AI is changing search and rewriting the rules. If your brand isn’t visible in AI-generated answers, you have a bigger problem than just traffic. You’re missing out on trust, credibility, and customers who now expect AI to recommend the best options everywhere.
Table of contents
We see that traditional SEO isn’t enough anymore. Today, it’s possible to rank #1 on Google and still be invisible in the AI responses people now often turn to for recommendations.
Yoast AI Brand Insights is a great tool that shows you exactly how your brand appears in AI-generated answers from ChatGPT, Perplexity, or Google Gemini. It tracks sentiments and benchmarks against competitors. What’s more, it doesn’t just help build your AI visibility, but also helps control your brand’s narrative.
Key takeaways
AI visibility matters; brands absent in AI responses lose trust and customers.
Yoast AI Brand Insights helps track brand mentions, sentiment, and credibility across AI platforms.
Modern SEO now focuses on AI visibility, moving beyond traditional search engines.
To improve AI brand visibility, brands should publish authoritative content and optimize for AI citations.
Active participation in online communities enhances brand visibility on AI platforms.
Why modern SEO is about AI visibility
People are no longer just searching on Google. Every day, more people are asking AI tools and Large Language Models (LLMs) like ChatGPT, Gemini, and Perplexity for recommendations. Unlike classic search engines, these tools don’t just list links; they curate answers by combining trained knowledge with information they’ve learned from the web.
AI platforms combine information from multiple sources to provide a single, context-aware, and custom answer. People even start treating these AI answers as personal advice, not just generic search results. This will happen more and more as search engines like Google increasingly integrate AI into their search results. As a result, the boundaries between traditional search and AI-generated answers are blurring.
AI search is a blind spot for most
Classic SEO tools track rankings, but they don’t track how your brand appears in AI answers. This leads to blind spots where your competitors might be all over the AI recommendations in your market without you realizing it.
What’s more, you might rank well on Google, but you could be invisible to a growing audience if AI systems ignore your brand. Your competitors can appear more often or more positively in AI recommendations. Or there’s negative sentiment in AI responses that can harm your reputation without you even knowing.
Controlling the narrative of your brand
AI platforms like ChatGPT, Perplexity, and Gemini piece together your brand’s story from scattered sources, like reviews, news articles, social media, and your own content. If these send mixed signals, the answers an AI gives will too. That’s why you need to send a unified, consistent message. This is one of the most effective ways to reinforce your narrative across every platform.
Repeat your main message, whether that’s “affordable luxury” or “sustainable innovation,” everywhere, from your site content to press releases and from social media to external interviews.
Quickly address misinformation and respond to inaccurate reviews by publishing clarifications online. By doing this, you prevent the AI from amplifying outdated or incorrect details.
Support your brand’s most important attributes with structured data. Add the awards your brand won, or its unique selling points, so you can give the AI platform an all-encompassing framework to reference.
Remember, consistency is about repeating your most important brand aspects everywhere. Shape the narrative in such a way that the AI has no choice but to reflect the brand the way you want it to project.
Yoast AI Brand Insights is here to help
Yoast AI Brand Insights is a helpful tool that tracks how your brand appears in AI answers. It provides a clear, actionable view of your brand’s visibility, sentiment, and credibility across major AI platforms.
Yoast AI Brand Insights helps you:
Understand if and how your brand is mentioned in AI responses
Track sentiment and see if AI platforms describe your brand positively or negatively
Identify the sources to see what AI references when mentioning your brand
Benchmark against competitors to see how you stack up
We didn’t build this to get you some data, but to turn that AI black box into actionable insights.
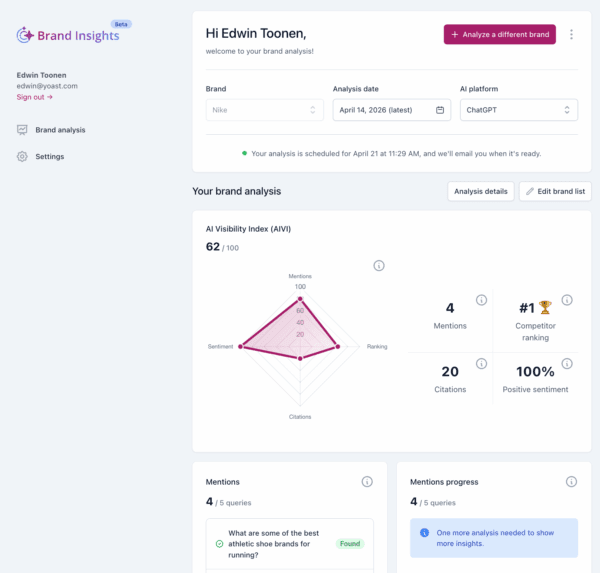
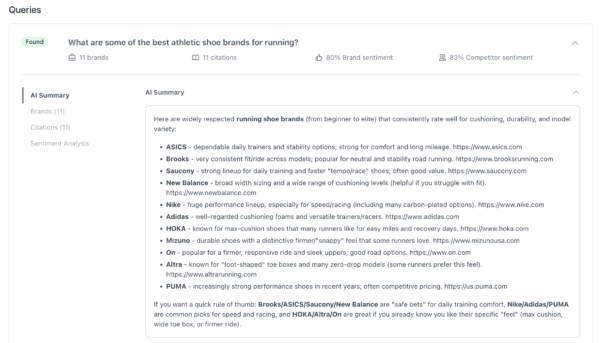
The main page of the Yoast AI Brand Insights shows your main metrics, and you can delve deeper into your analysis by going to Analysis details
Understanding the AI visibility metrics
Using the Yoast AI Brand Insights metrics helps you measure and improve your brand’s visibility in AI platforms. To make the most of it, you have to understand what metrics mean and why they matter.
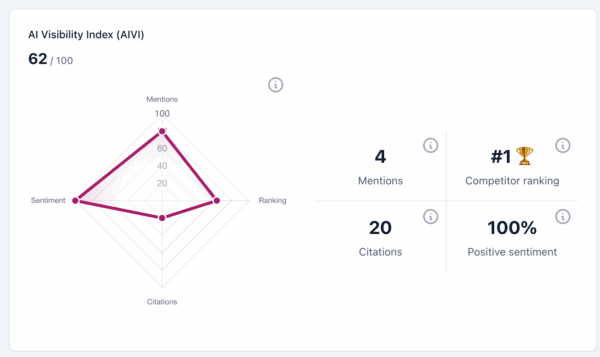
AI Visibility Index (AIVI)
The AI Visibility Index (AIVI) scores (on a scale of 100) how visible your brand is on AI platforms such as ChatGPT, Perplexity, and Gemini. It consists of the following metrics:
Mentions, or how often your brand is cited in AI answers
Citations, or the number of authoritative sources referencing your brand
Sentiment, or the rate of positive vs. negative keywords associated with your brand
Rankings, or the relative position of your brand mentions compared to your competitors
The higher the AIVI score (on a scale of 0-100), the more visible your brand is in AI search results for the tracked terms. If you find that your score is low, you should focus on getting more mentions and citations. You should also work on positive sentiment around your business.
You build your relevance by publishing authoritative content. Try to get featured on relevant sites and monitor and improve negative sentiment around your brand. Learn more about how AI shapes brand perception.
The higher the AIVI score (on a scale of 0-100), the more visible your brand is in AI search results for the tracked terms
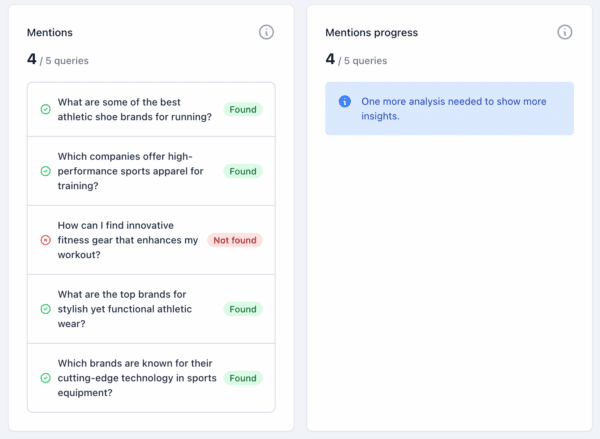
Mentions
The Mentions section tracks the specific queries for which your brand appears in AI responses. So, if someone asks, “What is the best low-cost CRM system for small businesses?” and your brand is in the results, that is a mention.
It’s not hard to understand why this is important. More mentions generally lead to greater visibility. If you don’t show up for the terms and queries relevant to your brand, you need to start improving your content.
Use the built-in AI-generated brand queries to find high-intent questions and write content that answers those questions thoroughly. These could be blog posts or FAQ pages, or whatever makes sense. Also optimize for conversational queries, such as “Is brand X good for startups?”
The mentions section tracks the specific queries for which your brand appears in AI responses
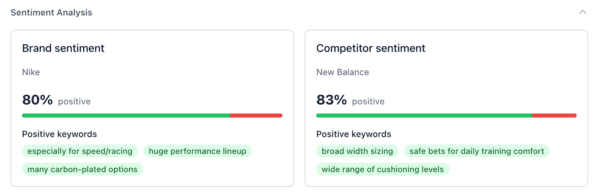
Sentiment
Sentiment measures the percentage of negative vs. positive words in the query results associated with your brand. So, if the AI describes your brand as “innovative” or “reliable”, that counts as positive sentiment. However, if they use terms like “overpriced” or “unreliable”, that’s negative sentiment.
Positive sentiment helps build trust, while negative sentiment can drive potential customers away. That’s why you should always actively address negative sentiments online. Don’t leave those bad online reviews unresponded to. You can also publish testimonials on your site to amplify positive voices, and you can do the same in your marketing messaging by talking about “a brand loved by thousands” or “award-winning” products.
Keep an eye on trends in your online sentiment and catch and fix issues early.
Sentiment measures the percentage of negative vs. positive words in the query results associated with your brand
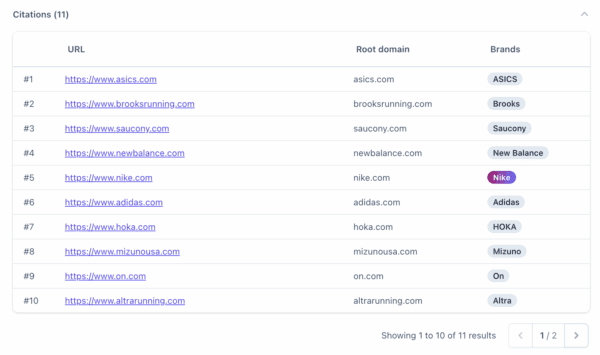
Citations
Citations refer to the sources that AI platforms explicitly reference when generating an answer, not the brands mentioned within those sources. For example, if Gemini answers a query about “the best credit cards” and cites a New York Times article about best credit cards, that New York Times page is the citation. Even if the article includes brands like American Express or Chase, the citation is attributed to the publisher, not to the individual brands.
That said, appearing in those cited sources still matters a great deal. If your brand is consistently featured in relevant, high-authority publications like The New York Times, it increases the likelihood that AI systems will surface your brand in their responses over time. In other words, you may not receive a direct citation, but you benefit from being part of the content that AI platforms trust and rely on.
Over time, your brand (say, American Express or Chase) becomes more likely to be included in AI responses to queries like “best credit cards,” especially if it consistently appears in trusted sources.
AI platforms use citations to validate their answers. Citations from top sources, such as industry publications, enhance credibility. Find where there’s a natural match between your customers and their audience, and publish the type of content people will want to link to.
Citations refer to the sources that AI platforms explicitly reference when generating an answer
5 Ways to improve your AI brand visibility
Now that you understand the metrics, here’s how to use insights from Yoast AI Brand Insights to improve your AI visibility.
Optimize for AI citations
AI platforms like Gemini, Perplexity, and ChatGPT use citations to validate their responses. So, citations increase the likelihood of your brand being included and trusted in AI-generated answers
Try to get featured on relevant, authoritative sites and publish guest posts on industry sites, news sites, or educational domains. Get mentioned in roundup articles, like “Top 10 tools for doing X”. Ask customers to write reviews on platforms like Capterra, G2, and Trustpilot. All of these tactics can act as proof that your brand is a well-trusted source. Remember, it must be relevant citations.
Make sure your content is structured so the AI can read it easily. Use clear, hierarchical headings and bullet points to make the content easy to scan. Add FAQs and publish direct answers to common questions. It is also a good idea to add schema markup to help the AI crawlers understand your content.
Don’t forget to update old content regularly. The AI platforms prioritize fresh, up-to-date information when retrieving sources, so refresh your content regularly to stay relevant.
Monitor and improve brand sentiment
By mentioning your brand, the AI platforms also shape how people see it. If those sentiments in the AI’s answers are negative, it can hurt your trustworthiness and cost conversions. This could signal the need for a broader reconsideration of business strategy priorities.
Once you find AI platforms associate your brand with negative terms (like “slow customer service”), respond to this issue publicly. For instance, you could contact customers on review sites to resolve complaints. You can also publish case studies and testimonials to steer the AI towards positive perceptions.
In your monitoring, you’ll also find the positive terms AI platforms associate with your brand, such as “trusted” or “innovative”. Use these terms in your marketing, in your site content, and on social media.
The weekly scans in Yoast AI Brand Insights track sentiment shifts for your queries over time. If sentiment drops, investigate the cause, like a recent PR issue or a product recall.
Benchmark against competitors
AI visibility is also about how you compare to the competition. If they are mentioned more often or in a better light than you, they will appear more often in recommendations made by AI platforms.
See how your brand stacks up against competitors. Use Yoast’s Competitor ranking tab to see which brands show up a lot in AI answers. Analyze their content strategy. Do they publish more case studies? Are they active on review sites?
This tool shows how AI describes your brand compared to others in your market. For example, if you’re a coffee company like Taylor’s of Harrogate, you might find that Lavazza is consistently labeled as “the Italian espresso expert.” Now you know exactly what to highlight, whether it’s your heritage, roasting process, or sustainability, to stand out. Use these insights to sharpen your messaging and compete more effectively.
Don’t forget to check your weekly competitor analyses to see if your AI visibility is improving. Double down on the strategy that works for you. The tool also includes an historical view. This lets you look back at earlier analyses by selecting a past date, helping you compare visibility and sentiment across different points in time.
For each tracked query, Yoast AI Brand Insights gives specific insights into how your brand performs versus the competition
Answer brand-specific questions
AI platforms are very good at answering specific questions, such as “Is brand X reliable?” or “What’s the best tool to do Y?” You’re missing out on a lot of potential customers when your brand isn’t in these answers.
Yoast AI Brand Insights suggests queries you should monitor based on your input, such as “Is [Your Brand] good for small businesses?” In addition, do deep research into the common questions asked in your industry using tools like AnswerThePublic, AlsoAsked, or simply by checking Google’s People Also Ask section.
With the insights gathered, publish blog posts, FAQs, or landing pages and directly answer those brand-related queries. Support the content with properly structured data, such as FAQ and how-to schema, to give AI platforms more tools to understand your content.
In Yoast AI Brand Insights, track which questions get the most mentions from AI platforms. Don’t forget to keep your content up to date to keep it accurate and relevant.
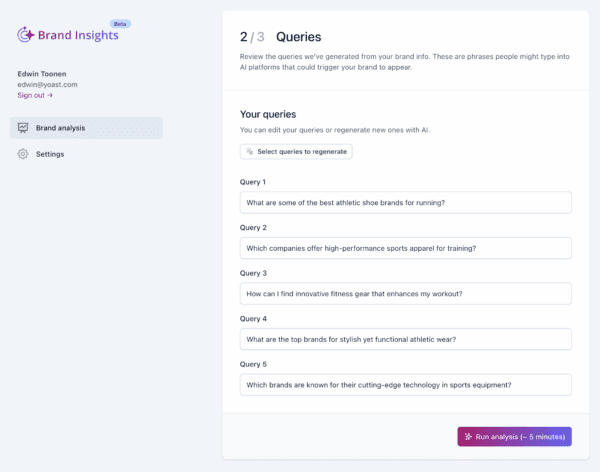
During the setup, Yoast AI Brand Insights generates five highly relevant queries based on your input. You can change them if you like
Track progress with the AI Visibility Index
Improving the AI visibility of your brand isn’t a one-time task, but a recurring effort. Luckily, Yoast’s AI Visibility Index gives you an easy-to-understand metric that you can use to track your progress over time.
Run your first scan to establish the starting point for your AI Visibility Index. Note which areas, like citations or sentiment, are strongest and weakest.
Yoast AI Brand Insights runs weekly scans. Please review them to track progress. Check the historical view, but remember these cannot be viewed together. Select the week before and then reselect this week to spot changes. Look for trends, such as improvements in sentiment or a sudden increase in citations.
If your score doesn’t improve, revisit the strategies above, such as optimizing for citations and improving sentiment. Be sure to experiment with new tactics and publish original research to secure more earned media.
How to influence LLMs to mention your brand
Imagine this: A potential customer asks ChatGPT, “What’s the best CRM for small businesses?” If your brand isn’t mentioned in the answer, you’ve lost a customer before they even knew you existed.
LLMs like ChatGPT, Gemini, and Perplexity don’t just pull answers out of thin air. They rely on data, citations, and patterns to generate responses. If your brand isn’t part of those patterns, it’s far less likely to be mentioned, no matter how well you rank on Google.
Publish authoritative content
LLMs are looking for well-structured, factually accurate content. These AI platforms love sources that provide unique insights or expert opinions, so be sure to focus on that.
Start with original research. Publish surveys, case studies, or industry reports with unique data. For example, “2026 State of [Your Industry] Report: Key Trends and Insights” positions your brand as an authority and gives AI platforms a reason to cite you.
Use the proven inverted pyramid structure in your content. Start with the most important information, like key findings and conclusions, follow with supporting details, and end with background information. This makes it easier for AI to extract, digest, and use your content.
Don’t forget to optimize for facts. Include statistics, quotes from experts, and actionable insights. For example, instead of “Our tool is great for marketers,” say “Our tool increased conversion rates by 30% for 500+ marketers in 2025, according to our latest case study.”
For example, HubSpot built its authority by publishing ultimate guides, like “The Ultimate Guide to Inbound Marketing.” These guides became go-to resources for marketers, earning backlinks from industry blogs, news sites, and even competitors. As a result, HubSpot is now frequently cited in AI responses about marketing tools.
Get mentioned on relevant, high-authority sites
LLMs trust reputable sources like industry publications, news sites, and review platforms. The more your brand is mentioned on these sites, the more likely it is to appear in AI responses. Please keep in mind that relevance is key here. For instance, if Yoast gets mentioned in Gardeners’ World or Home and Garden, it will do little to nothing for our brand. Find the most important and relevant sources and focus on those.
Pitch stories to journalists or industry blogs. For example, try to get featured in “Top 10 [Your Industry] Tools in 2026” lists.
Encourage customers to leave reviews on G2, Capterra, Trustpilot, or Google Reviews. Don’t forget to respond to (negative) reviews to show engagement and transparency.
If possible, try to reach out to sites like HubSpot, Search Engine Journal, or industry-specific blogs and ask to write for them. Be sure to include a bio with your brand name to reinforce recognition.
Optimize for conversational queries
LLMs are designed to answer natural language questions. This means you have to optimize your content for conversational queries. Conversational queries are things like “What’s the best CRM for startups?” rather than “best CRM”.
In your content, you should use question-focused headings. For example, answer the question “Is [Your Brand] good for small businesses?” directly in the first paragraph to make it clear and easy to understand.
LLMs often answer long-tail questions, so you should target long-tail keywords. For example, instead of “project management tool,” target “best project management tool for remote teams in 2026.”
In support of all of this, create FAQ pages with schema markup to help AI better understand your content.
Build citations
Build up a network of high-quality mentions that reinforce your brand’s authority. The more high-quality, relevant citations you have, the more likely LLMs are to mention your brand.
Publish assets like ultimate guides, templates, or tools that others want to reference and link to. For example, “The Ultimate Guide to [Your Industry] in 2026.”
Reach out to bloggers, journalists, and influencers to reference your content. For example, “We noticed you mentioned [Competitor] in your article. Here’s why [Your Brand] might be a better fit.”
Get featured in press releases, podcasts, or webinars. For example, “[Your Brand] Announces Groundbreaking Feature for [Industry].”
Make sure AI crawlers can reach your site
It’s important to ensure that AI crawlers can discover and index your content. If your site is invisible to them for whatever reason, your brand won’t appear in AI responses.
Your site should be technically sound, but you can also help LLMs in other ways. Make sure your site loads fast and is mobile-friendly. Use clean URLs, good meta tags and descriptions, and alt text for images. Also, use schema on your site to help AI crawlers understand what your site is about and how it all ties together.
In Yoast SEO, you can activate an llms.txt file. This proposed standard helps point AI crawlers to your most important content. Also, check whether your robots.txt file inadvertently blocks AI crawlers from accessing your content.
The llms.txt file in Yoast SEO helps point AI crawlers to your most important content
Be active in online communities
LLMs are trained on and can retrieve information from forums, social media, and community platforms such as Reddit, Quora, and LinkedIn. It can improve your brand’s visibility on AI platforms if you participate there.
Answer questions on Quora and Reddit. Provide valuable, non-promotional answers that naturally mention your brand. For example, “As a [Your Industry] expert, I recommend [Your Brand] because…”
Join discussions on Slack, Discord, or niche forums. Share insights and link to your content when relevant. Post thought leadership content on LinkedIn, Twitter, or Facebook. For example, “Here’s why [Your Industry] is changing in 2026, and how [Your Brand] is leading the way.”
The future of brand visibility is AI-driven
We’ve seen that AI is changing how people discover brands. There’s a simple rule: if your brand isn’t visible in AI responses, you are missing out on an ever-growing audience.
Luckily, Yoast AI Brand Insights gives you the tools to:
Track mentions, sentiment, and citations across AI platforms
Benchmark against competitors to identify gaps
Optimize for high-intent queries to capture more attention
Edwin is an experienced strategic content specialist. Before joining Yoast, he worked for a top-tier web design magazine, where he developed a keen understanding of how to create great content.
This series has been written in English, tested in English, and grounded in research conducted primarily in English. Every framework discussed here (vector index hygiene, cutoff-aware content calendaring, community signals, machine-readable content APIs) was conceived by an English-speaking practitioner, stress-tested against English-language queries, and validated against benchmarks that, as this article will show, are themselves English-weighted by design. That is not a disclaimer, but it is the central problem this article is about.
The AI visibility discourse at large carries the same limitation. One 2024 study analyzing AI evaluation datasets found that over 75% of major LLM benchmarks are designed for English tasks first, with non-English testing treated as an afterthought. The strategies built on top of those benchmarks inherit the same bias.
Enterprise brands are not the villains in this story. Translation-first search content strategies produced imperfect results globally, but markets had learned to live with the nuanced failures. Traditional search indexed what existed, ranked it imperfectly, and the degradation was quiet enough that no one filed a complaint. LLMs raise the bar in a way search never did, and the reason is structural, which is what the rest of this article examines.
The Platform Map
Before optimizing AI visibility in any market, a brand needs to answer a question the English-centric visibility discourse rarely asks: Which AI system are your target customers actually using? The answer varies more dramatically by region than most global marketing teams have accounted for.
South Korea tells a different version of the same story. Naver captured 62.86% of the South Korean search market in 2025 (more than double Google’s share) and since March 2025 has been deploying AI Briefing, a generative search module powered by its proprietary HyperCLOVA X model, with plans for up to 20% of all Korean searches to surface AI-generated answers by end of 2025. Naver is also a closed ecosystem where results route to internal Naver properties, not necessarily the open web. Western brands whose structured data and llms.txt implementation was designed for open-web crawlers are operating with architecture that was never built to reach Naver’s retrieval layer. China and Korea alone account for well over a billion AI-active users on platforms a standard global visibility strategy does not touch.
The Map Is Far Bigger Than We’re Drawing
Those two markets are the ones that get cited because their scale is impossible to ignore. But the platforms being built outside the English-dominant orbit extend considerably further, and the breadth of what has launched in the last two years deserves attention on its own terms.
Europe
France – Mistral AI’s Le Chat was the No. 1 free app in France after its February 2025 launch; the French military awarded Mistral a deployment contract through 2030, and France committed €109 billion in AI infrastructure investment at the 2025 AI Action Summit.
Germany – Aleph Alpha trains in five languages with EU regulatory compliance by design, backed by Bosch and SAP.
Italy – Velvet AI (Almawave/Sapienza Università di Roma) is built specifically for Italian language and cultural context, designed for EU AI Act compliance from inception.
European Union – The OpenEuroLLM initiative, launched in 2025, is developing a family of open LLMs covering all 24 official EU languages.
Switzerland – Apertus (EPFL/ETH Zurich/Swiss National Supercomputing Centre, September 2025) supports over 1,000 languages with 40% non-English training data, including Swiss German and Romansh.
Middle East
UAE/Abu Dhabi – Falcon (Technology Innovation Institute) ranges from 7B to 180B parameters; Falcon Arabic, launched May 2025, outperforms models up to 10 times its size on Arabic benchmarks.
Saudi Arabia – HUMAIN, backed by the sovereign wealth fund, is framed as a full-stack national AI ecosystem.
South and Southeast Asia
India – Bhashini (Ministry of Electronics and IT) has produced over 350 AI-powered language models; BharatGen, launched June 2025, is India’s first government-funded multimodal LLM.
Singapore / Southeast Asia – SEA-LION (AI Singapore) supports 11 Southeast Asian languages; Malaysia, Thailand, and Vietnam have deployed MaLLaM, OpenThaiGPT, and GreenMind-Medium-14B-R1, respectively.
Latin America
12-country consortium – Latam-GPT launched September 2025, led by Chile’s CENIA with over 30 regional institutions, trained on court decisions, library records, and school textbooks, with an initial Indigenous language tool for Rapa Nui.
Africa/Eastern Europe
Sub-Saharan Africa – Lelapa AI’s InkubaLM supports Swahili, Yoruba, IsiXhosa, Hausa, and IsiZulu; Nigeria launched a national multilingual LLM in 2024.
Russia/Ukraine – GigaChat (Sberbank) is the dominant domestically deployed Russian AI assistant; Ukraine announced a national LLM in December 2025, built with Kyivstar and trained on Ukrainian historical and library data.
This list is not really meant to be exhaustive, but it is meant to be disorienting.
Every entry above represents a retrieval ecosystem, a cultural signal hierarchy, and a community proof-point structure that a North American-optimized AI visibility strategy does not reach. But the more important observation is about which direction these models were built in.
The old content strategy model was centrifugal: the brand sits at the center, creates content, translates it, and pushes it outward into markets. Traditional search accommodated this because crawlers are indifferent to cultural authenticity: they index what is there. The imperfect results were tolerated because most markets had no better alternative.
These regional models were built in the opposite direction. A government mandate, a national corpus, a specific cultural identity, a language’s syntactic logic, that is the origin point. The model was trained on what that place knows about itself. A brand’s translated content arrives as a foreign object with no parametric presence, carrying the syntactic and cultural signatures of its origin language. Translation does not retrofit cultural fit into a model that was built without you in it.
And this does not stop at the English/non-English boundary. Even within English, regional identity shapes what a model treats as native. Irish English carries vocabulary – craic, gas, giving out, that exists nowhere else. Australian idiom, Singaporean English, Nigerian Pidgin all have distinct fingerprints. A U.S. brand’s content may read as subtly foreign to a model trained predominantly on British or Irish corpora. The direction of the problem is the same regardless of whether the language is technically shared. So often these aren’t just words. They’re compressed cultural signals. A literal translation gives you the category, but often strips out aspects like intensity, intent, emotional tone, social expectation, or shared history.
The Embedding Quality Gap
The reason translation does not solve this is not just strategic. It’s structural, and it lives in the embedding layer.
Retrieval in AI systems depends on semantic similarity calculations. Content is encoded as a vector, queries are encoded as vectors, and the system identifies matches by measuring distance in that vector space. The accuracy of those matches depends entirely on how well the embedding model represents the language in question. Embedding models are not language-neutral. (I think of this as a kind of cultural parametric distance, or a language vector bias issue.)
The most rigorous current evidence comes from the Massive Multilingual Text Embedding Benchmark (MMTEB), published at ICLR 2025. Even across more than 250 languages and 500 evaluation tasks, the benchmark’s own task distribution is skewed toward high-resource languages. The benchmarks practitioners use to evaluate whether their embedding architecture works in other languages are themselves English-weighted. A leaderboard score that looks reassuring may be measuring performance on a test that does not represent the language actually in use.
The embedding gap does not produce obvious errors. It produces quietly degraded retrieval and content that should surface does not, without any visible failure signal. The dashboards stay green. The gap only becomes visible when someone tests in the actual market language.
When Translation Isn’t Enough
Below the embedding layer sits a problem that is harder to instrument: Cultural context shapes what a model treats as relevant in the first place. Research published in 2024 by Cornell University researchers found that when five GPT models were asked questions from a widely used global cultural values survey, responses consistently aligned with the values of English-speaking and Protestant European countries. The models were not asked to translate anything; they were asked to reason, and their default frame of reference was shaped by the cultural composition of their training data.
Consider a brand headquartered outside France, but operating in France. Their content, even if professionally translated, was likely written by non-French-speaking teams with non-French-market authority signals: the institutional citations, the comparison frameworks, the professional register. Mistral was built on French corpora, with French institutional relationships and French media partnerships as its baseline for what counts as authoritative. A Canadian brand’s French content, for example, is tolerated by a French-speaking human reader. Whether it clears the threshold for a model trained on native French content as its definition of relevance is a different question entirely.
The community signals argument from the previous article in this series applies here with a regional dimension. The platforms that drive AI retrieval through community consensus differ by market. In China, Xiaohongshu now processes approximately 600 million daily searches (nearly half of Baidu’s query volume) with over 80% of users searching before purchasing and 90% saying social results directly influence their decisions. The community signals that matter for AI visibility in China are not the ones a strategy built around English-language review platforms is generating.
A brand may have excellent English-language retrieval infrastructure, strong community signals in Western markets, and a well-architected machine-readable content layer, and still be effectively invisible in Korea, structurally disadvantaged in Japan, and culturally misaligned in Brazil. This is not a failure of execution as much as a failure of assumption about which direction the optimization flows.
What Enterprise Teams Should Do
An honest note before the framework: The documented, auditable evidence base for enterprise-level non-English AI visibility strategies does not yet exist in a form that holds up to scrutiny. Work is being done, but a citable case study requires a defined baseline, a measurable intervention, a controlled timeframe, and independently validated results. A practitioner’s assertion that their work applies to your situation is not that. The absence of rigorous case data is a reason to build with intellectual honesty about what is validated versus directional, not a reason to wait. With that in mind, here’s what you can do today:
Audit AI visibility per language and per market, not globally. Query performance in English tells you nothing about performance in Japanese, and performance with global AI platforms tells you nothing about performance inside Naver’s AI Briefing. The audit needs to happen at the market level, using queries constructed in the local language by native speakers, not translated from English.
Map the AI platforms that matter in each target market before optimizing. The list in the previous section is a starting point, not a permanent reference, as this landscape shifts quarterly. Optimization work (structured data, content APIs, entity signals) needs to be built toward the platforms that actually serve each market.
Build localized content, not translated content. The four-layer machine-readable architecture discussed in this series applies in every language. But a translated version of an English content API is not a localized one. Entity relationships, cultural authority signals, and community proof points all need to be rebuilt for local context. The optimization direction is inward from the market, not outward from the brand.
Accept that English-English is not a single market either. The same structural logic applies within English. A US brand’s content may carry American syntactic and cultural signatures that read as subtly foreign to models trained on predominantly British, Irish, or Australian corpora. Regional English is not a rounding error. It is evidence of the same underlying principle operating on a smaller scale.
Accept that a single global AI visibility strategy is insufficient. The frameworks developed in English, including the ones in this series, are a starting point for one slice of the global market. Extending them globally requires treating each major market as a distinct optimization problem: different platforms, different embedding architectures, different cultural retrieval logic, and a different direction of trust.
Image Credit: Duane Forrester
There is real work to be done. If we step back and look at the big picture again, it’s clear that markets that were once willing to live with the nuanced failures of translation-first content strategies are increasingly operating on platforms built to serve them natively, and that gap is widening. You know I like to name things when the industry hasn’t gotten there yet so here it is: this is the Language Vector Bias problem. And the brands that start closing it now are not catching up to a solved problem. They are getting ahead of the most consequential visibility gap we aren’t really talking about.
AI agents are already here. Not as a concept, not as a demo, but shipping inside browsers used by billions of people. Every major tech company has launched either a browser with AI built in or an extension that acts on your behalf.
Anthropic’s Claude for Chrome can navigate websites, fill forms, and perform multi-step operations on your behalf. Google announced Gemini in Chrome with agentic browsing capabilities, including auto browse, which can act on webpages for you. OpenClaw, the open-source AI agent, connects large language models directly to browsers, messaging apps, and system tools to execute tasks autonomously.
For more understanding about optimizing for agents, I spoke to Slobodan Manic, who recently wrote a five-part series on optimizing websites for AI agents. His perspective sits at the intersection of technical web performance and where AI agent interaction is actually heading.
From Slobodan Manic’s testing, almost every website is structurally broken for this shift.
“It started with us going to AI and asking questions. And now AI is coming to us and meeting us where we are. From my testing, I noticed that websites are nowhere near being ready for this shift because structurally almost every website is broken.”
The Single Biggest Thing That’s Changed
I started by asking Slobodan what’s changed in the last six to nine months that means SEOs need to pay attention to AI agents right now.
“Every major tech company has launched either a browser that has AI in it that can do things for you or some kind of extension that gets into Chrome. Claude has a plugin for Chrome that can do things for you, not just analyze web pages, summarize web pages, but actually perform operations.”
When ChatGPT first launched in 2023, making AI widely accessible, in parallel with how we started typing basic queries in search engines 25 years ago, we asked AI questions. We are now becoming more sophisticated and fluid with our prompting as we realize that AI can do so much more than [write me an email to politely decline an invitation].
Agents represent an even bigger shift to a different dynamic, where AI can complete tasks on our behalf and run complex systems. [Check my emails and delete any that are spam, sort them into a priority group, and surface what needs my immediate attention and provide a qualified response to anything on a basic query, plus make appointments in my calendar for any meeting invites].
I have a theory that brand websites are becoming hubs, the central point that connects all of your content assets online. But Slobodan has gone further. He’s written about websites becoming optional for the end user, with pages built by machines for machines and the interaction happening through closed system interfaces. I asked him to expand on that vision and what kind of timeframe we’re realistically looking at.
“First I’ll say that this is not fully happening today. This is still near to mid future. This is not March 2026,” he clarified. But the signals are concrete.
He was careful not to overstate it. People still like to browse, read, and compare things. Websites aren’t disappearing.
“Just the same way as mobile traffic has not killed desktop traffic even if it’s taken a bigger share of traffic overall, higher percentage of overall traffic while the desktop traffic is staying flat in terms of absolute numbers, I think this is another lane that will open where things will be happening without a human being involved in every step.”
His timeline for this: “Within a year we can have this become a reality. Not majority, but if Google starts rewriting landing pages using AI, we will see this happening probably 2027, if not sooner.”
When Checkout Becomes A Protocol
Slobodan has written that checkout is becoming a protocol, not a page. If an AI agent can buy on your behalf without ever loading a brand’s website, I asked, “What does that mean for how brands build trust and differentiate when the customer never sees their site?”
“If you’re building trust in a checkout page, you’re doing it wrong. Let’s start there. That I firmly believe. This is not to do with AI. This was never the right place to build trust,” he responded.
Slobodan pointed to every Shopify checkout page that looks identical. “There’s no trust built there. It’s just a machine-readable page that looks the same for everyone, for every brand. You’re supposed to be doing your job before the user needs to pay you.”
This is where he referenced Jono Alderson, and the concept of upstream engineering. “Moving upstream and doing work there and not on the website is the only way to move forward for anyone whose job is optimizing websites. That’s SEO, that’s CRO, that’s content, that’s anyone doing any kind of website work.”
He best summarized by saying “Your website is a part of the equation. Your website is not the equation. And that’s the biggest structural shift that people need to make to survive moving forward.”
What SEOs And Brands Should Actually Do Now
I asked what SEOs and brands can practically start doing to transition over the next year. His answer reframed how we should think about the website itself.
“If your website was your storefront, and it was for decades, people come to you, people do business there. It needs to be a warehouse and a storefront moving forward or you’re not going to survive. Simple as that.”
“We had all those bookstores that were selling books in the ’90s and then Amazon shows up and then you need to be a warehouse. You need to exist in two planes at the same time for the near future at least. So focusing only on your website is the most wrong thing you can do moving forward.”
His main area of focus right now is what he calls machine-first architecture. The principle is to build for machines before you build for humans.
“You don’t build your website for humans until you’ve built it for machines. When you’re working on a product page, there’s no Figma, there’s no design, there’s no copy. You start with your schema. What is your schema supposed to say? What is the meaning of the page? You start with the meaning and then from that build into a web page as it’s built for humans.”
He compared it directly to the mobile-first shift. “That did not mean no desktop. That meant do the more difficult version of it first and then do the easy thing. Trust me, it’s a lot more complicated to add meaning and structure to a page that’s already been designed than to do it the other way.”
And it extends beyond the website. “If you’re saying something on your website, you better check all of your profiles everywhere online, what people are saying about you. It’s everything everywhere all at once. But this is what optimization has become and what it needs to be.”
I also put to him the argument that optimizing for LLMs is fundamentally different from SEO. His response was unequivocal.
“Hard disagree. The hardest possible disagree. If you were doing things the right way, working on the foundations and checking every box that has to be checked, it’s not different at all.”
Where he sees a difference is in the speed of consequences. “With AI in the mix, you just get exposed much faster and the consequences are much greater. There’s nothing different other than those two things.”
This echoed something I’ve felt strongly. The cycle is moving more quickly, but there’s so much similarity with what happened at the foundation of this industry 25 to 30 years ago, which I raised in my SEO Pioneers series. We’re feeling our way through in the same way. And Slobodan agreed.
“They figured this out once and maybe we should ask them how to figure it out again.”
Vibe Coding Is A Trap, Deep Work Is The Moat
For my last question, I put it to Slobodan that he’s said vibe coding is a trap and deep work is the only moat left. For the SEO practitioner feeling overwhelmed, what’s the one thing they should actually do this week?
“It’s really the foundations. I hate to give the boring answer, but it’s really fixing every single foundational thing that you have on your website or your website presence.”
He’s watched the industry chase one shiny tool after another. “There’s always a new shiny toy to work on while your website doesn’t work with JavaScript disabled. Just ignore all of that until you’ve fixed every single broken foundation you have on your website.”
On vibe coding specifically, he was precise: “I don’t like the term vibe coding. It just suggests that you have no idea what you’re doing and you’re happy about it. That’s the way that sounds to me. The concept of AI-assisted coding, it’s there. It’s great. It’s not going away.”
“But just focus on what you should be doing first before you use AI to do it faster.”
What resonated with me is how well this applies to writing, too. AI is brilliant at confidently producing a draft that, at first glance, looks great. But when you actually read it, you realize it’s just somebody confidently talking nonsense.
Slobodan nailed the core problem: “You need to know what good is and what good looks like. Because AI will always give you something. If you don’t know enough about that specific thing, it will always look good from the outside. And there’s a reason why everyone is okay with vibing everything except for their own profession, because they try it and they see that the results are just horrific.”
Build For Machines First, Everything Else Follows
The one thing to take away from this conversation is to build for machines first, then humans. Not because human user experience won’t matter, but because getting the machine layer right first makes the human layer better.
Your website is no longer the only version of your business that people, or agents, will encounter. The brands that treat it as part of a wider ecosystem rather than the whole ecosystem are the ones that will come through this transition in the strongest position.
Watch the full video interview with Slobodan Manic here, or on YouTube.
Thank you to Slobodan for sharing his insights and being my guest on IMHO.
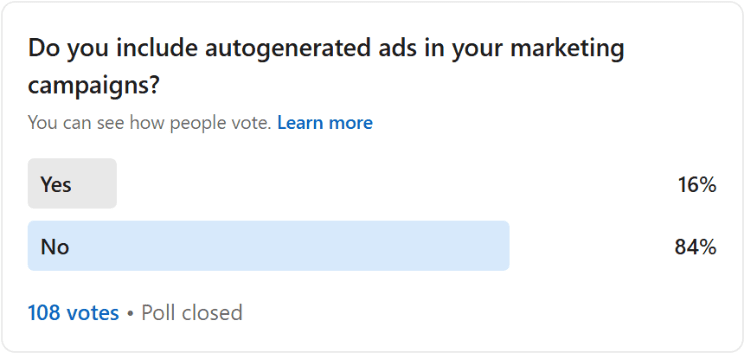
Search advertising is one of the largest digital ad categories, but its growth is slowing as social media and video post faster gains, according to IAB’s annual report, conducted by PwC.
What The Data Shows
In 2025, digital advertising revenue reached $294 billion, reflecting a 13% increase from the previous year. The report uses self-reported revenue data from companies selling advertising online. PwC says it does not audit the information or provide assurance.
Search advertising, including AI search, generated $114 billion, making it one of the largest segments in the report, though IAB’s category definitions overlap.
Search saw an 11% growth year-over-year, slower than the 15% in 2024. Social media experienced stronger growth, with ad revenue totaling $117 billion, a 32% rise or $29 billion increase. The IAB attributed this to the creator economy, enhanced commerce integration, and improved targeting and measurement.
Digital video grew by 25%, reaching $78 billion, faster than the 19% growth in the previous year, indicating more ad spending attracted by video. Commerce media hit $63 billion, up 18%, while programmatic advertising increased by 20% to $162 billion.
In its 2026 outlook, IAB said creator advertising reached $37 billion in 2025, with projections of $44 billion in 2026, noting a move from campaign-based influencer marketing to continuous creator programs.
A note on the data: categories like social, search, video, display, and commerce media overlap in the $294 billion total, so a single ad, such as a social video ad, could be counted in multiple categories.
Why This Matters
The slowdown in search growth warrants attention alongside other recent indicators. Google’s Q4 2025 earnings reported a 17% increase in Search revenue, but this reflects just a single quarter for one company.
In contrast, the IAB data covers the entire year across a broad industry dataset, with growth rates falling from 15% to 11%, indicating the overall category is expanding more slowly than the competing channels vying for the same budgets. This doesn’t imply search is shrinking; it still generated $114 billion in revenue, even though social and video ads grew at a faster pace. Commerce media, at $63 billion, now accounts for over 20% of total digital ad revenue.
Looking Ahead
IAB will host a webinar on April 21 at 1 p.m. ET with experts from IAB, PwC, and Madison & Wall to discuss the findings.
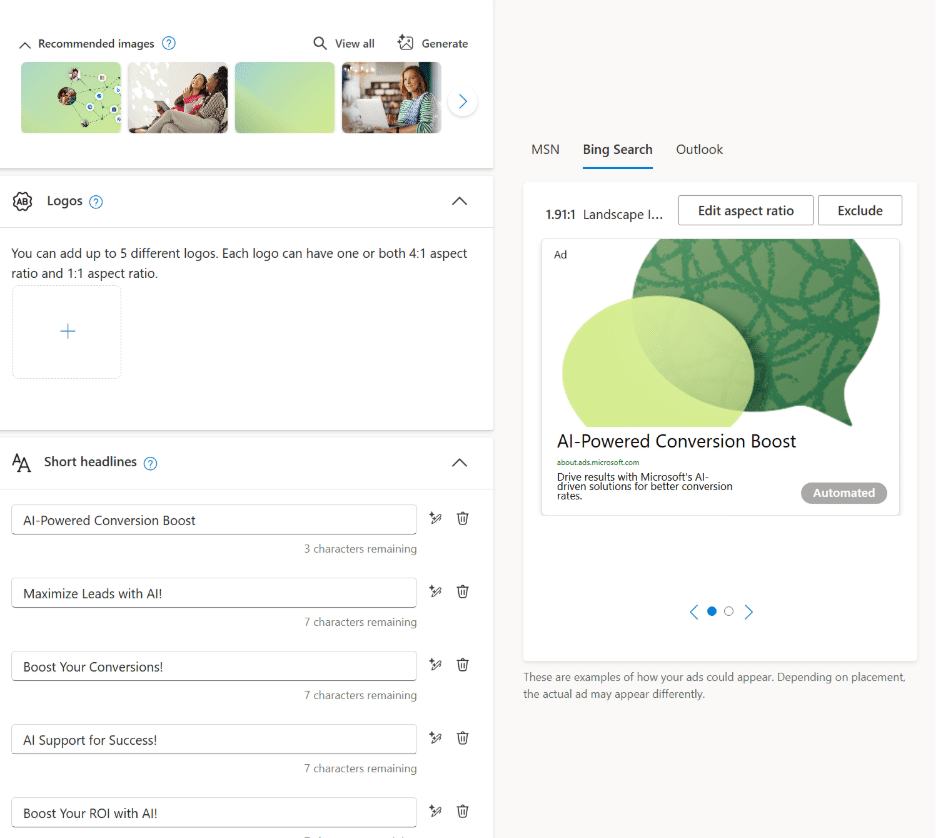
Customer-in-the-loop (CITL): Assets are generated based on inputs like a website URL or a user prompt. The advertiser always has a choice as to whether or not they want to include these assets in their campaigns.
Dynamic composition: Ads are composed at serving time in different formats based on existing groups of assets, with performant winners selected and scaled (i.e., how Performance Max works). May or may not include AI-generated assets based on customer preferences.
Auto-generated: New assets or ads are generated after a campaign is launched based on inputs like URLs, search queries, or existing videos to improve performance. These assets are not reviewed and approved by advertisers before serving, but can generally be viewed and controlled in reporting.
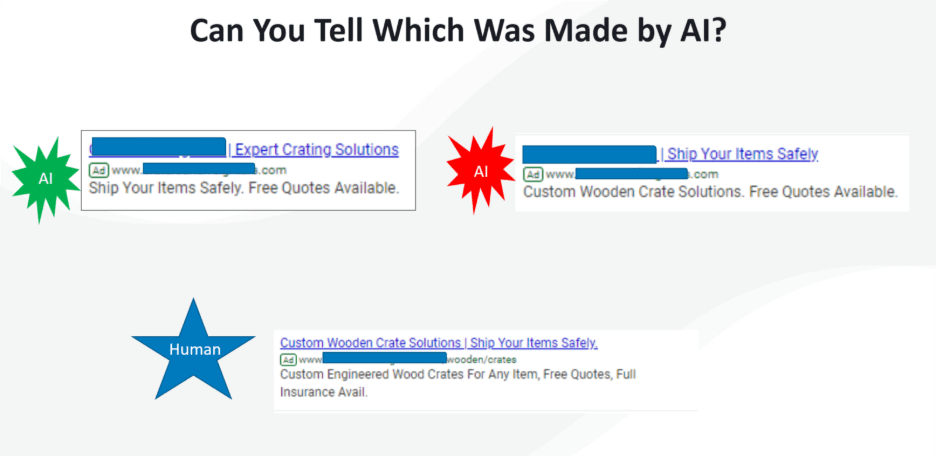
These performance gains aren’t new; AI ads have been meeting or exceeding human creative as early as 2018.
Three text ads: one made by a human, the others autogenerated (Image from author, April 2026)Results of three ads from a logistics company over 30 days (Image from author, April 2026)
That performance edge comes from two core advantages.
First, auto-generated creative is highly adaptable. It can flex across formats and placements in ways that would be time-consuming or impractical for humans to manage manually.
Second, it is bias-free in its willingness to apply the creative most likely to perform for humans searching in a profitable way, rather than the semantic syntax we think will succeed.
This article is not about declaring auto-generated creative right or wrong. There is no universal answer. Whether leaning into it makes sense will always depend on business constraints, brand rules, and personal comfort levels.
What we are going to do is walk through a practical framework you can use to decide whether auto-generated creative is worth testing for your business, and how to use platform tools to better understand how well your site and messaging are being interpreted by AI systems.
Before we get into it, an important disclosure. I am a Microsoft Advertising employee. The guidance here is intended to be platform-agnostic, but I will reference a few Microsoft-specific tools that are free to use and particularly helpful for understanding how your site is being interpreted by machines and humans alike.
The Case For Using Auto-Generated Creative
The number one reason to consider auto-generated creative is simple: time savings.
At its core, auto-generated creative takes your existing assets and adapts them to meet the formatting and placement needs of different inventory. Instead of building bespoke creative for every surface, you allow the system to reassemble what you already have in ways that let you reach more people with less manual effort.
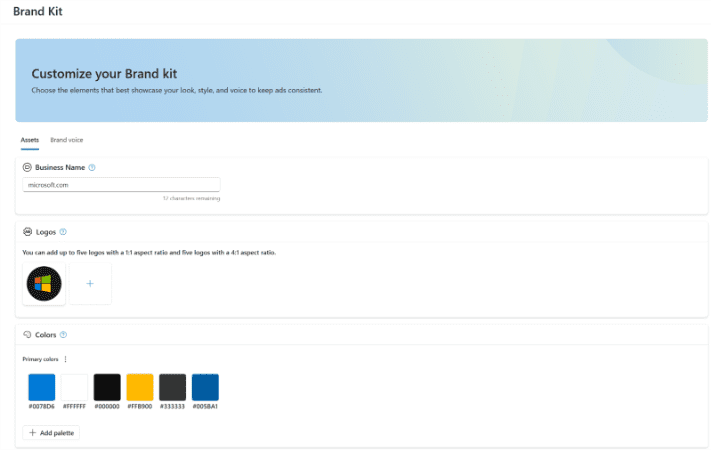
The inputs for auto-generated creative typically come from your website, your existing ads, and, in some cases, proven concepts that are broadly applicable across advertisers. You can also apply brand style guides to ensure fonts, colors, and creative (including tone of voice) are compliant with brand standards.
Because auto-generated creative allows advertisers to be eligible for more placements (with Ad Rank determining the ad shown), it naturally has access to more impressions. More impressions create more opportunities to win auctions, which can translate into incremental volume that would have been difficult to capture using tightly controlled, manually built assets alone.
Auto-generated creative does not have to be all-or-nothing. There is also a hybrid approach where humans partner with AI systems. That can mean using in-platform tools from Google or Microsoft, or external AI tools, to help generate ideas, headlines, or variations that are then reviewed, approved, and manually uploaded.
Some advertisers draw a distinction between AI-assisted ideation and auto-generated creative. In practice, if you are using AI at any point to help create or shape ad messaging, there is already an element of automation in the process.
The Case Against Using Auto-Generated Creative
There are absolutely valid reasons to opt out.
The most pressing is brand compliance. If your organization requires explicit approval for every piece of creative before spend can occur, allowing systems to dynamically generate variations may simply not be permissible.
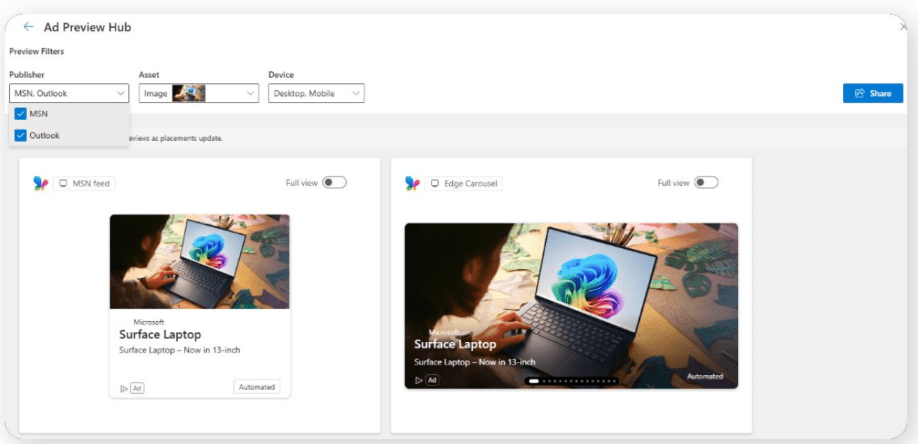
That said, many platforms provide preview tools that show examples of how creative may appear.
Image from author, April 2026
If you are willing to explore those previews and lean into tools like brand kits that enforce fonts, colors, and tone, it may be possible to secure internal approval where it previously felt impossible.
Another reason advertisers shy away from auto-generated creative is reliance on proven assets with no tolerance for variation. Sometimes budget approval is contingent on using specific creative that has already demonstrated performance, and there is no room to test alternatives.
Image from author, April 2026
It is worth noting, however, that auto-generated creative already relies heavily on your existing assets. If the primary concern is avoiding untested messaging, allowing your site content and proven ads to inform the system can help mitigate that risk.
Bonus Tip: Using Auto-Generated Creative To Understand How AI Sees You
One of the most underrated benefits of campaigns like Performance Max, Dynamic Search Ads, and other feed or keywordless-based formats is that they reveal how well platforms understand your site and landing pages.
Image from author, April 2026
If you strongly disagree with the creative shown in previews for AI Max, Performance Max, or similar formats, that is a warning sign. Running budget to those pages risks confusing users if the system’s interpretation does not align with your intended messaging.
These tools can function as diagnostic instruments, not just delivery mechanisms.
Image from author, April 2026
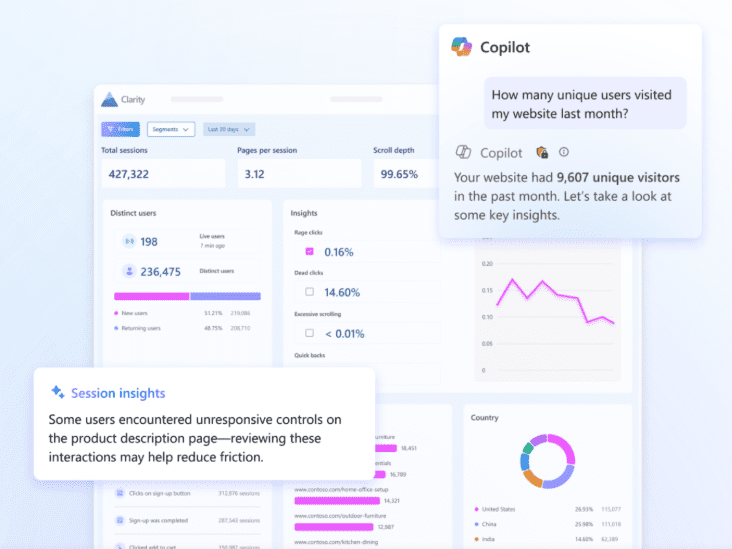
You can go a step further by pairing them with behavioral analysis tools like Microsoft Clarity, which shows how users actually interact with your site. When creative interpretation and user behavior do not line up, the issue is often not the ads, but the underlying content.
Another advantage of modern campaign creation tools is their built-in AI editing capabilities. Even if you never allow auto-generated creative to go live, you can still use these tools to explore tone shifts, rewrites, and messaging ideas that inform your manual creative work.
Image from author, April 2026
There are many use cases for these systems beyond automation alone. Insight generation is one of the most valuable.
Final Takeaways
At its core, the decision to lean into auto-generated creative comes down to whether your brand is allowed to test.
If the answer is yes, there is little downside to experimenting. Auto-generated creative is largely built from your existing assets, and poor results are often a signal that your landing pages or messaging need refinement anyway.
If the answer is no, whether due to brand compliance, limited testing bandwidth, or the need to lock spend behind proven creative, it is entirely reasonable to opt out.
Used thoughtfully, it can save time, unlock scale, and surface insights about how your brand is understood by machines and users alike. Used blindly, it can create risk. The goal is not blind trust, but informed experimentation.
Hope you found this helpful, and I’ll see you next month for another edition of Ask the PPC.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
The United States Patent Office recently published Google’s continuation on a patent for a search system that detects when there is no satisfactory answer for a query and waits to automatically deliver the answer when it becomes available.
Search And AI Assistant
The patent, published in February 2026, is a continuation of an older patent, with the main changes being to apply this patent within the context of an AI assistant. The invention describes solving the problem of answering a question when no actual answer is available at the time a user makes the query. What it does is waits until there’s a satisfactory answer, at which point it circles back to the user with the answer, without them having to ask again.
The patent is titled, Autonomously providing search results post-facto, including in assistant context. Although the patent mentions quality thresholds, those thresholds are defined in the sense of whether the answer meets the user’s needs.
The patent describes six scenarios that would trigger the invention:
When no search results meet defined quality or authoritative-answer criteria.
When results exist but fail to provide a definitive or authoritative answer that satisfies those criteria.
When no results meet quality criteria because the information is not yet available.
When a query seeks a specific answer and no result satisfies the required criteria.
When a resource later satisfies the defined criteria after previously lacking required information.
When a previously available resource is refined or updated so that it now meets the criteria.
Useful And Complete Answers
Google’s patent says that the invention is a solution for times when there is no useful or complete answers because the information does not yet exist or is not good enough, forcing users to keep searching repeatedly.
The system checks if results meet:
A quality standard
Authoritativeness standard
Or a completeness standard.
If the current answers don’t meet those standards, the system will store the query and monitor for new or updated information. Once it becomes available it will send the results to the user later without them searching again.
Follow-Up Questions Are Not Necessary
What is novel about the invention is that it enables follow-up delivery of results after the original query without requiring a new follow-up questions. It also surfaces search results proactively in notifications or assistant conversations.
At a later time, when new or updated information becomes available that satisfies the criteria, the system proactively delivers that information to the user. This delivery can occur through notifications, within an unrelated interaction, or during a later conversation with an automated assistant.
The system may also optionally notify the user that no good results are currently available and ask if they want to be informed when better results appear.
What this system does is it transforms search from a one-time, user-initiated action into a persistent, ongoing process where the system continues working in the background and updates the user when meaningful information becomes available.
Cross-Device Continuity
An interesting feature of this invention is that it can reach out to the user across multiple devices.
Here is where it’s outlined:
[0012] In some implementations, the query is received on an additional computing device that is in addition to the computing device for which the content is provided for presentation to the user.”
This capabiilty is highlighed again in section [0067]:
“For example, the content may be provided for presentation to the user via the same computing device the user utilized to submit the query and/or via a separate computing device.”
It can also go cross-device as a visual and/or audible output across devices and in the form of an automated assistant, and can present the information when the user is interacting with the automated assistant in a different context, describing an “ecosystem” of devices.
Lastly, the patent explains that the information can be surfaced when the user is interfacing with the automated assistant in a completely different context:
[0040]”…the content may be provided for presentation to the user via the same computing device the user utilized to submit the query and/or via a separate computing device. The content may be provided for presentation in various forms. For example, the content may be provided as a visual and/or audible push notification on a mobile computing device of the user, and may be surfaced independent of the user again submitting the query and/or another query.
Also, for example, the content may be presented as visual and/or audible output of an automated assistant during a dialog session between the user and the automated assistant, where the dialog session is unrelated to the query and/or another query seeking similar information.”
Takeaways
The patent (Autonomously providing search results post-facto, including in assistant context) is in line with Google’s vision of tasked-based agentic search, where AI assistants help users accomplish things. This patent could be applied to an AI agent that is asked for tickets to an event when the tickets aren’t yet available. Or it could be applied to making restaurant reservations when the reservations when the dates open up. Both of those scenarios are related to task-based agentic search (TBAS)
Here are seven takeaways:
The system stores data associated with the user about unresolved queries, allowing it to track unanswered information needs over time rather than treating each search as a one-off event.
It delivers results within future interactions, including unrelated assistant conversations, not just through standalone notifications.
The notifications can happen across an ecosystem of devices.
A lack of results is defined by failing to meet quality criteria, which can be the absence of information, the answer not being available yet, or the answer is not available from authoritative sources.
The system focuses on queries that seek specific answers, rather than general informational searches.
It supports cross-device continuity, enabling a query on one device to be fulfilled later on another.
The design reduces repeated searches by eliminating the need for users to check back, then autonomously circling back when the information is available.
The practice of privacy-led user experience (UX) is a design philosophy that treats transparency around data collection and usage as an integral part of the customer relationship. An undertapped opportunity in digital marketing, privacy-led UX treats user consent not as a tick-box compliance exercise, but rather as the first overture in an ongoing customer relationship. For the companies that get it right, the payoff can bring something more intangible, valuable, and durable than simple consent rates: consumer trust.
The opportunities of privacy-led UX have only recently come into focus. Adelina Peltea, the chief marketing officer at Usercentrics, has seen enterprise sentiment shift: “Even just a few years ago, this space was viewed more as a trade-off between growth and compliance,” she says. “But as the market has matured, there’s been a greater focus on how to tie well-designed privacy experiences to business growth.”
And it turns out that well-designed, value-forward consent experiences routinely outperform initial estimates. Touchpoints for privacy-led UX often include consent management platforms, terms and conditions, privacy policies, data subject access request (DSAR) tools, and, increasingly, AI data use disclosures.
This report examines how data transparency builds trust with customers; how this, in turn, can support business performance; and how organizations can maintain this trust even as AI systems add complexity to consent processes.
Key findings include the following:
Privacy is evolving from a one-time consent transaction into an ongoing data relationship. Rather than asking users for broad permissions up front, leading organizations are introducing data-sharing decisions gradually, matching the depth of the ask to the stage of the customer relationship. Companies that take this tack tend to gather both a larger quantity and higher quality of consumer data, the value of which often compounds over time.
Privacy-led UX is a prerequisite for AI growth. The consumer data that organizations gather is rapidly becoming a core foundation upon which AI-powered personalization is built. Organizations that establish clear, enforceable privacy and data transparency policies now are better positioned to deploy AI responsibly and at scale in the future. This starts with correctly configured consent mode across ad platforms.
Agentic AI introduces new levels of both complexity and opportunity. As AI systems begin acting on users’ behalf, the traditional consent moment may never occur. Governing agent-generated data flows requires privacy infrastructure that goes well beyond the cookie banner.
Realizing the advantages of privacy-led UX requires cross-functional collaboration and clear leadership. Privacy-led UX touches marketing, product, legal, and data teams—but someone must own the strategy and weave the threads together. Chief marketing officers
(CMOs) are often best positioned for that role, given their visibility across brand, data, and customer experience.
A practical framework can support businesses in getting it right. Organizations must define their data collection and usage strategies and ensure their UX incorporates data consent, including a focus on banner design. Following a blueprint for evaluating and improving privacy-led UX supports consistency at every consent touchpoint.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
For four days in February 2019, some 30 synthetic biologists and ethicists hunkered down at a conference center in Northern Virginia to brainstorm high-risk, cutting-edge, irresistibly exciting ideas that the National Science Foundation should fund. By the end of the meeting, they’d landed on a compelling contender: making “mirror” bacteria. Should they come to be, the lab-created microbes would be structured and organized like ordinary bacteria, with one important exception: Key biological molecules like proteins, sugars, and lipids would be the mirror images of those found in nature. DNA, RNA, and many other components of living cells are chiral, which means they have a built-in rotational structure. Their mirrors would twist in the opposite direction.
Researchers thrilled at the prospect. “Everybody—everybody—thought this was cool,” says John Glass, a synthetic biologist at the J. Craig Venter Institute in La Jolla, California, who attended the 2019 workshop and is a pioneer in developing synthetic cells. It was “an incredibly difficult project that would tell us potentially new things about how to design and build cells, or about the origin of life on Earth.” The group saw enormous potential for medicine, too. Mirror microbes might be engineered as biological factories, producing mirror molecules that could form the basis for new kinds of drugs. In theory, such therapeutics could perform the same functions as their natural counterparts, but without triggering unwelcome immune responses.
After the meeting, the biologists recommended NSF funding for a handful of research groups to develop tools and carry out preliminary experiments, the beginnings of a path through the looking glass. The excitement was global. The National Natural Science Foundation of China funded major projects in mirror biology, as did the German Federal Ministry of Research, Technology, and Space.
By five years later, in 2024, many researchers involved in that NSF meeting had reversed course. They’d become convinced that in the worst of all possible futures, mirror organisms could trigger a catastrophic event threatening every form of life on Earth; they’d proliferate without predators and evade the immune defenses of people, plants, and animals.
“I wish that one sunny afternoon we were having coffee and we realized the world’s about to end, but that’s not what happened.”
Kate Adamala, synthetic biologist, University of Minnesota
Over the past two years, they’ve been ringing alarm bells. They published an article in Science in December 2024, accompanied by a 299-page technical report addressing feasibility and risks. They’ve written essays and convened panels and cofounded the Mirror Biology Dialogues Fund (MBDF), a broadly funded nonprofit charged with supporting work on understanding and addressing the risk. The issue has received a blaze of media attention and ignited dialogues among not only chemists and synthetic biologists but also bioethicists and policymakers.
What’s received less attention, however, is how we got here and what uncertainties still remain about any potential threat. Creating a mirror-life organism would be tremendously complicated and expensive. And although the scientific community is taking the alarm seriously, some scientists doubt whether it’s even possible to create a mirror organism anytime soon. “The hypothetical creation of mirror-image organisms lies far beyond the reach of present-day science,” says Ting Zhu, a molecular biologist at Westlake University, in China, whose lab focuses on synthesizing mirror-image peptides and other molecules. He and others have urged colleagues not to let speculation and anxiety guide decision-making and argued that it’s premature to call for a broad moratorium on early-stage research, which they say could have medical benefits.
But the researchers who are raising flags describe a pathway, even multiple pathways, to bringing mirror life into existence—and they say we urgently need guardrails to figure out what kinds of mirror-biology research might still be safe. That means they’re facing a question that others have encountered before, multiple times over the last several decades and with mixed results—one that doesn’t have a neat home in the scientific method. What should scientists do when they see the shadow of the end of the world in their own research?
Looking-glass life
The French chemist and microbiologist Louis Pasteur was the first to recognize that biological molecules had built-in handedness. In the late 19th century, he described all living species as “functions of cosmic asymmetry.” What would happen, he mused, if one could replace these chiral components with their mirror opposites?
Scientists now recognize that chirality is central to life itself, though no one knows why. In humans, 19 of the 20 so-called “standard” amino acids that make up proteins are chiral, and all in the same way. (The outlier, glycine, is symmetrical.) The functions of proteins are intricately tied to their shapes, and they mostly interact with other molecules through chiral structures. Almost all receptors on the surface of a cell are chiral. During an infection, the immune system’s sentinels use chirality to detect and bind to antigens—substances that trigger an immune response—and to start the process of building antibodies.
By the late 20th century, researchers had begun to explore the idea of reversing chirality. In 1992, one team reported having synthesized the first mirror-image protein. That, in turn, set off the first clarion call about the risk: In response to the discovery, chemists at Purdue University pointed out, briefly, that mirror-life organisms, if they escaped from a lab, would be immune to any attack by “normal” life. A 2010 story in Wiredhighlighting early findings in the area noted that if a such a microbe developed the ability to photosynthesize, it could obliterate life as we know it.
The synthetic biology community didn’t seriously weigh those threats then, says David Relman, a specialist who bridges infectious disease and microbiology at Stanford University and a trailblazer in studying the gut and oral microbiomes. The idea of a mirror microbe seemed too far beyond the actual progress on proteins. “This was almost a solely theoretical argument 20 years ago,” he says.
Now the research landscape has changed.
Scientists are quickly making progress on mirror images of the machinery cells use to make proteins and to self-replicate. Those components include DNA, which encodes the recipes for proteins; DNA polymerases, which help copy genetic material; and RNA, which carries recipes to ribosomes, the cell’s protein factories. If researchers could make self-replicating mirror ribosomes, then they would have an efficient way to produce mirror proteins. That could be used as a biological manufacturing method for therapeutics. But embedded in a self-replicating, metabolizing synthetic cell, all these pieces could give rise to a mirror microbe.
When synthetic biologists convened in Northern Virginia in 2019, they didn’t recognize how quickly the technology was advancing, and if they saw a threat at all, it may have been obscured by the blinding appeal of pushing the science forward. What’s become apparent now, says Glass, is that scientists in different disciplines, all related to mirror life, were largely unaware of what other scientists had been doing. Chemists didn’t know that synthetic biologists had made so much progress on creating mirror cells with natural chirality from scratch. Biologists didn’t appreciate that chemists were building ever-larger mirror macromolecules. “We tend to be siloed,” Glass says. And nobody, he says, had thought to seriously examine the immune system concerns that had already been raised in response to earlier work. “There was not an immunologist or an infectious disease person in the room,” Glass says, reflecting on the 2019 meeting. “I may have come closest, given that I work with pathogenic bacteria and viruses,” he adds, but his work doesn’t address how they cause infections in their hosts.
GETTY IMAGES
These scientists also didn’t know that around the same time as their meeting, another conversation about mirror life was happening—a darker dialogue that was as focused on danger as it was on discovery. Starting around 2016, researchers with a nonprofit called Open Philanthropy had begun compiling research files on catastrophic biological risks. The organization, which rebranded as Coefficient Giving in 2025, funds projects across a range of focus areas; it adheres to a divisive philanthropic philosophy called effective altruism, which advocates giving money to projects with the highest potential benefit to the most people. While that might not sound objectionable, critics point out that the metrics devotees use to gauge “effectiveness” can prioritize long-term solutions while neglecting social injustices or systemic problems.
Someone in Open Philanthropy’s biosecurity group had suggested looking into the risks posed by mirror life. In 2019 the organization began funding research by Kevin Esvelt, who leads the Sculpting Evolution group at the MIT Media Lab, on biosecurity issues, including mirror life. He began reading up to see whether mirror life was something to worry about.
Esvelt made waves in 2013 for pioneering the use of CRISPR to develop a gene drive, a technology that could spread genetic changes introduced into a living organism through a whole population. Researchers are exploring its use, for example, to make mosquitoes hostile to the parasite that causes malaria—and, as a result, lower their chance of spreading it to humans. But almost immediately after he developed the tool, Esvelt argued against using it for profit, at least until proper safeguards could be set and its use in fighting malaria had been established. “Do you really have the right to run an experiment where if you screw up, it affects the whole world?” he asked, in this magazine, in 2016. At the Media Lab, Esvelt leads efforts to safely develop gene drives that can be deployed locally but prevented from spreading globally.
Esvelt says he’s often thinking about the security risks posed by self-sustaining genetically engineered technologies, and research led him to suspect that the threat of mirror organisms hadn’t been seriously interrogated. The more he learned about microbial growth rates, predator-prey and microbe-microbe interactions, and immunology, the more he began to worry that mirror organisms, if impervious to the innate defenses of natural ones, could cause unstoppable infections in the event that they escaped the lab.
Even if the first experimental iteration of such a germ were too fragile to survive in the environment or a human body, Esvelt says, it would be a light lift to genetically engineer new, more resilient versions with existing technology. Even worse, he says, the results could be weaponized. The possible path from 2019 to global annihilation seemed almost too direct, he found.
But he wasn’t an expert in all the scientific fields involved in research on mirror life, so he started making calls. He first described his concerns to Relman one night in February 2022, at a restaurant outside Washington, DC. Esvelt hoped Relman would tell him he was wrong, that he’d missed something over the years of gathering data. Instead, he was troubled.
The concern spreads
When Relman returned to California, he read more about the technology, the risks, and the role of chirality in the immune system and the environment. And he consulted experts he knew well—ecologists, other microbiologists, immunologists, all of them leaders in their fields—in an attempt to assuage his concerns. “I was hoping that they’d be able to say, I’ve thought about this, and I see a problem with your logic. I see that it’s really not so bad,” he says. “At every turn, that did not happen. Something about it was new to every person.”
The concern spread. Relman worked with Jack Szostak, a professor of chemistry at the University of Chicago, and a group of researchers to see if it was possible to make an argument that mirror life wasn’t going to wipe out humanity. Included in that group was Kate Adamala, a synthetic biologist at the University of Minnesota. She was a natural choice: Adamala had shared the initial grant from the NSF, in 2019, to explore mirror-life technologies.
She also became convinced the risk was real—and was dumbfounded that she hadn’t seen it earlier. “I wish that one sunny afternoon we were having coffee and we realized the world’s about to end, but that’s not what happened,” she says. “I’m embarrassed to admit that I wasn’t even the one that brought up the risks first.” Through late 2023 and early 2024, the endeavor began to take on the form of a rigorous scientific investigation. Experts were presented with a hypothesis—namely, that if mirror cells were built, they would pose an existential threat—and asked to challenge it. The goal was to falsify the hypothesis. “It would be great if we were wrong,” says Vaughn Cooper, a microbiologist at the University of Pittsburgh and president-elect of the American Society for Microbiology.
Relman says that as the chemists and biologists learned more about one another’s work and began to understand what immunologists know about how living things defend themselves, they started to connect the dots and see an emerging picture of an unstoppable synthetic threat.
Some scientists have pushed back against the doomsday scenario, suggesting that the case against mirror life offers an “inflated view of the danger.”
Timothy Hand, an immunologist at the University of Pittsburgh who hadn’t participated in the 2019 NSF meeting, wasn’t initially worried when he heard about mirror life, in 2024. “The mammalian immune system has this incredible capability to make antibodies against any shape,” he says. “Who cares if it’s a mirror?” But when he took a closer look at that process, he could see a cascade of potential problems far upstream of antibody production. Start with detection: Macrophages, which are cells the immune system uses to identify and dispatch invaders, use chiral sensing receptors on their surfaces. The proteins they use to grab on to those invaders, too, are chiral. That suggests the possibility that an organism could be infected with a mirror organism but not be able to detect it or defend against it. “The lack of innate immune sensing is an incredibly dangerous circumstance for the host,” Hand says.
By early 2024, Glass had become concerned as well. Relman and James Wagstaff, a structural biologist from Open Philanthropy, visited him at the Venter Institute to talk about the possibility of using synthetic cell technology—Glass’s specialty—to build mirror life. “At first I thought, This can’t be real,” Glass says. They walked through arguments and counterarguments. “The more this went on, the more I started feeling ill,” he says. “It made me realize that work I had been doing for much of the last 20 years could be setting the world up for this incredible catastrophe.”
In the second half of 2024, the growing group of scientists assembled the report and wrote the policy forum for Science. Relman briefed policymakers at the White House and members of the national security community. Researchers met with the National Institutes of Health and the National Science Foundation. “We briefed the United Nations, the UK government, the government of Singapore, scientific funding organizations from Brazil,” says Glass. “We’ve talked to the Chinese government indirectly. We were trying to not blindside anybody.”
A year and a half on, the push has had an impact. UNESCO has recommended a precautionary global moratorium on creating mirror-life cells, and major philanthropic organizations that fund science, including the Alfred P. Sloan Foundation, have announced they will not finance research leading to a mirror microorganism. The Bulletin of the Atomic Scientists highlighted considerations about mirror life in its most recent report on the Doomsday Clock. In March, the United Nations Secretary-General’s Scientific Advisory Board issued a brief highlighting the risks—noting, for example, that recent progress on building mirror molecules could reduce the cost of creating a mirror microbe.
“I think no one really believes at this stage that we should make mirror life, based on the evidence that’s available,” says James Smith, the scientist who leads the MBDF, the nonprofit focused on assessing the risks of mirror life, which is funded by Coefficient Giving, the Sloan Foundation, and other organizations. The challenge now, Smith says, is for scientists to work with policymakers and bioethicists to figure out how much research on mirror life should be permitted—and who will enforce the rules.
Drawing the line
Not everyone is convinced that mirror organisms pose an existential threat. It’s difficult to verify predictions about how mirror microbes would fare in the immune system—or the larger world—without running experiments on them. Some scientists have pushed back against the doomsday scenario, suggesting that the case against mirror life offers an “inflated view of the danger.” Others have noted that carbohydrates called glycans already exist in both left- and right-handed forms—even in pathogens—and the immune system can recognize both of them. Experiments focused on interactions between the immune system and mirror molecules, they say, could help clarify the risks of mirror organisms and reduce uncertainty.
Even among those convinced that the worst-case scenario is possible, researchers still disagree over where to draw the line. What inquiries should be allowed and what should be prohibited?
Andy Ellington, a biotechnologist and synthetic biologist at the University of Texas at Austin, doesn’t think mirror organisms will come to fruition anytime soon. Even if they do, he isn’t sure they will pose a threat. “If there is going to be harm done to the human race, this is about position 382 on my list,” he says. But at the same time, he says it’s a complicated issue worth studying more, and he wants to see the conversations continue: “We’re operating in a space where there’s so much unknown that it’s very difficult for us to do risk assessment.”
Even among those convinced that the worst-case scenario is possible, researchers still disagree over where to draw the line. What inquiries should be allowed and what should be prohibited?
Adamala, of the University of Minnesota, and others see a natural line at ribosomes, the cellular factories that transform chains of amino acids into proteins. These would be a critical ingredient in creating a self-replicating organism, and Adamala says the path to getting there once mirror ribosomes are in place would be pretty straightforward. But Zhu, at Westlake, and others counter that it’s worth developing mirror ribosomes because they could possibly produce medically useful peptides and proteins more efficiently than traditional chemical methods. He sees a clear distinction, and a foundational gap, between that kind of technology and the creation of a living synthetic organism. “It is crucial to distinguish mirror-image molecular biology from mirror-image life,” he says. That said, he points out that many synthetic molecules and organisms containing unnatural components, including but not limited to the mirror-image subset, might pose health risks. Researchers, he says, should focus on developing holistic guidelines to cover such risks—not just those from mirror molecules.
Even if the exact risk remains uncertain, Esvelt remains more convinced than ever that the work should be paused, perhaps indefinitely. No one has taken a meaningful swing at the hypothesis that mirror life could wipe out everything, he says. The primary uncertainties aren’t around whether mirror life is dangerous, he points out; they have more to do with identifying which bacterium—including what genes it encodes, what it eats, how it evades the immune system’s sentinels—could lead to the most serious consequences. “The risk of losing everything, like the entire future of humanity integrated over time, is not worth any small fraction of the economy. You just don’t muck around with existential risk like that,” he says.
In some ways, scientists have been here before, working out rules and limits for research. Two years after the start of the covid-19 pandemic, for example, the World Health Organization published guidelines for managing risks in biological research. But the history is much deeper: Horrific episodes of human experimentation led to the establishment of institutional review boards to provide ethical oversight. In the early 1970s, in response to concerns over lab-acquired infections and growing use of biological warfare, the US Centers for Disease Control and Prevention established biohazard safety levels (BSLs), which govern work on potentially dangerous biological experiments.
And in 1975—at the dawn of recombinant DNA research, which allows researchers to put genetic material from one organism into another—geneticists met at the Asilomar conference center in Pacific Grove, California, to hammer out rules governing the work. There were concerns over what would happen if some virus or bacterium, genetically engineered to have traits that would make it particularly dangerous for people, escaped from a lab. Scientists agreed to self-imposed restrictions, like a moratorium on research until new safety guidelines were in place. As a result of the meeting, in June 1976 the NIH issued rules that, among other things, categorized the risks associated with rDNA experiments and aligned them with the newly adopted BSL system.
Asilomar is often hailed as a successful model for scientific self-governance. But that perception reflects a tendency to recall the meeting through a nostalgic haze. “In fact, it was incredibly messy and human,” says Luis Campos, a historian of science at Rice University. Equally brilliant Nobelists argued on either side of the question of whether to rein in rDNA research. Technical discussions dominated; talks about who would be affected by the technology were missing. The meeting didn’t start establishing guidelines, says Campos, until the lawyers mentioned liability and lab leaks.
For now it’s unclear whether these examples of self-governance, which arose from the demonstrated risks of existing technologies, hold useful lessons for the mirror-life community. Three competing images of the future are coming into focus: Mirror life might not be possible, it might be possible but not threatening, or it might be possible and capable of obliterating all life on Earth.
Scientists may be censoring themselves out of fear and speculation. To some, shutting down the work seems necessary and urgent; to others, it is unnecessarily limiting. What’s clear is that the question of what to do about mirror life has been both illuminating and disorienting, pushing scientists to interrogate not only their current research but where it might lead. This is uncharted territory.
Stephen Ornes is a science writer based in Nashville, Tennessee.
Correction (April 15): An earlier version of this article incorrectly stated that David Relman briefed the National Security Agency. Relman says he briefed members of the national security community.
A growing black market: Scammers are buying tools advertised on Telegram that trick banks’ facial recognition checks, letting them access accounts using photos, deepfakes, or virtual cameras instead of live video.
The stakes are enormous: Crypto scams stole an estimated $17 billion in 2025 alone, and virtual-camera attacks were 25 times more common in 2024 than the year before.
Banks are aware, but holes remain: Major institutions like Binance, BBVA, and Revolut acknowledge the problem but won’t confirm its scale. Experts warn that the most successful attacks may never be detected at all.
Regulators are scrambling to keep up: New laws in Thailand and warnings from US financial regulators signal growing pressure on the industry, but researchers say determined scammers will keep adapting.
From inside a money-laundering center in Cambodia, an employee opens a popular Vietnamese banking app on his phone. The app asks him to upload a photo associated with the account, so he clicks on a picture of a 30-something Asian man.
Next, the app requests to open the camera for a video “liveness” check. The scammer holds up a static image of a woman bearing no resemblance to the man who owns the account. After a 90-second wait—as the app tells him to readjust the face inside the frame—he’s in.
The exploit he’s demonstrating, in a video shared with me by a cyberscam researcher named Hieu Minh Ngo, is possible thanks to one of a growing range of illicit hacking services, readily available for purchase on Telegram, that are designed to break “Know Your Customer” (KYC) facial scans.
These banking and crypto safeguardsare supposed to confirm that an account belongs to a real person, and that the user’s face matches the identity documents that were provided to open the account. But scammers are bypassing them in order to open mule accounts and launder money. Rather than using a live phone camera feed for a liveness check, the hacks typically deploy a tool known as a virtual camera. Users can replace the video stream with other videos or photos—depicting a real or deepfake person or even an object.
As financial institutions enact enhanced security measures aimed at stopping cyberscammers, these workarounds are the latest round in the cat-and-mouse game between criminal operators and the financial services industry.
Over the course of a two-month investigation earlier this year, MIT Technology Review identified 22 Chinese-, Vietnamese-, and English-language public Telegram channels and groups advertising bypass kits and stolen biometric data. The software kits use a variety of methods to compromise phone operating systems and banking applications, claiming to enable users to get around the compliance checks imposed by financial institutions ranging from major crypto exchanges such as Binance to name-brand banks like Spain’s BBVA.
“Specializing in bank services—handling dirty money,” reads the since-deleted Telegram bio of the program used by the Cambodian launderer, complete with a thumbs-up emoji. “Secure. Professional. High quality.” Some of the channels and groups had thousands of subscribers or members, and many posted bullet points listing their services (“All kinds of KYC verification services”; “It’s all smooth and seamless”) alongside videos purporting to show successful hacks.
Telegram says that after reviewing the accounts, it removed them for violating its terms of service. But such online marketplaces proliferate easily, and multiple channels and groups advertising similar tools remain active.
Banks and butchers
The rise in KYC bypasses has occurred alongside an expansion of a global industry in “pig-butchering” cyberscams. Crypto platforms and banks around the world are facing increasing scrutiny over the flow of illegally obtained money, including profits from such scams, through their platforms. This has prompted tightened banking regulations in countries such as Vietnam and Thailand, where governments have increased customer verification and fraud monitoring requirements and are pushing for stronger anti-money-laundering safeguards in the crypto industry.
Chainalysis, a US blockchain analysis firm, estimates that around $17 billion was stolen in 2025 in crypto scams and fraud, up from $13 billion in 2024. The United Nations Office on Drugs and Crime, meanwhile, warned in a recent report that the expansion of Asian scam syndicates in Africa and the Pacific has helped the industry “dramatically scale up profits.”
That combination of factors—more scrutiny, but also more revenue—has vaulted KYC bypasses to the center of the online marketplace for cyberscam and casino money launderers. Although estimates vary, cybersecurity researchers say these kinds of attacks are rising: The biometrics verification company iProov estimated that virtual-camera attacks were more than 25 times as common worldwide 2024 than in 2023, while Sumsub, a company providing KYC services, reported that “sophisticated” or multi-step fraud attempts, including virtual-camera bypasses, almost tripled last year among its clients.
Three financial institutions that were named as targets on such Telegram channels—the world’s largest crypto exchange, Binance, as well as BBVA and UK-based Revolut—told me they’re aware of such bypasses and emphasize that they’re an industry-wide challenge. A spokesperson from Binance said it has “observed attempts of this nature to circumvent our controls,” adding that “we have successfully prevented such attacks and remain confident in our systems.” BBVA and Revolut also declined to comment on whether their safeguards had been breached.
It’s difficult to estimate success rates, because companies may not be aware of bypasses—or report them—until later. “What’s important is what we don’t see,” Artem Popov, Sumsub’s head of fraud prevention products, told me, referring to attacks that go undetected. “There’s always part of the story where it might be completely hidden from our eyes, and from the eyes of any company in the industry, using any type of KYC provider.”
How criminals navigate a compliance maze
Advertisements for the exploits appear simple enough, but on the back end, building a successful bypass is complex and often involves multiple methods. Some channels offer to jailbreak a physical phone so that scammers can trigger the use of a virtual camera (VCam) instead of the built-in one whenever they’d like. Other hacks inject code known as a “hooking framework” into a financial institution’s app that triggers the VCam to open. Either way, VCams can be used to dupe KYC safeguards with images or videos that replace genuine, live video of the account’s owner.
Sergiy Yakymchuk, CEO of Talsec, a cybersecurity company that primarily serves financial institutions, reviewed details from the Telegram channels identified by MIT Technology Review and says they are consistent with successful tactics used against his banking and crypto clients. His team received help requests from banks and exchanges for roughly 30 VCam-based hacks over the past year, up from fewer than 10 in 2023.
Increasingly, hackers compromise both the phone itself and the code of the financial institutions’ apps before feeding the virtual camera a mix of stolen biometrics and deepfakes, Yakymchuk says.
“Some time ago, it was enough to decompile the app of a bank and distribute this on Telegram, and that was everything you needed,” he says. “Now it’s not enough, because you have KYC—and more and more things are needed.”
For money launderers,KYC bypasses have “become essential for everything right now—because scam compounds need to move money,” says Ngo, the researcher who shared the demo video. A convicted former hacker who became a cybersecurity advisor for the Vietnamese government, Ngo now runs an anti-scam nonprofit and helps law enforcement investigate money laundering.
He describes how the process works in the case of pig-butchering scams: Funds originating with victims are received into bank accounts controlled or rented by a money-laundering network, known colloquially as “water houses.” Money launderers use KYC bypasses to access the accounts and quickly redistribute the profits before converting them into digital assets—typically in the form of the stablecoin Tether, a type of cryptocurrency that is pegged to the US dollar.
These transactions often happen in seconds, under tightly orchestrated management. “They know, very clearly, the flow of how the banks verify or authenticate accounts,” Ngo says.
A cat-and-mouse game
The growth of cyberscam money laundering has led to heightened scrutiny of financial institutions. In 2023, Binance pleaded guilty in US federal courts to operating without anti-money-laundering safeguards. Donald Trump pardoned former Binance CEO Chaopeng Zhao last October.
Recent analysis from the International Consortium of Investigative Journalists found that after Zhao’s guilty plea, more than $400 million continued to move to Binance from Huione Group, a Cambodia-based firmthat the US sanctioned after the Treasury Department deemed it a “critical node” for money laundering in pig-butchering scams.
Binance says it has “state-of-the-art security systems” that prevented billions in fraud losses and that the company processed more than 71,000 law enforcement requests in 2025.
But John Griffin, a finance and blockchain expert at the University of Texas at Austin, does not think the exchanges are sufficiently secure. “Even though they have all this press about ‘Oh, yes, we’ve changed this and that’—well, the proof is in the pudding. The criminals are still using your exchange,” Griffin told me of the industry at large. “So there must be holes.” (Binance says it “objects to the dubious findings” of Griffin’s work tracking the flow of criminal profits across exchanges like Binance, Huobi, OKX, and Tokenlon, calling it “misleading at best and, at worst, wildly inaccurate.”)
Binance also pointed out that some purported bypass services are themselves scams, casting doubt on whether successful bypasses are as widespread as the Telegram marketplace may suggest. Engaging with such services “exposes individuals to significant security risks,” a spokesperson said. “Even where access appears to be granted, accounts are often already restricted by internal detection and compliance controls, rendering them nonfunctional for trading or withdrawals.”
Regulators around the world are trying to catch up. In Thailand, where citizens’ bank accounts regularly serve as money mules for cyberscams based in neighboring Myanmar and Cambodia, new legislation has enhanced KYC monitoring, limited daily transactions, and strengthened oversight bodies’ ability to suspend accounts. The US money-laundering regulator, the Financial Crimes Enforcement Network, issued a warning against KYC deepfakes and the use of VCams in late 2024, encouraging platforms to track broader transaction patterns to identify money laundering.
For scammers, any new security or reporting requirements will make bypasses harder, but “it’s not going to stop them,” Ngo says. “It’s just a matter of time.”