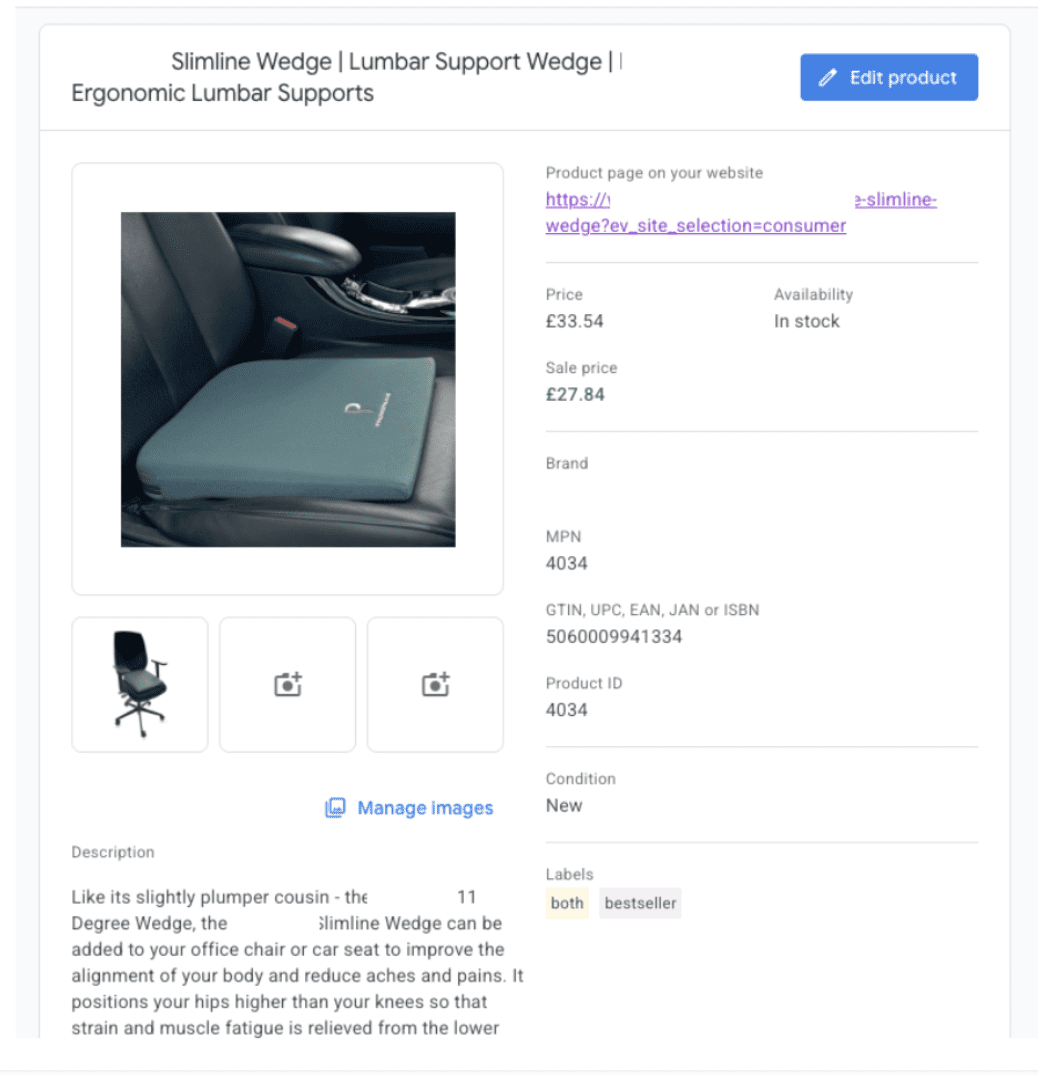
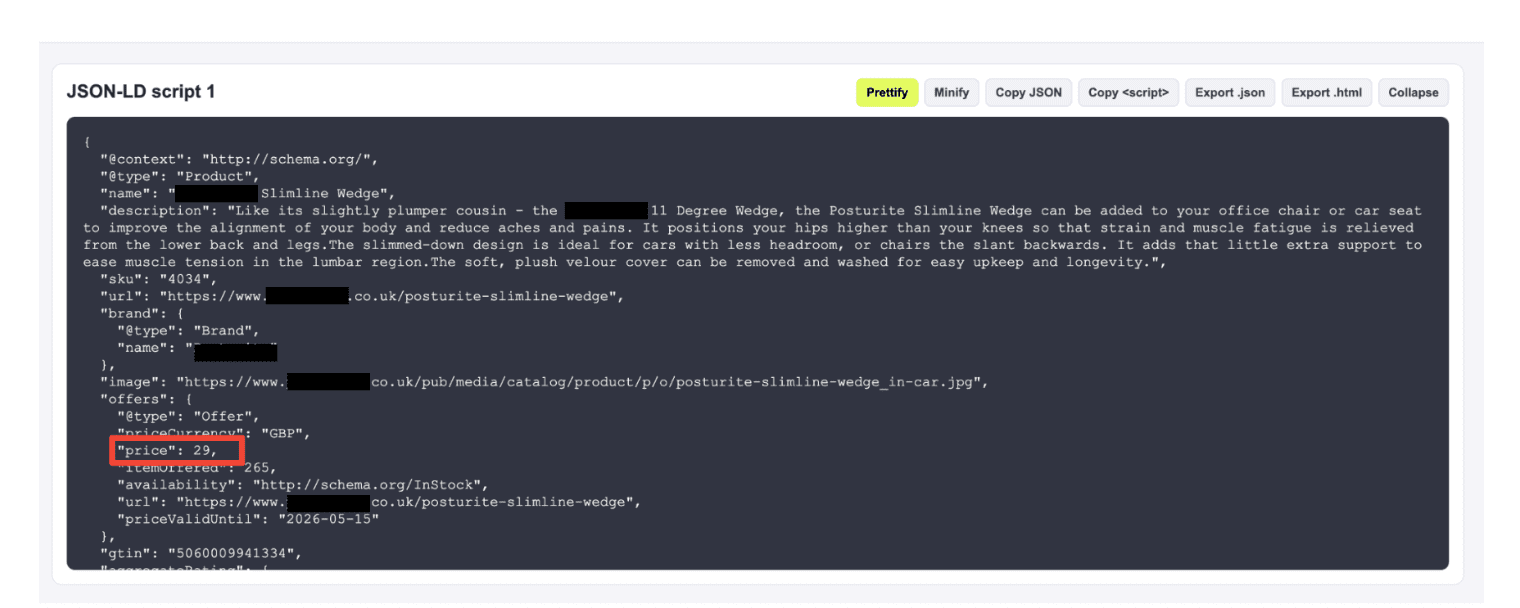
What The Future Of Google Looks Like
Busy week in search-land.
So Google finally rolled out some kind of AI reporting (if you can call that reporting), and the Competition and Markets Authority (CMA) announced some new measures Google must take to restore some level of parity with publishers and search results.

“Conduct requirement introduced today gives publishers more control and stronger bargaining power over the use of their content…”
CMA
This is, in fairness, a world-first. Clearly a step in the right direction. But that’s all it is, a step.
We have AI reporting without clicks for, I presume, obvious reasons. Publishers can opt out of AI Overviews – a nice-to-have – but unless this is done at scale, there’s very little bargaining power here, and the onus is on publishers. Although I will say allowing publishers to opt out of their content being used for the “fine-tuning” of AI models is, obviously, a good thing.
Oh, and Search profiles launched “to help publishers and creators highlight their work on Search.” This might seem small, but it’s a huge part of the future of search. It’s why I don’t hate the “search everywhere optimization” moniker. Search is broader than ever.
“Search profiles give publishers and creators a central place to showcase their latest articles, videos and social posts. People can easily follow sources from their profile, so they’re more likely to see that content on Discover…”
LLMs have restructured the open web. Your way of accessing and retrieving information has fundamentally shifted. Entity SEO – the connections you can build around your brand (personal and professional) – is more important than ever. You cannot afford ambiguity anymore. You have to build a profile. With real people. In multiple places.
Positive first steps. There are many to go.
Financially, How Are They Doing?
Errr … pretty well.
Total revenue for 2025 came in at $402.8 billion, up from $350 billion in 2024 – the first $400 billion year in Google’s history. Larger than the GDP of Portugal. The company also delivered its first-ever $100 billion quarter in Q3.

A more robust view of their annual reports shows a few things.
- Google Search & other – $224.5 billiob (+13.4%).
- Google Subscriptions, Platforms & Devices – $48.0 billion (+19.1%).
- Google Cloud – $58.7 billion (+35.8%).
- YouTube’s annual revenue surpasses $60 billion.

Search is still Google’s largest revenue line by some margin. A rise in zero-click searches, keeping people in its system, is clearly a good thing for its advertising business model. Thanks to data from Seer Interactive, we know that AIOs caused the CTR (and cost) of PPC advertising to respectively decline and increase over this time. Albeit this appears to have leveled out.
Cloud revenues jumped from $43.2 billion to $58.7 billion, primarily driven by growth in infrastructure and platform services. Google Cloud ended 2025 at an annual run rate of over $70 billion, with demand driven by AI products, and nearly 75% of Google Cloud customers had used Google’s vertically optimized AI.
YouTube’s dual revenue model may be Google’s plan for search. Its advertising revenue grew from $36.1 billion to $40.4 billion last year, and subscriptions give it unparalleled resilience. Unlike Search, YouTube’s creator economy is still booming.
It’s a product that works on both fronts.
Finally, and most importantly in my opinion, Google’s subscription-based products are its fastest-growing non-cloud segment. Consumer subscriptions exceeded 325 million across Google’s services, thanks to Google One and YouTube Premium adoption. This is a parallel revenue line for Google – one where advertising matters less.
The open web becomes less important as an intermediary because of it. It enhances their ability to lose money on advertising. They are building resilience.
Google also has a sneaky line item in its 10-K in the OI&E section (Other Income and Securities) labeled as non-marketable equity securities. Google has invested $3 billion in Anthropic up until this point and has $24.1 billion of unrealized gains over the same time period.
As a private company investment, fair to say this kind of circular investing is purposefully difficult to quantify. Google has now committed to investing $40 billion in Anthropic.
Will AI Mode Become The Default?
I suspect AI Mode becomes the default search experience for most people and a significant number of searches. People like the conversational interface, and once they figure out advertising and reduce the cost of running it, I’m sure it will get rolled out more aggressively.
Thanks to data shared by Aleyda Solis (and Rand Fishkin), we know AI Mode’s usage more than doubled in the U.S. in a single quarter. In Europe, it grew even faster. Overall share remains below 0.25% in both regions. The pessimist in me thinks that’s a bit crap. The optimist would say there’s room for growth.
- In the U.S., Google AI Mode’s share of desktop events grew from 0.06% in December 2025 to 0.16% in March 2026. A 2.5x increase in one quarter.
- In the EU and UK, growth was sharper: 0.06% in December to 0.21% in March, nearly a 4x increase over the same period.
- By March 2026, EU and UK adoption had overtaken the U.S. (0.21% vs 0.16%), despite AI Mode launching later in Europe.
Sundar is bullish on the topic. He claims Google is creating a seamless transition from 10 blue links towards AI Mode, and people are enjoying it. But it’s not an overnight change. You aren’t going to flick the switch on a 200+ billion advertising model when the alternative is so untested.
Particularly when your competitors are financially floundering somewhat, beautifully described by Gary Marcus as tokenmaxxing. The immediate risk is somewhat lessened.
And worth remembering that 44% of Google searches are navigational. Is that a strong proposition for AI and far more computationally expensive conversational search?
Maybe. Maybe not.
We’ve seen a notable uptick in AI Overviews appearing for branded searches, and research from Kevin Indig showed that people are, in many cases, just looking for top-of-the-funnel information at this stage in their journey. And we don’t want to click on websites.
So the navigational click is being replaced by an in-SERP navigational assessment. If Google can fulfill your need in their SERP, you can bet your bottom dollar they will.
Absolutely worth watching David’s explainer video on the future of the value exchange and how to understand the value of your content in Google’s eyes and your own. This is foundational for publishers moving forward.
Why AI Mode Might Not Be The Default Experience
Hugging Face estimated it costs about 30 times as much energy to generate text versus simply extracting it from a source. While that isn’t revenue as such, computational power correlates pretty closely with cost.
Right now, AI offerings are computationally expensive, much less monetizable (although I’m sure that will change), and won’t be picked up by great swathes of the population.
If you had a more expensive product that specific people or cohorts of people weren’t using (and are unlikely to use), would you push them into using it? Or would you just primarily give them what they’re used to? Could that group’s margin support your expensive expansion?
If you’re familiar with the stages of technology adoption, you get a sense of who adopts it, when, and why.
Innovators and early adopters are far likelier to be younger. People whose brains have enough plasticity to continue to change. In AI Mode’s case, I suspect those in the conservatives and skeptics sections will never use any kind of LLM.
If you don’t believe me, ask your parents what ChatGPT is. If they do use it, I’m fairly confident it’ll be for something either completely banal or psychologically worrying.
Google’s ability to understand the intent behind the search (and the user) will form a key part of the search giant’s revenue modelling. The more effectively they can do this, the less computational power they will spend.
Why News Holds Firm
AI Overviews do not supersede a Top Stories block. There are two theories here:
- Google has decided to create a safe haven for publishers (highly unlikely).
- AI cannot accurately or fairly represent fast-moving, immediate stories effectively (no one has cared about accuracy so far).
So, news, for now, is resilient to AI. It is filed under the type of content that still adds real and obvious value. Tools, products, real, human interest stories, stories with unique data and research that cannot be effectively delivered by an LLM, and real, expert-led opinion from people we trust.
Whisper it quietly, you might even get a click from it.
To show Top Stories resilience, I ran a couple of thousand queries, pretty newsy queries through DataforSEO, extracted the structured data, and represented it in a column graph of queries by category with an AI Overview or Top Stories. This is a tiny sample size, but it’s representative of larger ones I have seen and run.

- Branded queries had the lowest number of AIOs, albeit there were only 50 branded queries in the mix.
- News/entity type queries (primarily people, places, and organizations) had the second lowest number of AIOs, with just 19%, with 34% served by a Top Stories box.
- Informational queries have the highest percentage of AIOs.
Typically, this is when queries like [China Venezuela] can be well served with an AIO – because there’s significant evergreen search volume, or the news story has died down and can be effectively synthesized via an AI response.
If you want to truly run some quality risk and exposure mapping, I find it helpful to create category risk scores by entity type. You can expand this to content categorization too.

On the rare occasion that you see these beasts co-exist in the wild, I believe it only occurs when the news agenda for said topic has dropped off enough that an AIO can replace it.
Google Discover’s Competitive Advantage
We have a pretty good idea about how Google Discover works.
One of its strongest capabilities is the cohort-driven story rollout.
- Person A is similar to person B.
- Person A loved and engaged with said story.
- Said story is shown to person B.
- Person C also shares a similar characteristic and is shown the story.
People are classified based on what they like. Google builds groups. These groups form the foundations of virality.
Like almost any social media algorithm, Google Discover is Google’s way of hooking people into search with an algorithmic feed. And I think it could have significant potential for the future of the SERP.
When the time’s right, you will be shown incidental content you didn’t even know you wanted to read. And you will click it.
So What Does This Mean For The State Of The SERP?
Diversity. Zero-click search is overblown, albeit I think zero-click marketing is the present and future. Whether the public discourse about AI is the long-term projection of it or not, not everybody blindly trusts LLM responses. They trust people and want to make their own decisions.
AI is just part of the journey. Maybe more precisely, it summarises it in its entirety.
Younger audiences use publisher websites differently. It’s less about browsing the whataboutery of the day and more about validating nonsense they’ve seen on the slop-filled internet. Even Google isn’t immune – younger audiences are less engaged with the platform.
In some ways, Google has been forced into making a change.
Google’s ability to show each user the most appropriate SERP will have a significant impact on its bottom line. Local comparison results like the below – [best hotels in London] – have been tough for publishers for a long time. AI or not.

To me, it’s interesting there’s no AI experience here. Because this middle of the funnel comparison query is ripe for a longer, more conversational search. So I don’t think all is as brazen as it seems. Money still matters.
If you have followed the SGE for some time, this has always been the likely outcome. Or at least the final iteration, to the best of our knowledge. A results page that encompasses:
- Deep personalization.
- AI-powered snapshots.
- Shopping.
- Map packs.
- PAA sections.
- Discover like “we think you’ll like” article cards.
- Reviews and trust-like content from forums.
- Top Stories.
- Traditional 10 blue links.
In my opinion, these will all form a part of most SERPs. News-driven searches will continue to have a Top Stories block (unless AI is capable of dealing with real-time content – make sure you understand RAG in this context). Comparison-related searches will have a rich, AI-led experience, interspersed with review-type content from brands and forums. Local searches will lead directly to map packs, and longer, more conversational queries will take you straight to AI Mode.
What you choose to create all comes down to value. Value doesn’t have to mean revenue in the form of sales, subscriptions, or advertising. It could lead to newsletter signups, internal link clicks that you know lead to greater audience retention, improved visibility in AI systems.
You just need to have the right KPIs in place for a zero-click world. I’m sure you don’t want your success to be tied to metrics that will inevitably go down. If you want to influence senior figures and newsrooms, you need a sure footing.
A Subscription-Led Model May Be The Future
Worth noting, the financial success of Google’s other products is subscription-led. Subscription revenue is more valuable to a business than most others – it is predictable, measurable, and consistent.
It’s very plausible that Google bundles AI Mode and several other AI-led products into a single subscription. Tokens are becoming more expensive. The ad model may never work for AI Mode, and a hybrid advertising/subscription model may be their best route forward.
Which, IMO, may not be a bad thing.
More Resources:
Read Leadership In SEO. Subscribe now.
Featured Image: Master1305/Shutterstock