’00s, in part because digital technology made it easier to record long swathes of sound out in nature and analyze them. One early salvo came from the biologist Hans Slabbekoorn, who was studying doves in the city of Leiden and irritatedly noticed that he could rarely get a clean recording because of the background noise. Sometimes he’d see the doves’ throats moving as they cooed but couldn’t hear them. “If I’m having difficulty hearing them,” he thought, “what about them?”
So he and a colleague started recording ambient sound levels in different parts of Leiden. Some were quiet residential areas, which registered a soothing 42 decibels, and others were noisy intersections or areas near highways, which reached 63 decibels, about as loud as background music. Sure enough, he found that birds in the noisy areas were singing at a higher pitch.
Over the next two decades, research in the field bloomed. Noise, the scientists found, has a few common ill effects on animals. It disrupts communication, certainly. But it also generally stresses them, reducing everything from their body weight to their receptivity to mating calls. If an animal nests closer to a road, its reproduction rates can go down; eastern bluebirds, for example, produce fewer fledglings. Truly cacophonous noise—like planes taking off at a nearby airport—can cause hearing loss in birds. And animals can wind up becoming less aware of threats from predators. They’ll wander closer to danger, because they can’t hear it coming. (And sometimes they’ll do the opposite: They’ll develop a rageaholic hair-trigger temper, because they’re constantly on high alert and regard everything as a threat.)
Even in deep rural areas, where things are normally pretty quiet, highways can disrupt wildlife—the noise carries far into the fields nearby. Fraser Shilling, a biologist at the University of California, Davis, has stood up to half a mile from rural highways and recorded sound as loud as 60 decibels, which is at least 20 decibels higher than you’d typically find in the wilderness. “The motorcycles and the 18-wheelers are really the ones that project a lot of noise,” he told me.
Above 55 decibels, many skittish animals get into a fight-or-flight panic. The prevalence of bobcats—an endangered species famously rattled by noise—“starts dropping off the cliff,” says Shilling. Above 65, “you’re really starting to exclude almost all wildlife.”
And that’s not even the upper limit of what wildlife is exposed to. There are roughly a half-million natural-gas wells around the US, and piercingly loud compressors are used to shoot water down into most of them. Up close, the compressors can kick out 95 decibels, a sound as loud as a subway train; at one Wyoming gas well the sound still registered around 48 decibels nearly a quarter-mile away.
Historically, it wasn’t always easy to prove that noise was causing whatever problems the animals were experiencing. Maybe it was other factors; maybe animal populations reduce near a road because some are hit by vehicles?
But several clever experiments have proved that noise—and noise alone—can disrupt wildlife. One was the “phantom road” experiment by the conservation scientist Jesse Barber and his team, then at Boise State University. They went out to a quiet, uninhabited area of the Boise foothills in Idaho, far away from any roads. In this valley in the mountains, thousands of migratory birds stop on their way south each year; they’ll gorge themselves on cherry bushes, gaining weight for the next days of flying. The researchers strapped 15 pairs of speakers to Douglas fir trees, in a half-kilometer line. Then they blasted recordings of highway noise. They played the noise for four days and then turned it off for four days. Then they observed thousands of birds, capturing many to measure their body mass.
The noise truly rattled the birds. When the sound was turned on, nearly a third left the area. Those that stuck around ate less: While birds should be heavier after a day of foraging, these ones didn’t gain much. The noise seemed to have so interrupted their feeding that they weren’t packing on the weight needed for their migratory trip.
Other, similarly nifty A/B tests followed. One was led by David Luther, a biologist at George Mason University (who also worked with Phillips on the covid-19 study in San Francisco). In 2015, these researchers took 17 white-crowned sparrows at birth and raised them in a lab. To teach them their species’ songs, they played the nestlings recordings of adult sparrows singing, at low and high pitches. Six of the nestlings heard the songs without any interference; with the other half, the researchers played the sounds of city noise at the same time.
The results were stark. The lucky birds that were spared the traffic noise learned to perform the quieter, sweeter, more complex songs. But the birds that had traffic noise blasted learned only the higher, faster, more stressed-out songs. From the cradle, noise changed the way they communicated.
Humans hate noise too
You can’t pull the same experiment with humans, raising them in a lab to see how noise affects them. (Not ethically, anyway.) But if we could, we’d likely find the same thing. We, too, are animals—and it appears that we suffer in similar ways from anthropogenic noise, even though we’re the ones creating it.
The sound of traffic is correlated with lousy sleep, higher blood pressure, more heart disease, and higher stress.
Stacks of research in the last few decades have found that noise—most often, as with wildlife, the sound of traffic—is correlated with lousy sleep, higher blood pressure, more heart disease, and higher stress. A Danish study followed almost 25,000 nurses for years and found that an additional 10 decibels hit them hard; over a 23-year period they had an 8% higher rate of death, plus higher rates of nearly every bad thing that could happen to you: cancers, psychiatric problems, strokes. (They controlled for other malign health influences.) As you’d probably predict by now, children fare badly too. When Barcelona researchers followed almost 3,000 elementary school kids for a year, they found that those in noisier schools performed worse on assessments of working memory and ability to pay attention.
“We think of ourselves as being ‘used to it,’” says Gail Patricelli, a professor of evolution and ecology at the University of California, Davis. “We’re not as used to it as we think we are.”
It’s also true that there’s a trade-off. Many people understand that noise from cities and highways is aggravating, but we tolerate it because we get benefits along with the hassles. Cities are crammed with jobs and connections and dating opportunities; cars and trucks bring us the things we need and increase our personal mobility.
It turns out that animals make a similar calculus. Some species appear to benefit in certain ways from proximity to noise, so they move toward it.
Clinton Francis, a biologist at California Polytechnic State University, and a team studied bird populations near noisy gas wells in rural New Mexico. Most species avoided the riot of the well pumps. But Francis was surprised to find that some hummingbirds and finches preferred it, and by one important measure they thrived: They were nesting more in the noisy areas than in the quieter areas. Additionally, several species had more success at fledging chicks in noisier locations.
What was going on? It’s likely that the noise makes it harder for predators to hear the birds and hunt down their nests. “It’s essentially a predator shield,” Francis says. Since his research found that predators can cause as much as 76% of failures of eggs to produce healthy offspring, that’s a significant survival advantage.
Cities can offer the same protections to certain species. Consider the case of Flaco, a Eurasian eagle-owl that escaped from the Central Park Zoo in February of 2023 and found he was in a terrific place to hunt. The incessant traffic ought to have caused him trouble. “An owl like this is among the most vulnerable species to intrusions from noise pollution. They’re listening for extremely faint signals or cues that their prey provide,” Francis notes. But New York has its compensations, because prey animals abound. They’re also naïve and unguarded, never expecting an owl with a six-foot wingspan to swoop down and devour them.
EDDIE GUY
Granted, these upsides don’t cancel out the negatives. Human noise may shield some birds from predators, but in other ways it leaves them faintly miserable, with high levels of stress hormones and lower weight.
Worse, the species that manage to thrive in cities or near highways are often the same ones all over the country. And they represent only a minority of species; most are driven further away, with less and less land to live on as civilization spreads ever outward.
“Overall, it’s kind of a nightmare for diversity,” says Luther.
How to silence the world
In the early ’00s, the village of Alverna in the Netherlands began to get louder. A major intercity road cut straight through the town, and traffic had gone up by two-thirds in the previous decade. Facing complaints about the din, the town offered to put up some 13-foot walls on either side of the route. Residents hated the idea. Who wants to look out the window at massive walls?
So instead town planners redesigned the road in subtle ways. They lowered it by half a meter, slightly blocking the tire sounds. They built wedges that rise up three feet on either side, and surfaced them with attractive antique stone; that blocked even more sound. They planted sound-absorbing trees. And as a final coup de grâce, they reduced the speed limit from about 50 to 30 miles per hour. When a car is moving slowly, the engine is producing most of the roar—but once it’s going 45 mph or faster, the rumble of tires on the pavement takes over and is much louder. Each intervention had only a small effect, but cumulatively they made the road a blessed 10 decibels quieter.
This tale illustrates one curious upside of noise. Compared with other forms of pollution, it can be ended quickly. Toxic pollutants or CO2 can hang around for tens of thousands of years; the microplastics in your pancreas are probably never coming out. But with noise, the instant you reduce the source, the benefits are immediate.
Plus, most of what works is “not rocket science,” Shilling says. A tall wall at the side of a highway will cut noise by 10 decibels; fill a double-sided wall with rubble and it’s even better. That could cut the traffic noise to below 55 decibels, he notes, which would help particularly skittish forms of wildlife. Walls can block animal movement, though, so in animal-heavy areas it’s better to build berms—small hills on either side of a highway. Areas of high ecological importance could be prioritized to keep costs down.
“If there’s a great chunk of wetland habitat and it’s the only one around for 50 miles in any direction? Well, then we should build noise walls around it,” he says. We should also build overpasses and underpasses to help animals get around. And to quiet the din of gas wells out in the countryside, states could require companies to build walls around them. (They’ll likely only do that, though, when human neighbors complain or launch lawsuits; animals don’t have lawyers.)
Cities, too, can learn to shut up, as Alverna proved. At the most ambitious, some have buried noisy highways that once cut through the downtown core. Boston put a massive elevated highway underground in its “Big Dig”; in Slabbekoorn’s hometown of Amstelveen—a suburb of Amsterdam—they’re currently enclosing the A9 highway in a tunnel and turning the surface into a verdant park with new buildings. “That’s amazing, getting back a lot of the space as well,” he says.
Granted, this sort of reengineering can be brutally expensive, which is why politicians blanch when they’re asked to reduce road noise. The Big Dig cost $15 billion, and with interest up to $24 billion. When I mentioned cost to Shilling, he sighed. “It’s not as expensive as a B-1 bomber or tax cuts for rich people,” he says. “Environmental stuff is considered expensive just because our expectations are low, not because we can’t afford to do it.”
There are cheaper and more politically palatable fixes, though. Reducing urban speed limits is one; Paris recently cut the top speed on its ring roads from 70 to 50 kilometers per hour (43 to 31 mph), and noise at night went down by an average 2.7 decibels—a noticeable drop. Planting more trees and vegetation all around roads and cities can cut a few decibels more, and residents love it.
Growing adoption of electricity would also bring down the volume. “Electric vehicles of all kinds have the potential to make a big difference,” Patricelli says; when the light turns green and an EV next to you accelerates away, it’s up to 13 decibels quieter than a comparable gas-powered vehicle. These benefits won’t be felt as much on highways, because EVs still make tire noise at high speeds. But in the slower stop-and-go traffic of urban life, they are far more pleasant to the ears, both animal and human. Indeed, the electrification of everything that currently uses a gas-powered motor will make urban life quieter. Cities like Alameda, California, and Alexandria, Virginia, are increasingly banning gas-powered leaf blowers and lawn mowers, which operate at hair-raising volume while electric ones whisper along.
We’ve engineered a civilization that roars, but the next phase is making it purr. The animals will thank us.
Clive Thompson is a science and technology journalist based in New York City.